论文分享 |《DeepCluster》
聚类(Cluster) 是一种经典的无监督学习方法,但是鲜有工作将其与深度学习结合。这篇文章提出了一种新的聚类方法DeepCluster,将端到端学习与聚类结合起来,同时学习网络的参数和对网络输出的特征进行聚类。作者将DeepCluster成功应用到大规模数据集和一些迁移任务上,性能超过了当前state of art的无监督工作。表明结合简单的聚类算法,无监督方式也可以学习到很好的特征。
背景
预训练的卷积模型在各类任务中都发挥了极大的作用,比如目标检测、语义分割,这些预训练模型提取了一些很好通用的特征,可以应用于不同的任务上。在这个过程中ImageNet起到了很好的助推,虽然ImageNet含有100万+的图片,但是在实际中这个数量还是很小的,并且ImageNet的多样性不够。如何去处理更大规模的无标签数据,需要一种有效无监督学习的方法。
Method
框架
本文提出了一种将聚类与深度结合的方法,这种方法可以学习到一些有用的通用特征,这个框架如下图所示,整个过程包含对特征进行聚类,然后基于聚类的结果作为伪标签,更新网络的参数,让网络预测这些伪标签,这两个过程依次进行。这个过程看起来很简单,但能够取得比以往无监督方法更好的性能。

用数学公式表达整个过程就是下面两个公式。第一个公式就是通过聚类产生伪标签,第二个公式是计算基于伪标签的损失值,然后更新网络参数。
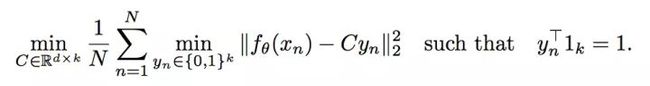

避免平凡解
上述交替聚类和模型更新这种方式容易使网络找到一些取巧的方式,从而得到一些无意义的结果。
Empty clusters
具体来讲,使用模型来预测伪标签,可能使得网络产生的特征经过聚类都位于某个簇心周围,而使得其他簇心没有样本,这个问题是由于没有限制某个簇心不能没有样本。一个解决方法是限制每个簇心最少的样本数,这需要计算整个数据集,代价太高;另一种方式是当某个簇心为空时,随机选择一个非空的簇心,在其上加一些小的扰动作为新的簇心,同时让属于非空簇心的样本也属于新的簇心。
Trivial parametrization
另外一个问题是大量的数据被聚类到少量的几类上,一种极端场景是被聚类到一类上,这种情况下网络可能对于任意的输入都产生相同的输出。解决这个问题的方法是根据类别(或伪标签)对样本进行均匀采样。
实现细节
结构:AlexNet,使用BN代替LRN;VGG16+BN。
训练数据:ImageNet;数据使用了一个基于Sobel的算子进行处理去除了颜色信息
优化:聚类的时候使用center crop的样本特征,训练模型时使用数据增强(左右翻转、随机大小和长宽比的裁剪),其他训练都是常见的配置。另外聚类时使用了PCA降维到256维。
实验
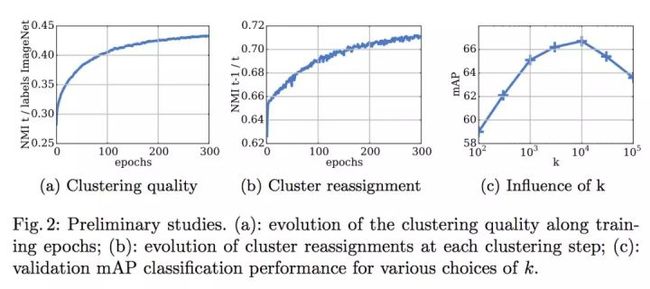
Preliminary study
实验部分首先来看随着训练过程的进行DeepCluster的一些变化。这里采用NMI(Normalized Mutual Information)来度量两个随机变量的相互依赖性。比如当两个随机变量完全独立,直到其中一个对推断另一个不提供任何信息,NMI值也为0。
下面来看簇心与图片真实标签(Fig 2(a))的关系,从Fig 2(a)可以看出簇心与label之间的依赖程度随着训练过程越来越高,表明特征逐渐地包含了图片类别的信息。
再来看第t-1epoch的簇心与第t epoch的簇心的关系(Fig 2(b)),从Fig 2(b)可以看出NMI在逐渐升高,表明簇心逐渐趋于稳定。但是最后NMI饱和值小于0.8,表明每个epoch都有一批样本在频繁的变换归属的簇心。
最后看一下选择不同的K对精度的影响(Fig 2(c)).
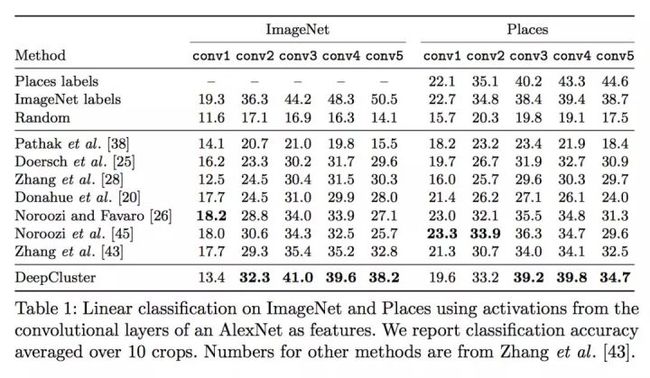
基于激活值的线性分类
使用不同的卷积层特征训练一个线性分类器,在ImageNet 和 Places数据集上进行实验,结果在下表中。在ImageNet上,DeepCluster在conv2 - conv5层的性能都不同幅度的超过了其他方法。
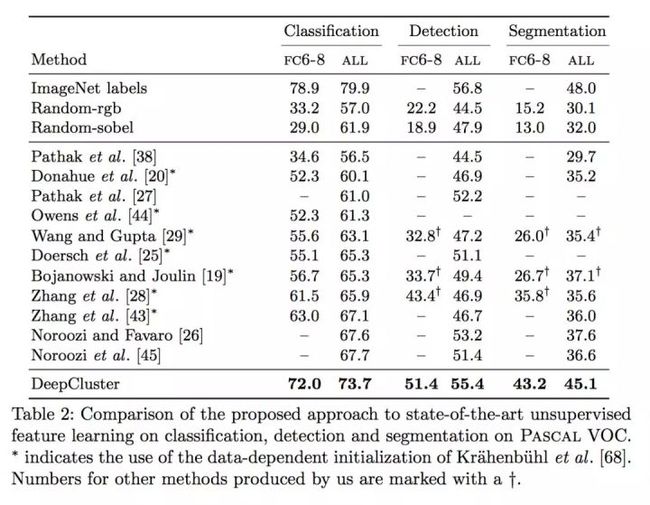
在数据集Pascal VOC 2007上实验
将使用DeepCluster方法提取的特征应用到数据集Pascal VOC 2007上,比较了不同任务下的性能,包括图像分类,目标检测,语义分割,实验结果如下,可以看出DeepCluster在三个任务上都有不同程度的提升。
讨论
上面的实验都是基于ImageNet 和 AlexNet结构,下面来对比下使用不同数据集,不同结构下的结果。
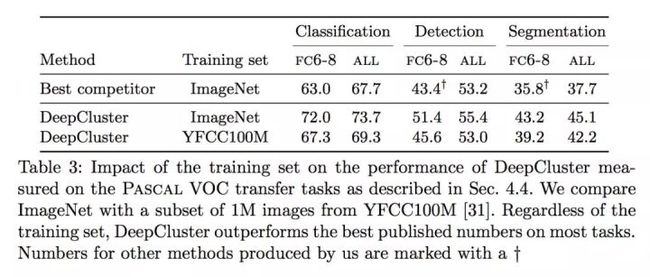
ImageNet versus YFCC100M
ImageNet是一个面向目标的分类,它每个类别的分布相对均匀,DeepCluster对于这种情况是比较适应的,并且聚类的数量与ImageNet的类别数量相匹配。为了衡量这种数据分布的影响,从YFCC100M中随机选100万张图片来做预训练,基于hashtag的统计表明这批数据不均匀。基于ImageNet 和 YFCC 100M的预训练的特征用在不同的任务上的性能。可以看出DeepCluster对于数据分布是鲁棒的,能够得到一些较好的通用特征。
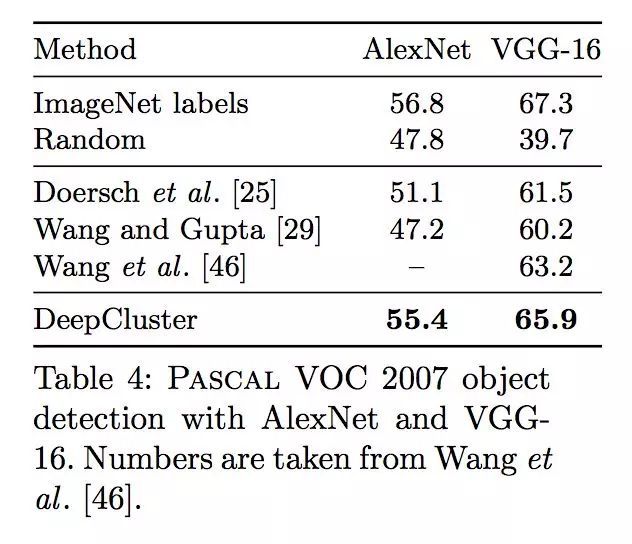
AlexNet versus VGG
在监督学习中,越深的网络往往有更好的性能,我们希望DeepCluster也有类似的效果。将在ImageNet训练得到的特征用于Pascal VOC 2007目标检测上,可以看出VGG-16 能够取得比AlexNet 更好的性能。
总结
本文提出了一种简单有效的无监督方法,这种无监督的预训练方法也能够学习很好的通用特征,使用这些特征在transfer task上的性能越来越接近监督学习的方式。
参考文献:
1. Caron, Mathilde, et al. "Deep Clustering for Unsupervised Learning of Visual Features." arXiv preprint arXiv:1807.05520 (2018).
欢迎关注我们的微信公众号:geetest_jy