大数据开发解析HBase和Hive的查询处理速度对比
今天给大家介绍一下关于HBase和Hive的查询处理速度对比,首先Hive的底层首先是MR,是属于批处理处理时间相对较长,不属于实时读写,在其架构上HBase和Hive有很大的区别,下面我们一起来看一下吧。
Hive架构:
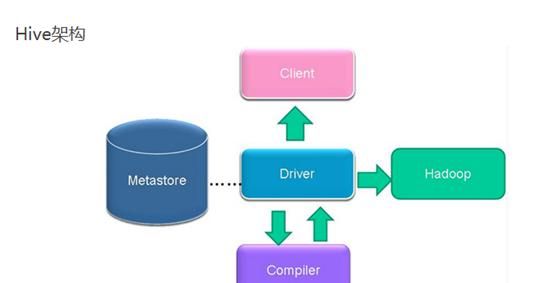
(1)用户接口主要有三个:CLI,Client和WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至HiveServer。在启动Client模式的时候,需要指出HiveServer所在节点,并且在该节点启动HiveServer。WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select*fromtbl不会生成MapRedcue任务)。
HBase架构:
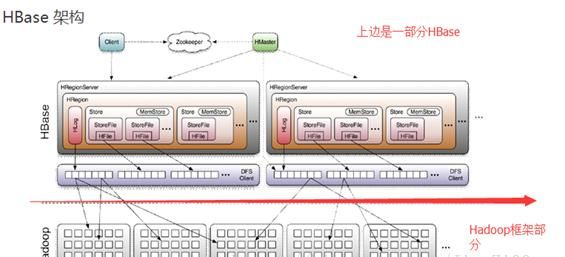
Client
包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Regionserver的上线和下线信息。并实时通知Master
存储HBase的schema和table元数据
Master
为Regionserver分配region
负责Regionserver的负载均衡
发现失效的Regionserver并重新分配其上的region
管理用户对table的增删改操作
RegionServer
Regionserver维护region,处理对这些region的IO请求
Regionserver负责切分在运行过程中变得过大的region
Memstore与storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、majorcompaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
客户端检索数据,先在memstore找,找不到再找storefile
–HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-StructuredMerge-Tree)+HTable(region分区)+Cache决定——客户端可以直接定位到要查数据所在的HRegionserver服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。
–前面说过HBase会将数据保存到内存中,在内存中的数据是有序的,如果内存空间满了,会刷写到HFile中,而在HFile中保存的内容也是有序的。当数据写入HFile后,内存中的数据会被丢弃。
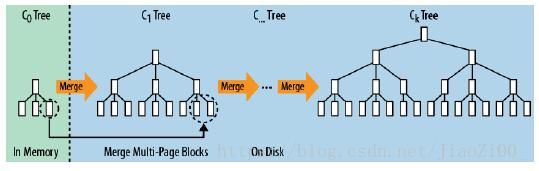
–多次刷写后会产生很多小文件,后台线程会合并小文件组成大文件,这样磁盘查找会限制在少数几个数据存储文件中。HBase的写入速度快是因为它其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile。所以在客户端看来,写入速度很快。另外,写入时候将随机写入转换成顺序写,数据写入速度也很稳定。
–而读取速度快是因为它使用了LSM树型结构,而不是B或B+树。磁盘的顺序读取速度很快,但是相比而言,寻找磁道的速度就要慢很多。HBase的存储结构导致它需要磁盘寻道时间在可预测范围内,并且读取与所要查询的rowkey连续的任意数量的记录都不会引发额外的寻道开销。比如有5个存储文件,那么最多需要5次磁盘寻道就可以。而关系型数据库,即使有索引,也无法确定磁盘寻道次数。而且,HBase读取首先会在缓存(BlockCache)中查找,它采用了LRU(最近最少使用算法),如果缓存中没找到,会从内存中的MemStore中查找,只有这两个地方都找不到时,才会加载HFile中的内容,而上文也提到了读取HFile速度也会很快,因为节省了寻道开销。
–如果快速查询(从磁盘读数据),hbase是根据rowkey查询的,只要能快速的定位rowkey,就能实现快速的查询,主要是以下因素:
hbase是可划分成多个region,并且到达一定界限会将region横向切分
键是排好序的
按列存储的
–列如:能快速找到行所在的region(分区),假设表有10亿条记录,占空间1TB,分列成了500个region,1个region占2个G.最多读取2G的记录,就能找到对应记录;
–其次,是按列存储的,其实是列族,假设分为3个列族,每个列族就是666M,如果要查询的东西在其中1个列族上,1个列族包含1个或者多个HStoreFile,假设一个HStoreFile是128M,该列族包含5个HStoreFile在磁盘上.剩下的在内存中。
然后,排好序了的,你要的记录有可能在最前面,也有可能在最后面,假设在中间,我们只需遍历2.5个HStoreFile共300M。
最后,每个HStoreFile(HFile的封装),是以键值对(key-value)方式存储,只要遍历一个个数据块中的key的位置,并判断符合条件可以了。一般key是有限的长度,假设跟value是1:20(忽略HFile其他快,只需要15M就可获取的对应的记录,按照磁盘的访问100M/S,只需0.15秒。加上块缓存机制(LRU原则),会取得更高的效率。
实时查询,可以认为是从内存中查询,一般响应时间在1秒左右。HBase的机制是将数据先写入到内存中(缓存Buffer中),当数据量达到一定的量(如128M),产生溢写磁盘操作,在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBaseI/O的高性能。