点击小眼睛开启蜘蛛网特效

深度学习中,许多的实现并不单单是神经网络的搭建和训练,也包括使用一系列传统的方法与之结合的方式去增强深度学习的实现效果,在语义分割(semantic segmentation)和风格迁移(style transfer)中都有使用过MRF-Markov Random Field(马尔科夫随机场)这个概念,并且达到了不错的效果。
马尔科夫网络这个传统方法的概率模型思想值得我们去借鉴,本文主要对马尔科夫随机场进行讲解,并且对使用MRF这个方法的深度学习项目进行分析和描述。

使用MRF的Image Synthesis得到的风格相比style-transfer更加抽象
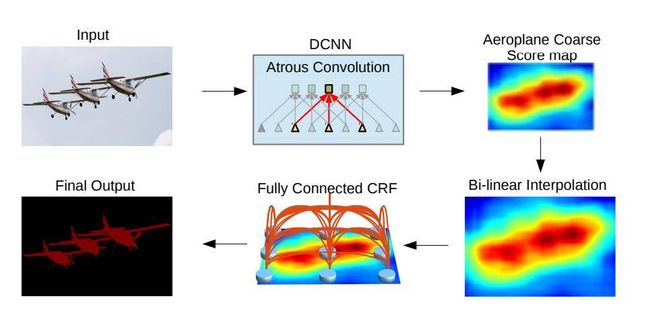
Deeplab-v2中采用全连接条件随机场对结果进行优化
深度学习中,许多的实现并不单单是神经网络的搭建和训练,也包括使用一系列传统的方法与之结合的方式去增强深度学习的实现效果,在语义分割(semantic segmentation)和风格迁移(style transfer)中都有使用过MRF-Markov Random Field(马尔科夫随机场)这个概念,并且达到了不错的效果。
马尔科夫网络这个传统方法的概率模型思想值得我们去借鉴,本文主要对马尔科夫随机场进行讲解,并且对使用MRF这个方法的深度学习项目进行分析和描述。
首先我们简单说一下后面介绍需要的一些基础知识,这些知识其实都是我们大学课程中学习过的课程。在《概率论》、《算法导论》以及《统计学方法》中都有详细介绍。这里只是进行简单的介绍,虽然是基础,但是对马尔科夫随机场的理解还是很有帮助的。
条件概率,我们使用这个概念的时候往往是用来解决逆问题,也就是已知结果反推原因的一个过程。而经典的贝叶斯定理公式:
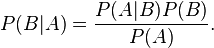
我们常常利用这个公式去推导我们无法直接观测的问题,首先明白一个概念:上面的式子中,AAA是结果,BBB是原因。而上面这个式子我们要做的任务就是:
- 已知P(A∣B)P(A|B)P(A∣B)和P(B)P(B)P(B)(P(A)P(A)P(A)可以通过P(A)=∑nP(A∣B)×P(Bi)P(A)={\sum }^{n}P(A|B)\times P(B_{i})P(A)=∑nP(A∣B)×P(Bi)计算得到)
- 要求P(B∣A)P(B|A)P(B∣A)
我们一般称P(原因)为先验概率,P(原因|结果)称为后验概率,相应的为先验分布和后验分布。
随机游走是一个典型的随机过程,就和我们丢骰子走步数一样。但这里我们简单分为两种可能,假设我们抛掷一个硬币,正面我们就向上走一步,反面我们就向下走一步。
这个过程很简单,也就是向下走和向上走的概率都是50%,也就是我们设:
X0=0,Xt=Xt−1+ZtX_0 = 0, X_t = X_{t-1} + Z_tX0=0,Xt=Xt−1+Zt
那么下图就是一些具体的观测值。
随机游走很两个特点我们要注意:
- 每次行动时,下一步的动作和前几步动作没有关系,和前几步的动作都没关系,也就是说我们无法通过当前的状态去推断未来的状态
- 因为每一步和周围周围的行动都没有关系,所以我们可以知道,无论上方的图折线如何变化,其发生的概率都是一样的(反射原理)。
假如我们在在t=9t=9t=9的时候将折线进行翻转,这种情况的概率和之前是一样的。
图模型我们一般是用于表示随机变量之间的相互作用,我们把随机变量带到图中,图中每一个点是我们实际图中的像素点,每个像素点通过“边”来连接。
概率无向图模型(probabilistic undirected graphical model)又称为马尔科夫随机场(Markov Random Field),或者马尔科夫网络。而有向图模型通常被称为信念网络(belief network)或者贝叶斯网络(Bayesian network)。对于这个我们要稍加区分。
有向图每个边都是有方向的,箭头所指的方向表示了这个随机变量的概率分布点,比如一个节点a到节点b的一个箭头,这个箭头就表明了节点b的概率由a所决定。我们举个简单的例子(例子来源于深度学习圣经P342使用图描述模型结构):
假设一个接力赛,Alice的完成时间为t0t_0t0,Bob的完成时间为t1t_1t1,而Carol的完成时间为t2t_2t2。和之前说的一样,t2t_2t2取决于t1t_1t1,而t1t_1t1取决于t0t_0t0,而t2t_2t2间接依赖于t0t_0t0。
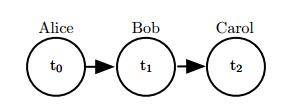
也就是说Carol的完成时间和Bob有关系和Alice也有关系,是单方向依赖的.

本文我们要说的是马尔科夫随机场,马尔科夫随机场是无向图模型,也就是两个点之前并没有明确的前后以及方向关系,虽然两个点之前存在相互作用,但是这个作用仅仅在附近的点与点之间,与更远处的点或者最前面的点并没有关系。

用公式表示一下:
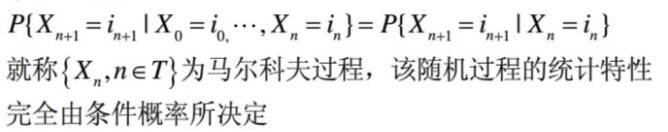
下面我们来正式介绍一下:
马尔科夫随机场
马尔科夫随机场之前简单进行了提及,我们知道其特点是两点之间的因果关系没有明确的方向,我们再来举个例子来说明一下(例子来源于A friendly introduction to Bayes Theorem and Hidden Markov Models):
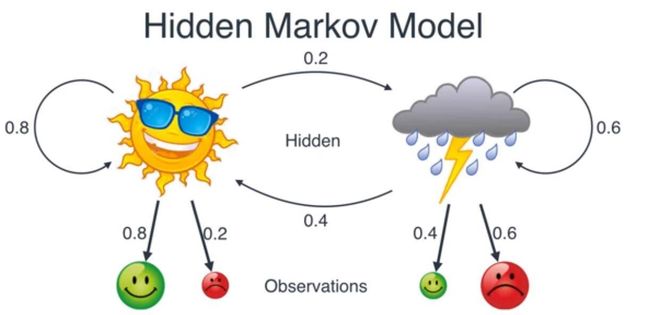
这个例子是很经典的天气心情假设,假设下图中右面的人是Bob,他在天气比较晴朗的时候有极大的可能是高兴的,而在下雨的时候有一定可能是郁闷的。而现在我们要做的就是根据Bob的心情情况来猜测当前的天气信息。
这个就是典型的已知结果(Bob的心情)去推导原因(天气情况)。
当然我们需要一些其他的概率信息(也就是上面贝叶斯定理中我们要做的任务中需要的信息P(原因)和P(结果|原因)),我们通过统计一段时间的天气以及Bob的心情变化得出了我们需要的概率信息。
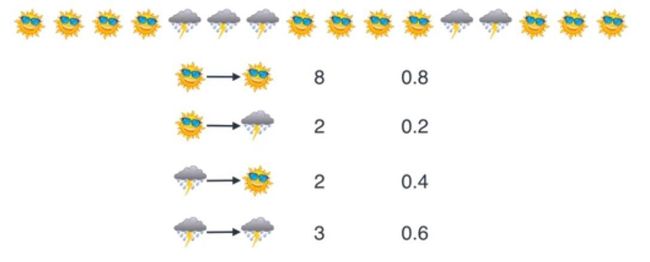
也就是15天中10天是晴天(某一天是晴天的概率是10/15=2/310/15=2/310/15=2/3),5天是阴天(某一天是阴天的概率是5/15=1/35/15=1/35/15=1/3)。而且昨天是晴天今天是晴天的概率是0.8,昨天是阴天今天晴天的概率是0.2;昨天是阴天今天是阴天的概率是0.6,昨天是阴天今天是晴天的概率是0.4。
另外还有Bob在这些天的心情情况,可以分别总结出,晴天阴天Bob的心情概率。

好了,我们所需要的概率都计算完毕,那么我们需要的就是搭建一个HMM(Hidden Mardov Model)因马尔科夫模型。
要说到HMM首先要说马尔科夫链。
马尔科夫链
马尔科夫链即上图中晴天(B)和阴天(A)的转换公式:
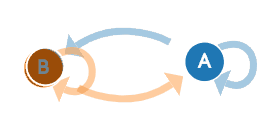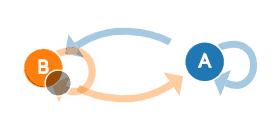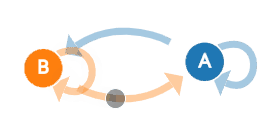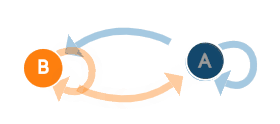
我们以上面的例子为例,A和B两种状态(B代表晴天A代表阴天),有四种可能的转移概率(transition probabilities),分别是 A->A、A->B、B->B、B->A。可以看到下图右面的概率分布(P(A∣A)P(A|A)P(A∣A)也就是晴天到晴天的概率为0.8,其他概率与上面的晴天阴天概率相同),另外右边概率转移矩阵的每一行概率加起来都为1。
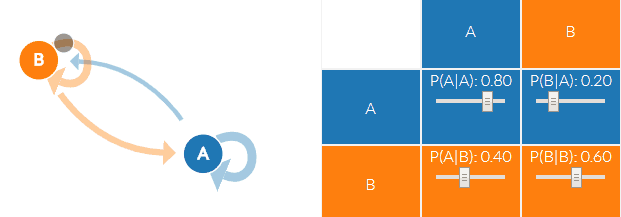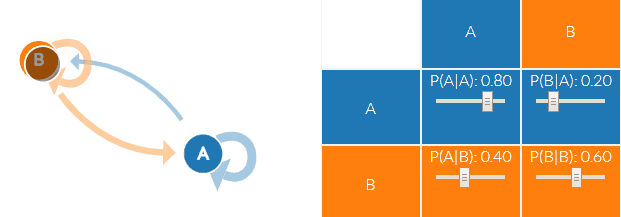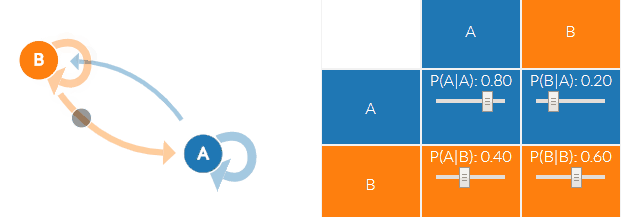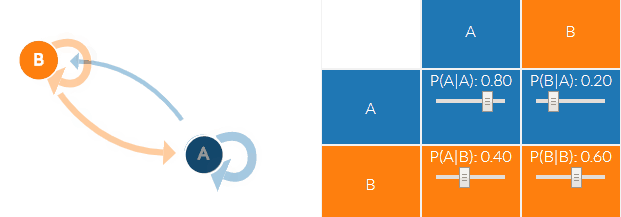
通过这个天气的马尔科夫链,我们就可以得到接下来的天气情况(S代表Sunny晴天,R代表rainy雨天):

当然上面表示仅仅是简单的马尔科夫链,如果是复杂的马尔科夫链:
显然,右边是这个马尔科夫链的概率转移矩阵,每一行的概率值加起来为1。
上面动图来源于参考中的:Markov Chains。
说完马尔科夫链我们来说明下HMM隐马尔科夫模型。
我们再来看一下之前的图:
我们知道,上面的晴天和阴天的转换公式为我们之前说到的马尔科夫链,但是在我们之前说明的问题中,我们要通过观察Bob的心情来推测今天的天气。也就是说,上面的天气变化(晴天变为阴天)是随机变化,Bob的心情(由天气导致的心情变化)也是随机变化,整个的过程就是所谓的双重随机过程。
上面的过程有两个特点:
- 输出(Bob的心情)依然只和当前的状态(今天的天气)有关
- 想要计算观察的序列(知道Bob连续好多天的心情,推算出最可能的连续几天的天气情况),只需要依照最大似然概率计算即可

下面的O1,O2,...,QtO_1,O_2,...,Q_tO1,O2,...,Qt即观察值(Bob的天气),而S1,S2,...,StS_1,S_2,...,S_tS1,S2,...,St为中间的状态(天气情况)。

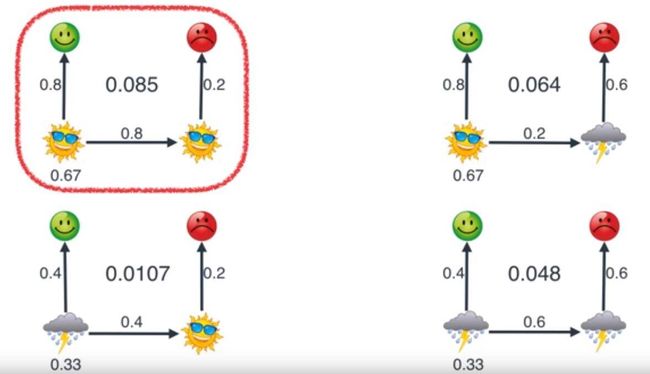
所以,假如我们想要通过Bob连续几天的心情变化来推算最有可能的天气情况,下图为取的是最有可能的情况:
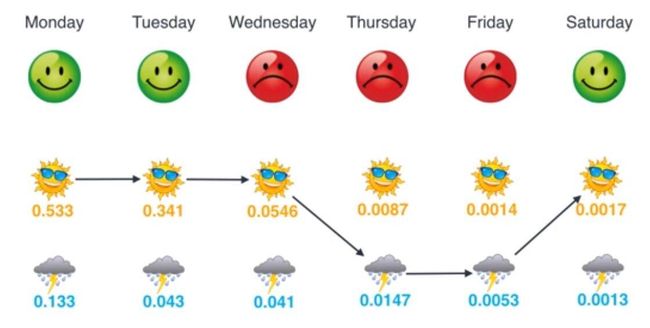
挑选了一个最有可能的概率情况,依次链接(乘起来)即可,下面0.085=P(O1∣S1)∗P(O2∣S2)=(0.67∗0.8)∗(0.8∗0.2)0.085 = P(O_1|S_1) * P(O_2|S_2) = (0.67 * 0.8) * (0.8 * 0.2)0.085=P(O1∣S1)∗P(O2∣S2)=(0.67∗0.8)∗(0.8∗0.2),第一个中的0.67为我们之前谈到的不知道昨天是什么天气猜测为晴天的概率,第二个中的0.8是因为昨天是晴天,所以今天有0.8的概率为晴天:
上面的天气心情计算中,我们想要根据Bob一段时间的心情来判断一段时间的天气,我们只要选区所有条件中概率最大的那一条路即可,但是实际中我们的计算量还是很高的,一个一个去算难度会逐渐加大,Viterbi算法算一个,采用动态规划的方法计算条件概率最大的那一条路。也有在Forward-Backward算法(Baum-Welch)来估计概率转移矩阵,当然这里就不详细讲述了,有兴趣可以看参考中的A friendly introduction to Bayes Theorem and Hidden Markov Models。
条件随机场(conditional random field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。比如我们输入一个多维的信号XXX然后得到相应的多维输出YYY,这时候我们搭建模型去计算P(Y∣X)P(Y|X)P(Y∣X)这个概率分布。而马尔科夫随机场是一个联合概率分布P(A,B)P(A,B)P(A,B),给予你一个无向图GGG,我们可以通过多种方式(或者说多种路径)来计算P(Y∣X=x)P(Y|X=x)P(Y∣X=x)。
或者这样说,我们平时的任务,例如深度学习中典型的图像分类问题,我们通过输入XXX(图像)来得到YYY(分类结果)。这是一个典型的监督学习,我们通过输提供信息XXX(dataset)和YYY(label)来进行来实现P(Y∣X)P(Y|X)P(Y∣X)(或者这样表示:Y=f(X)Y=f(X)Y=f(X)),监督学习又分为两种,一种是生成模型(MRF),由数据学习联合分布P(X,Y),然后得到上面的条件概率:
P(Y∣X)=P(X,Y)P(X)P(Y|X)=\frac{P(X,Y)}{P(X)}P(Y∣X)=P(X) P(X,Y)
而判别模型则是直接学习XXX(k-mean)或者学习P(Y∣X)P(Y|X)P(Y∣X)(CRF),也就是说,判别模型关心的是输入什么输出什么,直接预测。
再详细点来说,条件随机场类似于逻辑回归,就是利用输入分布去求输出分布,可以当做是给定随机变量XXX的条件下,随机变量YYY的马尔科夫随机场,注意这里的称呼方法,马尔科夫随机场只是一个联合概率分布,并不是条件分布(输入X输出Y)。我们可以假设条件随机场的输出随机变量构成马尔科夫随机场。
条件随机场因为其特性,可以比较直接地对标准的预测问题(P(Y∣X=x))(P(Y|X=x))(P(Y∣X=x))进行建模,因为目标明确随意准确度也相应的高一些,但是也只能做标准预测的问题。而马尔科夫随机场则是典型的生成模型,可以对任何想要预测的问题进行建模。例如因为一些原因你丢失了输入变量x,然后MRF就可以对丢失的变量进行全概率分布的建模,就是你有y然后你就可以通过y来求P(X∣Y=y)P(X|Y=y)P(X∣Y=y),而CRF就不能这样。但要注意这里的x和y都不是输入也不是输出,仅仅是这个随机场中的变量罢了。
总结一下:条件概率场就是特殊情况的马尔科夫随机场。
通过之前的探讨我们知道贝叶斯网络是有向图模型,而马尔科夫随机场是无向图模型,有向图模型的特点是序列之间有先后连续,前面的结果会对后面的结果产生影响,有向图模型通常应用于这些方面:
而我们的马尔科夫随机场则不同,MRF经常用于图像方面,因为MRF虽然也表示两个变量之前的相互关系,但是不用于有向图模型,两个点之前并没有明显的因果关系,所以可以对很多的平等关系的事物进行建模。
而图像则是一个典型的马尔科夫随机场,在图像中每个点可能会和周围的点有关系有牵连,但是和远处的点或者初始点是没有什么关系的,离这个点越近对这个点的影响越大。(这个很好理解,图像中这个像素点是黑色的,那个很有可能周围也是黑色的像素,但是并不能够推断出距离这个像素点远的像素点们也是黑色的)。当然这个附近,也就是这个领域的范围和大小,是由我们自己去决定的。
例如一阶领域系统:
[16324]\begin{bmatrix} & 1 & \\ 6 & 3 & 2 \\ & 4 & \\ \end{bmatrix}⎣⎡61342⎦⎤
以及二阶领域系统:
[219632342]\begin{bmatrix} 2 & 1 & 9 \\ 6 & 3 & 2 \\ 3 & 4 & 2 \\ \end{bmatrix}⎣⎡263134922⎦⎤
相应的因子团:
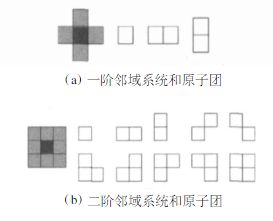
很好理解,无向图G中任何两个结点均有边链接的结点子集称为团,为什么叫因子团,是因为概率无向图可以进行因子分解,也就是将一个数18分为3*6,概率无向图(MRF)因为其特性(之前说过)可以将每个结点的概率直接相乘得到最大似然概率。这个过程也叫作因子分解,所以我们也称这些团为因子团。
回到我们的主题,我们之前说过图像中的像素点分布可以看成是一个马尔科夫随机场,因为图像某一领域的像素点之间有相互的关系:(图片来自于Deep Learning Markov Random Field for Semantic Segmentation)。
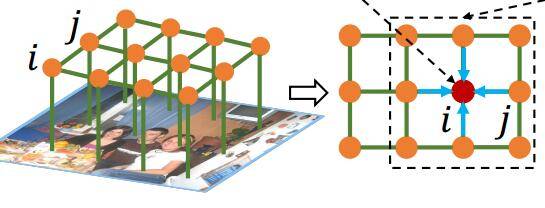
正如上面的图片,图片中每个像素点都是无向图中的一个结点,每个结点之间都有着联系,我们所说的图像分割本质上也可以说是图像聚类,将图像中相似的像素点进行聚和,这时我们需要求得就是每个像素点的分类标签lll,知道每个像素点的分类标签,当然就可以很好地对图片进行分割了。
我们再拿出之前的贝叶斯公式:
P(Y∣X)=P(X∣Y)∗P(Y)P(X)P(Y|X)=\frac{P(X|Y)*P(Y)}{P(X)}P(Y∣X)=P(X) P(X∣Y)∗P(Y)
这里我们变换一下变量,假设我们输入图像是SSS,分类结果是WWW:
P(W∣S)=P(S∣W)∗P(W)P(S)P(W|S)=\frac{P(S|W)*P(W)}{P(S)}P(W∣S)=P(S) P(S∣W)∗P(W)
图像就是我们要输入的分类图像,图中的像素点p⊂Sp \subset Sp⊂S,然后W是我们的分割结果,假设我们的分割结果为4类:w1,w2,w3,w4⊂Ww_1,w_2,w_3,w_4 \subset Ww1,w2,w3,w4⊂W。我们利用先验概率P(W)P(W)P(W)(假设我们事先知道了要分的类)以及条件概率P(S∣W)P(S|W)P(S∣W),这个条件概率就是HMM(隐马尔科夫随机场,上文有说)的一部分,因为我们要通过W得到S,W是观察值,S是HMM中隐含的概率转移链(这部分稍有疑惑的可以回顾之前Bob心情天气讲解)。
同时这个P(S∣W)P(S|W)P(S∣W)是P(W∣S)P(W|S)P(W∣S)的似然函数,什么是似然函数,似然函数就是取得最大值表示相应的参数能够使得统计模型最为合理。我们的任务是求P(W∣S)P(W|S)P(W∣S),根据输入图像得到分类信息,而P(S∣W)P(S|W)P(S∣W)则是知道了分类信息去求这个分类信息表示的像素点的概率,表示我们分好类的各个像素点和真实的像素点分布是否匹配的关系。
最后就剩下了P(S)P(S)P(S),这个就是我们输入图像的分布,这个分布我们当然是知道的,而且也不会变。在计算中这个认为是定值就可以了。
如果不好理解,可以和之前的例子进行结合。我们理一下现在讨论的和之前Bob心情推算的关系,理解了的可以跳过这个步骤:
- P(S∣W)P(S|W)P(S∣W) => 已知天气Bob的心情,去求天气情况。
- P(W∣S)P(W|S)P(W∣S) => 推算天气最有可能的情况,是否最有可能正确表示Bob的心情。
- P(W)P(W)P(W) => Bob的心情情况。
- P(S)P(S)P(S) => 天气为晴天或者阴天的情况。
好了回到正题,在上面的图像分布中,我们将这个图像分割任务以HMM的形式来理解下,那就是,我们知道每个像素点之间的概率关系,而且两个像素点之间的关系只是“当前关系”,就是昨天与今天的关系,和前天没关系。
当然我们在实际中是以邻域的方式去确定两个像素点之间的关系,也就是在SSS中的某一像素点的取值概率只和相邻点有关而与其他距离远的点无关。
回到刚才的公式:
P(W∣S)=P(S∣W)∗P(W)P(S)P(W|S)=\frac{P(S|W)*P(W)}{P(S)}P(W∣S)=P(S) P(S∣W)∗P(W)
我们要根据P(S∣W),P(W)P(S|W),P(W)P(S∣W),P(W)去求出P(W∣S)P(W|S)P(W∣S),再理一下:
- P(S∣W)P(S|W)P(S∣W)是我们要求P(W∣S)P(W|S)P(W∣S)的似然函数
- P(W)P(W)P(W)是这个模型的先验概率
我们先说P(W)P(W)P(W),它代表我们要求的分类标记(w1,w2,w3,w4⊂Ww_1,w_2,w_3,w_4 \subset Ww1,w2,w3,w4⊂W),之前的四个类只是我们的假设,我们并不知道这个图像分割为几类了,难道我们要无中生有吗?这时候就需要联系吉布斯分布(gibbs sampling)。
下面的式子即吉布斯分布:
P(W)=z−1e−1TU2(W)P(W)=z^{-1}e^{-\dfrac{1}{T}U_2(W)}P(W)=z−1e−T 1U2(W)
其中z=∑we−U2(w)Tz=\sum_{w}e^{-\dfrac{U_2(w)}{T}}z=∑we−T U2(w),是配分函数,也是一个归一化常数,TTT越大这个P(W)P(W)P(W)的窗口越平滑,另外U2(w)=∑c∈CVc(wc)U_2(w)=\sum_{c\in C}V_c(w_c)U2(w)=∑c∈CVc(wc),其中CCC是势能团的集合,而:
Vc(wc)=Vs,r(ws,wr)={−βws=wtβws≠wtV_c(w_c) = V_{s,r}(w_s,w_r)= \begin{cases} -\beta & w_s=w_t \\ \beta & w_s\ne w_t \end{cases}Vc(wc)=Vs,r(ws,wr)={−ββws=wtws≠wt
为势能团的势能。其中β\betaβ为耦合系数,s,ts,ts,t分别为相邻的两个像素点
什么是势能团,我们可以结合之前说的因子团,说的那么玄乎其实原理是一样的,图中的像素结点构成所谓的团,利用上面的吉布斯分布就可以求出我们的分割分布信息。
根据Hammersley Clifford理论,马尔科夫随机场和Gibbs分布是一致的,也就是说,P(W)P(W)P(W)的分布满足Gibbs分布,当然这个理论证明这里不赘述,感兴趣的可以看下相关的研究,我们这里简单说下为什么我们的分割标记分布类似于吉布斯分布式。
吉布斯采样(gibbs sampling)是利用条件分布进行一系列运算最终近似得到联合分布的一种采样方法,相应的,吉布斯分布就表示这些满足吉布斯分布的分布信息可以通过求相应的条件概率来近似地求这些分布信息的联合分布。(利用知道P(A|B)和P(B|A)近似求P(A,B)),而在这个图像中,我们可以知道P(w1∣w2)P(w_1|w_2)P(w1∣w2)这种的局部作用关系,也就是假如这个像素点标记为分类1(w1w_1w1),那么这个像素点周围的标记信息分别是多少,计算其周围分布标记信息的概率,从而确定这个像素点的分类标记是否正确需不需要更新,但在实际计算中我们往往只是计算这个像素点周围标记信息的次数来判断这个像素点属于哪个分类标记。
而且我们注意到P(S∣W)∗P(W)=P(S,W)P(S|W)*P(W) =P(S,W)P(S∣W)∗P(W)=P(S,W),所以求argmaxwP(W∣S)=P(S∣W)∗P(W)P(S)argmax_{w}P(W|S)=\frac{P(S|W)*P(W)}{P(S)}argmaxwP(W∣S)=P(S) P(S∣W)∗P(W)
也就是求:
argmaxwP(W∣S)=P(S,W)P(S)argmax_{w}P(W|S)=\frac{P(S,W)}{P(S)}argmaxwP(W∣S)=P(S) P(S,W)P(S,W)P(S,W)P(S,W)即图像和分割信息的联合概率分布,这也就是我们为什么要用吉布斯分布来表示P(W)P(W)P(W),而P(S)P(S)P(S)为常数。
用到了吉布斯分布,我们的这个随机场就可以转化为势能的问题,通过能量函数确定MRF的条件概率,从而使其在全局上具有一致性。也就是我们通过单个像素及其邻域的简单的局部交互,MRF可以获得复杂的全局行为,即利用局部的Gibbs分布得到全局的统计结果。
在实际中,我们求得是P(S∣W)∗P(W)P(S|W)*P(W)P(S∣W)∗P(W),P(W)P(W)P(W)可以通过之前说的势能函数求出来,而求P(S∣W)P(S|W)P(S∣W)即利用标记信息去估计这个像素点的值,假设某个标记分类中的像素点分布满足高斯分布(假设分类2中的像素点大部分满足50-100的灰度值,中心是80),我们就可以根据某一个像素点的值判断它在哪个分类中:
0 50 100 150 200 250 0 0.2 0.4 0.6 0.8 1
w1 w2 w3 w4 S(像素的灰度值) P(像素点在该分类下出现的概率)
比如某一点的灰度为60,从上图就可以看出这像素点最有可能在哪个分类中(上图中可以看出是这个像素点最可能在第二分类中),其他的灰度值我们也能看得出来。
相当于一个高斯分布:
P(S∣w=1,2,3,4)=1δ2πe−(x−μ)22δ2P(S|w=1,2,3,4) = \frac {1}{\delta\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\delta^2}}P(S∣w=1,2,3,4)=δ2π 1e−2δ2 (x−μ)2
求出其中的μ=1Nw∑s\mu=\frac{1}{N_w}\sum{s}μ=Nw 1∑s以及δ2=1Nw∑(y−u)2,π=NwN\delta^2=\frac{1}{N_w}\sum{(y-u)^2},\pi=\frac{N_w}{N}δ2=Nw 1∑(y−u)2,π=N Nw。其中NwN_wNw为某种分类下像素的个数,NNN为整幅图的像素个数,yyy为像素值。
这样,通过P(S∣w1),P(S∣w2),P(S∣w3),P(S∣w4)P(S|w_1),P(S|w_2),P(S|w_3),P(S|w_4)P(S∣w1),P(S∣w2),P(S∣w3),P(S∣w4)就可以估计每个像素点的分割分类,最后我们将后验概率转化为先验概率和似然函数的乘积(P(W)∗P(S∣W)P(W)*P(S|W)
首先我们简单说一下后面介绍需要的一些基础知识,这些知识其实都是我们大学课程中学习过的课程。在《概率论》、《算法导论》以及《统计学方法》中都有详细介绍。这里只是进行简单的介绍,虽然是基础,但是对马尔科夫随机场的理解还是很有帮助的。
条件概率,我们使用这个概念的时候往往是用来解决逆问题,也就是已知结果反推原因的一个过程。而经典的贝叶斯定理公式:
我们常常利用这个公式去推导我们无法直接观测的问题,首先明白一个概念:上面的式子中,AAA是结果,BBB是原因。而上面这个式子我们要做的任务就是:
- 已知P(A∣B)P(A|B)P(A∣B)和P(B)P(B)P(B)(P(A)P(A)P(A)可以通过P(A)=∑nP(A∣B)×P(Bi)P(A)={\sum }^{n}P(A|B)\times P(B_{i})P(A)=∑nP(A∣B)×P(Bi)计算得到)
- 要求P(B∣A)P(B|A)P(B∣A)
我们一般称P(原因)为先验概率,P(原因|结果)称为后验概率,相应的为先验分布和后验分布。
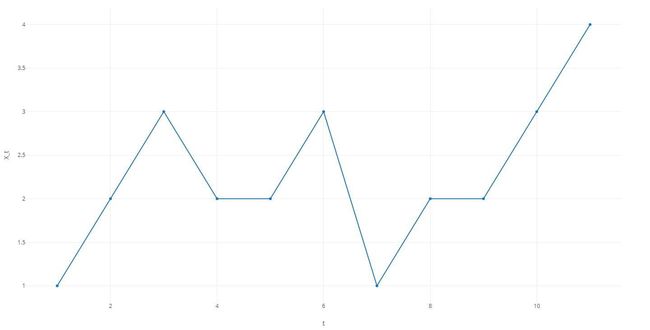
随机游走是一个典型的随机过程,就和我们丢骰子走步数一样。但这里我们简单分为两种可能,假设我们抛掷一个硬币,正面我们就向上走一步,反面我们就向下走一步。
这个过程很简单,也就是向下走和向上走的概率都是50%,也就是我们设:
X0=0,Xt=Xt−1+ZtX_0 = 0, X_t = X_{t-1} + Z_tX0=0,Xt=Xt−1+Zt
那么下图就是一些具体的观测值。
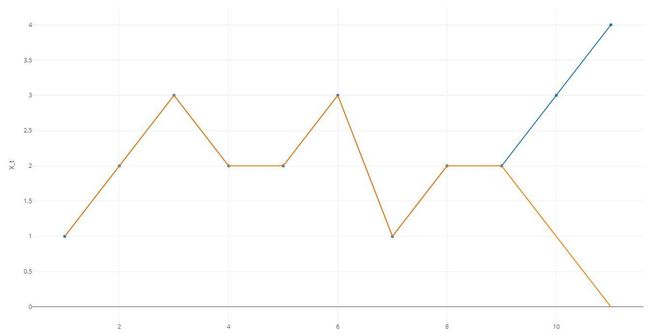
随机游走很两个特点我们要注意:
- 每次行动时,下一步的动作和前几步动作没有关系,和前几步的动作都没关系,也就是说我们无法通过当前的状态去推断未来的状态
- 因为每一步和周围周围的行动都没有关系,所以我们可以知道,无论上方的图折线如何变化,其发生的概率都是一样的(反射原理)。
假如我们在在t=9t=9t=9的时候将折线进行翻转,这种情况的概率和之前是一样的。
图模型我们一般是用于表示随机变量之间的相互作用,我们把随机变量带到图中,图中每一个点是我们实际图中的像素点,每个像素点通过“边”来连接。
概率无向图模型(probabilistic undirected graphical model)又称为马尔科夫随机场(Markov Random Field),或者马尔科夫网络。而有向图模型通常被称为信念网络(belief network)或者贝叶斯网络(Bayesian network)。对于这个我们要稍加区分。
有向图每个边都是有方向的,箭头所指的方向表示了这个随机变量的概率分布点,比如一个节点a到节点b的一个箭头,这个箭头就表明了节点b的概率由a所决定。我们举个简单的例子(例子来源于深度学习圣经P342使用图描述模型结构):
假设一个接力赛,Alice的完成时间为t0t_0t0,Bob的完成时间为t1t_1t1,而Carol的完成时间为t2t_2t2。和之前说的一样,t2t_2t2取决于t1t_1t1,而t1t_1t1取决于t0t_0t0,而t2t_2t2间接依赖于t0t_0t0。
也就是说Carol的完成时间和Bob有关系和Alice也有关系,是单方向依赖的.
本文我们要说的是马尔科夫随机场,马尔科夫随机场是无向图模型,也就是两个点之前并没有明确的前后以及方向关系,虽然两个点之前存在相互作用,但是这个作用仅仅在附近的点与点之间,与更远处的点或者最前面的点并没有关系。
用公式表示一下:
下面我们来正式介绍一下:
马尔科夫随机场
马尔科夫随机场之前简单进行了提及,我们知道其特点是两点之间的因果关系没有明确的方向,我们再来举个例子来说明一下(例子来源于A friendly introduction to Bayes Theorem and Hidden Markov Models):
这个例子是很经典的天气心情假设,假设下图中右面的人是Bob,他在天气比较晴朗的时候有极大的可能是高兴的,而在下雨的时候有一定可能是郁闷的。而现在我们要做的就是根据Bob的心情情况来猜测当前的天气信息。
这个就是典型的已知结果(Bob的心情)去推导原因(天气情况)。
当然我们需要一些其他的概率信息(也就是上面贝叶斯定理中我们要做的任务中需要的信息P(原因)和P(结果|原因)),我们通过统计一段时间的天气以及Bob的心情变化得出了我们需要的概率信息。
也就是15天中10天是晴天(某一天是晴天的概率是10/15=2/310/15=2/310/15=2/3),5天是阴天(某一天是阴天的概率是5/15=1/35/15=1/35/15=1/3)。而且昨天是晴天今天是晴天的概率是0.8,昨天是阴天今天晴天的概率是0.2;昨天是阴天今天是阴天的概率是0.6,昨天是阴天今天是晴天的概率是0.4。
另外还有Bob在这些天的心情情况,可以分别总结出,晴天阴天Bob的心情概率。
好了,我们所需要的概率都计算完毕,那么我们需要的就是搭建一个HMM(Hidden Mardov Model)因马尔科夫模型。
要说到HMM首先要说马尔科夫链。
马尔科夫链
马尔科夫链即上图中晴天(B)和阴天(A)的转换公式:
我们以上面的例子为例,A和B两种状态(B代表晴天A代表阴天),有四种可能的转移概率(transition probabilities),分别是 A->A、A->B、B->B、B->A。可以看到下图右面的概率分布(P(A∣A)P(A|A)P(A∣A)也就是晴天到晴天的概率为0.8,其他概率与上面的晴天阴天概率相同),另外右边概率转移矩阵的每一行概率加起来都为1。
通过这个天气的马尔科夫链,我们就可以得到接下来的天气情况(S代表Sunny晴天,R代表rainy雨天):
当然上面表示仅仅是简单的马尔科夫链,如果是复杂的马尔科夫链:
显然,右边是这个马尔科夫链的概率转移矩阵,每一行的概率值加起来为1。
上面动图来源于参考中的:Markov Chains。
说完马尔科夫链我们来说明下HMM隐马尔科夫模型。
我们再来看一下之前的图:
我们知道,上面的晴天和阴天的转换公式为我们之前说到的马尔科夫链,但是在我们之前说明的问题中,我们要通过观察Bob的心情来推测今天的天气。也就是说,上面的天气变化(晴天变为阴天)是随机变化,Bob的心情(由天气导致的心情变化)也是随机变化,整个的过程就是所谓的双重随机过程。
上面的过程有两个特点:
- 输出(Bob的心情)依然只和当前的状态(今天的天气)有关
- 想要计算观察的序列(知道Bob连续好多天的心情,推算出最可能的连续几天的天气情况),只需要依照最大似然概率计算即可
下面的O1,O2,...,QtO_1,O_2,...,Q_tO1,O2,...,Qt即观察值(Bob的天气),而S1,S2,...,StS_1,S_2,...,S_tS1,S2,...,St为中间的状态(天气情况)。
所以,假如我们想要通过Bob连续几天的心情变化来推算最有可能的天气情况,下图为取的是最有可能的情况:
挑选了一个最有可能的概率情况,依次链接(乘起来)即可,下面0.085=P(O1∣S1)∗P(O2∣S2)=(0.67∗0.8)∗(0.8∗0.2)0.085 = P(O_1|S_1) * P(O_2|S_2) = (0.67 * 0.8) * (0.8 * 0.2)0.085=P(O1∣S1)∗P(O2∣S2)=(0.67∗0.8)∗(0.8∗0.2),第一个中的0.67为我们之前谈到的不知道昨天是什么天气猜测为晴天的概率,第二个中的0.8是因为昨天是晴天,所以今天有0.8的概率为晴天:
上面的天气心情计算中,我们想要根据Bob一段时间的心情来判断一段时间的天气,我们只要选区所有条件中概率最大的那一条路即可,但是实际中我们的计算量还是很高的,一个一个去算难度会逐渐加大,Viterbi算法算一个,采用动态规划的方法计算条件概率最大的那一条路。也有在Forward-Backward算法(Baum-Welch)来估计概率转移矩阵,当然这里就不详细讲述了,有兴趣可以看参考中的A friendly introduction to Bayes Theorem and Hidden Markov Models。
条件随机场(conditional random field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。比如我们输入一个多维的信号XXX然后得到相应的多维输出YYY,这时候我们搭建模型去计算P(Y∣X)P(Y|X)P(Y∣X)这个概率分布。而马尔科夫随机场是一个联合概率分布P(A,B)P(A,B)P(A,B),给予你一个无向图GGG,我们可以通过多种方式(或者说多种路径)来计算P(Y∣X=x)P(Y|X=x)P(Y∣X=x)。
或者这样说,我们平时的任务,例如深度学习中典型的图像分类问题,我们通过输入XXX(图像)来得到YYY(分类结果)。这是一个典型的监督学习,我们通过输提供信息XXX(dataset)和YYY(label)来进行来实现P(Y∣X)P(Y|X)P(Y∣X)(或者这样表示:Y=f(X)Y=f(X)Y=f(X)),监督学习又分为两种,一种是生成模型(MRF),由数据学习联合分布P(X,Y),然后得到上面的条件概率:
P(Y∣X)=P(X,Y)P(X)P(Y|X)=\frac{P(X,Y)}{P(X)}P(Y∣X)=P(X) P(X,Y)
而判别模型则是直接学习XXX(k-mean)或者学习P(Y∣X)P(Y|X)P(Y∣X)(CRF),也就是说,判别模型关心的是输入什么输出什么,直接预测。
再详细点来说,条件随机场类似于逻辑回归,就是利用输入分布去求输出分布,可以当做是给定随机变量XXX的条件下,随机变量YYY的马尔科夫随机场,注意这里的称呼方法,马尔科夫随机场只是一个联合概率分布,并不是条件分布(输入X输出Y)。我们可以假设条件随机场的输出随机变量构成马尔科夫随机场。
条件随机场因为其特性,可以比较直接地对标准的预测问题(P(Y∣X=x))(P(Y|X=x))(P(Y∣X=x))进行建模,因为目标明确随意准确度也相应的高一些,但是也只能做标准预测的问题。而马尔科夫随机场则是典型的生成模型,可以对任何想要预测的问题进行建模。例如因为一些原因你丢失了输入变量x,然后MRF就可以对丢失的变量进行全概率分布的建模,就是你有y然后你就可以通过y来求P(X∣Y=y)P(X|Y=y)P(X∣Y=y),而CRF就不能这样。但要注意这里的x和y都不是输入也不是输出,仅仅是这个随机场中的变量罢了。
总结一下:条件概率场就是特殊情况的马尔科夫随机场。
通过之前的探讨我们知道贝叶斯网络是有向图模型,而马尔科夫随机场是无向图模型,有向图模型的特点是序列之间有先后连续,前面的结果会对后面的结果产生影响,有向图模型通常应用于这些方面:
而我们的马尔科夫随机场则不同,MRF经常用于图像方面,因为MRF虽然也表示两个变量之前的相互关系,但是不用于有向图模型,两个点之前并没有明显的因果关系,所以可以对很多的平等关系的事物进行建模。
而图像则是一个典型的马尔科夫随机场,在图像中每个点可能会和周围的点有关系有牵连,但是和远处的点或者初始点是没有什么关系的,离这个点越近对这个点的影响越大。(这个很好理解,图像中这个像素点是黑色的,那个很有可能周围也是黑色的像素,但是并不能够推断出距离这个像素点远的像素点们也是黑色的)。当然这个附近,也就是这个领域的范围和大小,是由我们自己去决定的。
例如一阶领域系统:
[16324]\begin{bmatrix} & 1 & \\ 6 & 3 & 2 \\ & 4 & \\ \end{bmatrix}⎣⎡
