mac 单机 搭建 eclipse spark开发环境
在 mac初步搭建eclipse开发spark 程序环境,并以wordcount为例,分别使用scala和java语言进行开发
软件准备:
1.The Scala IDE (based on Eclipse)
scala-SDK-4.4.1-vfinal-2.11-macosx.cocoa.x86_64.zip
根据自己的系统选择合适的版本,下载安装。
2.spark1.6
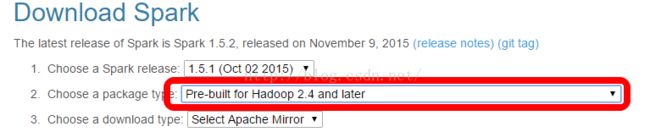
这里选择了已经为Hadoop2.6编译好的版本,为了能和Hadoop2.6更好的结合。当然有能力你可自己编译。
3使用Eclipse建立scala工程
4添加依赖jar包(位于SPARK_HOME/lib/下)--spark-assembly-1.6.0-hadoop2.6.0.jar
注意,当引入如下Spark-assembly-1.6.0-hadoop2.6.0.jar(对应我自己的spark下的jar包)会报错,提示这个jar包与源环境中的jar包冲突(提示scala环境冲突)
错误提示如下: Description Resource Path Location Type
More than one scala library found in the build path
解决方法:
1)在工程中移除自带的scala版本库
2)右击工程–> Properties –> Scala Compiler –> Use project Setting 中选择spark对应的scala版本,此处选择Lastest2.10 bundle
自此,单机开发环境已搭好,下面以wordcount为例,分别以scala和java 两种语言开发。
scala:
package sparkscala01
import org.apache.spark._
import SparkContext._
object WordCount {
def main(args:Array[String]):Unit= {
val conf =new SparkConf().setMaster("local[4]").setAppName("word count")
val sc = new SparkContext(conf)
valtextFile =sc.textFile("/Users/wxzyhx/Downloads/paper1.txt")
//val result = textFile.flatMap(line => line.split("\\s+")).map(word => (word, 1)).reduceByKey(_ + _)
textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
}
}
运行结果: 
Java:
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class JavaWordCount {
@SuppressWarnings({"rawtypes","unchecked" })
public static void main(String[] args) {
final PatternSPLIT = Pattern.compile(" ");
SparkConf conf =new SparkConf().setMaster("local[4]").setAppName("word count");
JavaSparkContext context = new JavaSparkContext(conf);
JavaRDD
@SuppressWarnings("unchecked")
JavaRDD words =lines.flatMap(newFlatMapFunction() {
@Override
public Iterable call(Objectline)throws Exception {
return Arrays.asList(SPLIT.split((String)line));
}
});
JavaPairRDD ones =words.mapToPair(newPairFunction() {
@Override
public Tuple2 call(Objectword)throws Exception {
return new Tuple2((String)word, 1);
}
});
JavaPairRDD counts =ones.reduceByKey(newFunction2() {
@Override
public Integer call(Objectarg0, Objectarg1)throws Exception {
return (Integer)arg0 + (Integer)arg1;
}
});
List
for (Tuple2tuple :output) {
System.out.println(tuple._1() +": " +tuple._2());
}
context.close();
}
}
运行结果:
