聊天机器人之文本聚类分析
目录
- 文本聚类
- 聚类算法
- Affinity propagation
- 算法概述
- 特点
- K-means
- 算法概述
- 特点
- Chinese Whispers
- 算法概述
- 特点
- 选择算法
- 计算过程优化
- 聚类API设计
- 参考资料
文本聚类
文本聚类(Text Clustering),是依据同类文档的相似度较大,而不同类的文档相似度较小的原则,使用无监督的机器学习方法,将同类文档从目标语料库聚集到一簇的任务。聚类不需要训练过程,也不需要预先对文档进行手工标注类别,因此具有一定的灵活性和较高的自动化处理能力,是对文本信息进行有效的组织、摘要和导航的重要手段。
使用场景:
- 自动文摘
- 优化搜索引擎结果
- 文档集合自动整理
- 改善文本分类
- 知识图谱语料处理
- 优化知识库,分析历史数据
- 增强聊天机器人知识库检索能力
- 发现新业务、新意图
- 提升数据标注效率
总之,任何机器学习的问题,都可以视为分类问题,而分类问题的对立就是聚类,如果可以实现美好的无监督聚类算法,可以说是巨大的飞跃。分析聚类问题就是寻找上帝造物的秘密。
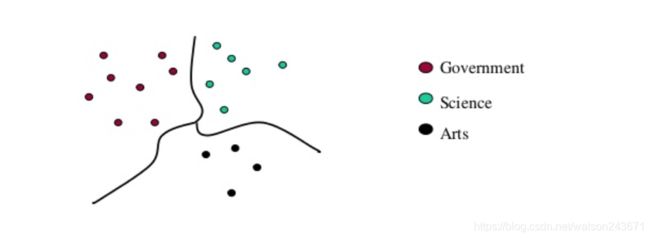
聚类算法
常见的聚类算法包括:Affinity propagation, K-means, Chinese Whispers。
Affinity propagation
算法概述
Affinity propagation 简称AP算法,AP算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度( Responsibility)和归属度(Availability)。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。
在AP算法中有一些特殊名词:
Exemplar:指的是聚类中心,K-Means中的质心。
Similarity:数据点 i i i和点 j j j的相似度记为 s ( i , j ) s(i,j) s(i,j),是指点 j j j作为点 i i i 的聚类中心的相似度。一般使用欧氏距离来计算,一般点与点的相似度值全部取为负值;因此,相似度值越大说明点与点的距离越近,便于后面的比较计算。
Preference:数据点 i i i的参考度称为 p ( i ) p(i) p(i)或 s ( i , i ) s(i,i) s(i,i),是指点 i i i作为聚类中心的参考度。一般取 s s s相似度值的中值。
Responsibility: r ( i , k ) r(i,k) r(i,k) 用来描述点 k k k 适合作为数据点 i i i的聚类中心的程度。
Availability: a ( i , k ) a(i,k) a(i,k) 用来描述点 i i i选择点 k k k作为其聚类中心的适合程度。
Damping factor (阻尼系数):主要是起收敛作用的。
在实际计算应用中,最重要的两个参数是Preference和Damping factor。前者定了聚类数量的多少,值越大聚类数量越多;后者控制算法收敛效果。这两个值需要手动指定。
特点
[1] 与众多聚类算法不同,AP聚类不需要指定描述聚类个数的参数。
[2] 一个聚类中最具代表性的点在AP算法中叫做Examplar,与其他算法中的聚类中心不同,examplar是原始数据中确切存在的一个数据点,而不是由多个数据点求平均而得到的聚类中心(K-Means)。
[3] 多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤。
[4] 算法复杂度较高 O ( N × N × log 2 ( N ) ) O(N \times N \times \log_2(N)) O(N×N×log2(N)),为 ,而K-Means只是 O ( N × K ) O(N \times K) O(N×K) 的复杂度。因此当N比较大时 ( N > 300 ) (N > 300) (N>300),AP聚类算法往往需要算很久。
[5] 若以误差平方和来衡量算法间的优劣,AP聚类比其他方法的误差平方和都要低。无论k-center clustering重复多少次,都达不到AP那么低的误差平方和。
[6] AP通过输入相似度矩阵来启动算法,因此允许数据呈非欧拉分布,也允许非常规的“点-点”距离度量方法。
K-means
算法概述
K-means算法也被成为K均值算法,它的计算过程如下:
[1] 从所有文档中随机取K个元素,作为k个簇的各自的中心。
[2] 分别计算剩下的元素到K个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
[3] 根据聚类结果,重新计算K个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
[4] 将文档中全部元素按照新的中心重新聚类。
[5] 重复第4步,直到聚类结果不再变化。
[6] 将结果输出。
特点
[1] 可以按照给定的簇的数量进行聚类,在预先知道聚簇数量时,是相对可伸缩和高效的。
[2] 计算速度快,时间复杂度为 O ( N × K ) O(N \times K) O(N×K)。
K-means的主要缺点是要预先设定聚类数量,如果在聚类数据中存在“噪声”,即明显的孤立点数据,会对结果产生极大影响。
Chinese Whispers
算法概述
Chinese Whispers算法基于图进行聚类,它的计算过程如下:
[1] 构建无向图,将每个文档作为无向图中的一个节点,文档之间的相似度作为节点之间的边,设定一个阀值,如果文档之间的相似度小于这个阀值,就不建立边。
[2] 初始化,为每个节点设定一个“类”属性,并且值初始化为该文档的标识ID。
[3] 开始迭代,随机选取某个节点,对该节点进行下面的处理:
-
a. 遍历所有邻居,寻找边的权重最大的邻居,并且这个邻居节点的类设置为该节点的类。
-
b. 如果经过第1次迭代,有可能出现多个邻居属于同一个类,那么就讲同一个类的邻居权重累加,最后,看哪个类的权重大,则设置为当前节点的类。
[4] 当所有节点都完成[3],就完成了一次迭代,重复多次迭代。
特点
Chinese Whispers算法具有计算速度快,需要设置的参数少的特点,比较适合通用文本的聚类任务。
选择算法
经过算法层面的分析和实际使用的经验,Chinese Whispers更符合预期的目标:较少而且灵活的参数,计算速度快。
计算过程优化
在Chinese Whisper算法中,建立图的过程涉及到给每个节点建立邻居节点,使用两种召回方案,然后将结果合并,作为同一聚簇的候选。
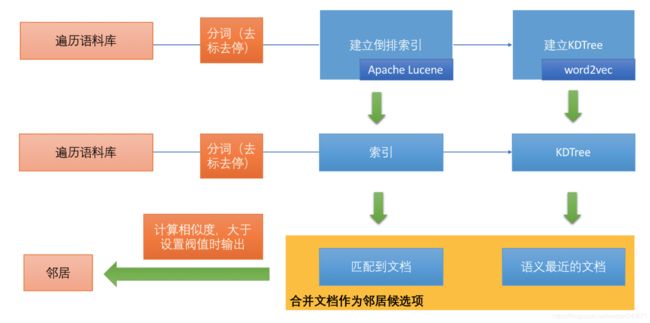
倒排索引保证了召回到最匹配的若干文档,KDTree则是建立从向量空间召回到语义距离“最近”的文档。然后将二者结果合并,最后计算这些候选项与当前文档的相似度,这里会设定一个阀值,根据聚类任务的需要设定便可,比如0.4为宽泛的相等,0.7以上为基本相等。0.9则为相等。
聚类API设计
聚类任务通常用于处理大量文本的聚类工作。当数据量超过1w时,就会变成长时任务,比如,客户每天会产生1w的日志,每天都会进行聚类分析,那么就需要支持异步处理。同时,每个聚类都有其明显特点,需要在返回结果中,返回这个聚簇的关键词。另外,不同部门数据也要同时处理,所以,还需要支持同时处理多个聚类任务。
基于以上需求,聚类API包括:
1)提交聚类任务;
2)查询聚类任务执行状态;
3)取回聚类任务执行结果。
参考资料
AP(affinity propagation)聚类算法
CW聚类算法原理 – 译自《Chinese Whispers》论文
中文近义词:聊天机器人,智能问答工具包
