从源码角度分析-HashMap
文章从下面几点去分析HashMap(基于JDK1.8)
- HashMap的概念
- 工作原理
- hashCode()和equals()的作用分别是什么
- 扩容机制
1、HashMap的概念
HashMap是基于Map接口实现,以键值对的形式存储,键值允许null值,存储是无序的,非同步的。下面提供官方文档中的描述:
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
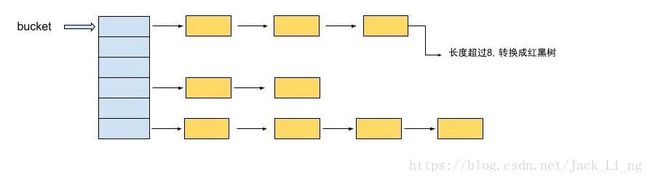
2、接下来开始分析源码,从源码中去理解hashCode()和equals()的区别与作用,从put函数开始
public V put(K key, V value) {
//先对key进行hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//第一次创建时tab为null,
if ((tab = table) == null || (n = tab.length) == 0)
//resize进行扩容
n = (tab = resize()).length;
//对key的hashCode进行hash后,判断当前bucket的位置是否存在
//若为null直接添加
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
//若key已经存在,直接替换原来的值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//是否为树
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//添加到链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//是否超过链表的阈值,默认为TREEIFY_THRESHOLD=8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//超过当前bucket的阈值,进行resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 上面代码分析
首先,先对key的hashCode进行hash,然后计算bucket的位置index,(bucket指的是tab)。判断是否发生碰撞:若没有,直接放在bucket中;若发生了碰撞,则以链表的形式存在bucket后。如果链表的长度大于或等于预定的阈值TREEIFY_THRESHOLD,那么链表会转为红黑树。如果节点已经存在了,会替换掉原来的value。最后会判断bucket的阈值是否超过threshold(CAPACITY*loadFactor —CAPACITY表示bucket的容量,loadFactor是负载因子(默认是0.75)),如果超过了就进行resize。大概流程图如下:
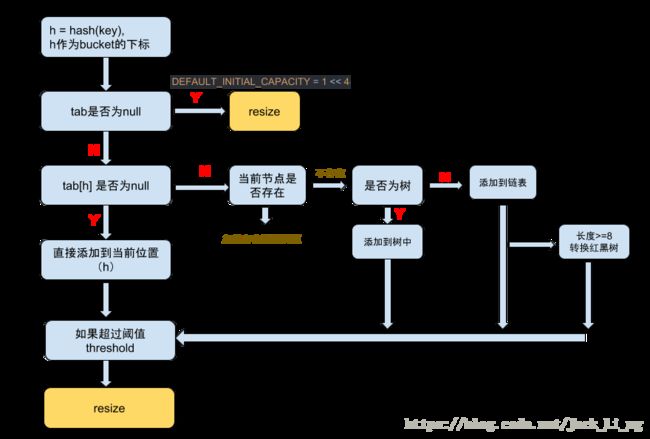
接下来看get函数
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果是第一个,那么直接获取
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//从红黑树中查找
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
//从链表中查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
} 在get函数中,也是先对key进行hash,然后判断是否处于bucket中的第一位置,若果是,直接返回值;如果不是,先判断是否为红黑树,是红黑树就在树中查找,否则,在链表中查找。无论是树还是链表,查找的过程通过key.equals(k)来确定是否为查找的具体值。时间复杂度:树是O(logn),链表是O(n)。
在put和get函数时,都涉及到了hash,下面借助网上一张图表明hash的过程
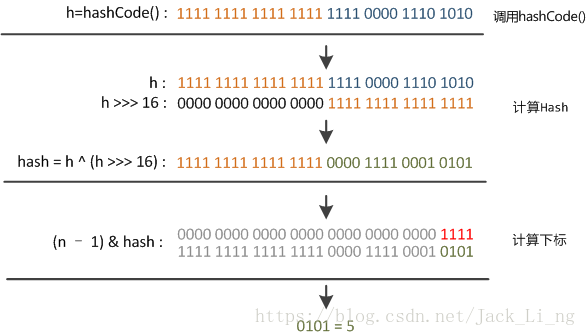
3、扩容机制,先看下resize的源码
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//最大容量,如果超过了,只能让它随便碰撞了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//没有超过最大容量,扩容为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//计算新的容量上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
//把原来bucket中的数据到新的bucket
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
//原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//以原索引放在bucket中
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//原索引+oldCap放在bucket中
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} 从上面代码中发现,HashMap在实行扩容的时候,在do while循环中对hash进行位运算,等于0的时候,索引不变,否则,在新的bucket中索引的位置是原索引+旧容量。