卡方检验
卡方检验是一种基于χ2分布的假设检验方法,其应用十分广泛,特别是在离散变量的分析中,χ2分布最早于1875年由F.Helmet提出,他计算出来自正态总体的样本方差分布服从χ2分布,1900年Karl Pearson在做拟合优度研究时也得出χ2分布,并且提出χ2统计量,将其用于假设检验。
【卡方检验的主要用途包括以下几个方面】
1.检验某个连续变量的分布是否与某种理论分布相一致。如是否符合正态分布、是否服从均匀分布、是否服从Poisson分布等
2.某无序分类变量各属性出现的概率是否等于指定概率,如骰子各面出现的概率是否等于1\6,硬币正反两面是否等于0.5等
3.检验两个无序分类变量之间是否独立,有无关联,如收入与性别是否有关。
4.控制某种分类因素之后,检验两个无序分类变量各属性之间是否独立,如上述控制年龄因素之后,收入与性别是否有关,
5.检验两个或多个样本率(总体率)或构成比之间是否存在差别,也称为同质性检验。
6.多个样本(总体)之间的多重比较
7.不同的方法作用于同一个变量时,产生的效果是否一致(配对检验)。如两种治疗方法作用于同一组病人,疗效是否一样
在以上用途中,除了第一点是针对连续变量之外,其余都是针对无序分类变量,由此可见,卡方检验大部分是用在分类变量的检验中发挥作用。
==================================================
【卡方检验基本思想】
卡方检验是以渐进χ2分布为基础,它的零假设H0是:观察频数与期望频数没有差别。
通过构造χ2统计量,得出P值,并以此进行检验。
应该来讲,凡是通过构造χ2统计量进行检验的都属于卡方检验,卡方检验是一类检验(希腊字母χ的英文音标就近似读为“卡”),我们在描述这些不同的卡方检验的时候,通常会加上特定名称来加以区分,如Pearson卡方、McNemar配对卡方、似然比卡方等。由于是pearson最早提出用卡方统计量做假设检验,所以我们平时说的卡方检验,很多时候就是指pearson卡方。
=======================================
【χ2统计量的计算及意义】
χ2统计量实际上表示观测值与理论值之间的偏离程度,其公式为
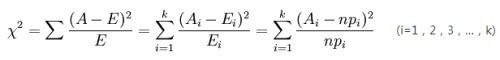
其中,Ai为i水平的观察频数,Ei为i水平的期望频数,n为总频数,pi为i水平的期望频率。i水平的期望频数Ti等于总频数n×i水平的期望概率pi,k为单元格数。当n比较大时,χ2统计量近似服从k-1(计算Ei时用到的参数个数)个自由度的卡方分布。
由卡方的计算公式可知,当观察频数与期望频数完全一致时,χ2值为0;观察频数与期望频数越接近,两者之间的差异越小,χ2值越小;反之,观察频数与期望频数差别越大,两者之间的差异越大,χ2值越大。换言之,大的χ2值表明观察频数远离期望频数,即表明远离假设。小的χ2值表明观察频数接近期望频数,接近假设。一旦χ2超过了一定的临界值,就可以认为观察频数与期望频数的差异超出了抽样误差允许的范围,也就可以认定二者是有差异的。因此,χ2是观察频数与期望频数之间距离的一种度量指标,也是假设成立与否的度量指标。如果χ2值“小”,研究者就倾向于不拒绝H0;如果χ2值大,就倾向于拒绝H0。至于χ2在每个具体研究中究竟要大到什么程度才能拒绝H0,则要借助于卡方分布求出所对应的P值来确定。
【卡方统计量具有以下特征】
1.χ2值永远不会小于0
2.χ2值具有可加性,几个相互独立的卡方变量的和仍然服从卡方分布
3.χ2值的大小随着观察频数和理论频数的大小而变化
======================================
【卡方检验的样本量要求】
卡方分布本身是连续型分布,但是在分类资料的统计分析中,显然频数只能以整数形式出现,因此计算出的统计量是非连续的。只有当样本量比较充足时,才可以忽略两者问的差异,否则将可能导致较大的偏差具体而言,一般认为对于卡方检验中的每一个单元格,要求其最小期望频数均大于1,且至少有4/5的单元格期望频数大于5,此时使用卡方分布计算出的概率值才是准确的。如果数据不符合要求,可以采用确切概率法进行概率的计算。
======================================
【其他一些基于卡方分布的检验】
上面讲到卡方检验是一类检验,person提出卡方检验思想之后,陆续又有很多人在此基础上进行拓展,形成了多种基于卡方分布的检验方法。
1.Yates校正
也叫做Yates卡方检验、Yates连续性校正。由英国人Frank Yates提出。Yates认为,卡方分布是一种连续型分布,但是分类资料计算出的统计量是离散的。在某个单元格的期望频数小于5时,会使χ2统计量渐进卡方分布的假设不可信,因此需要做连续性校正,在每个单元格的残差中减去0.5
公式为:
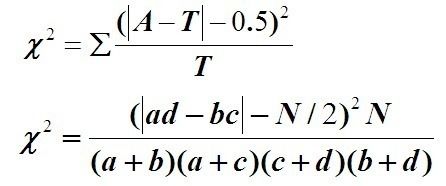
其中A为观察频数,T为期望频数
Yayes校正有一定的使用条件
1.是适用于交叉列联表(2×2列联表)
2.样本量n大于40
3.所有单元格的期望频数大于1
4.有1/5以下的单元表期望频数小于5
应该来讲,Yates的观点是有道理的,但问题在于经过校正之后的P值有可能过分保守,也就是说有可能会犯Ⅱ型错误(H0为假而未拒绝),因此在样本量很小的情况下,没必要做Yates校正。在样本量充足的情况下,可以做Yates校正,并建议将结果同未校正相比较,如不一致,可能需要谨慎对待或重新设计分析方法。
2.似然比检验(Likelihood Ratio Test)
简称LRT,和Pearson卡方一样,LRT也是假设行列变量间相互独立,也是构造χ2统计量,服从渐进卡方分布,但区别在于LRT计算卡方统计量的公式不一样。
似然比检验的基本思想是:
如果参数约束是有效的,那么加上这样的约束不应该引起似然函数最大值的大幅度降低。也就是说似然比检验的实质是在比较有约束条件下的似然函数最大值与无约束条件下似然函数最大值。似然比定义为有约束条件下的似然函数最大值与无约束条件下似然函数最大值之比。
以似然比为基础可以构造一个服从卡方分布统计量,因此,似然比检验也是基于卡方分布的检验
3.Fisher精确检验(Fisher's exact test)
也称为Fisher确切概率法,是由Fisher提出。由于pearson卡方、Yates校正、似然比都只是服从渐进卡方分布(有些统计软件如SPSS,在结果中显示的P值会标有“渐进”二字),当样本量不足或某单元格期望频数小于1时,这种渐进的假设有可能不成立,而Fisher精确检验并不基于渐进卡方分布,而是基于超几何分布,因此相比其他三种,其结果更为准确。
超几何分布:
超几何分布是一种离散概率分布。它描述了由有限个物件中抽出n个物件,成功抽出指定种类的物件的次数(不放回),实际上是一个不放回抽样。
Fisher精确检验计算方法:
Fisher精确检验的算法有两种:
1.一种是以实际观察到的交叉表所对应的概率大小为基准求相应概率的和,这种方法称为SF算法
2.另一种是以观察到的交叉表的实际频数和理论频数之差为基准求相应概率之和,这种方法称为TF算法
这两种计算方法在绝大多数情况下结果都是一样的,只是在超几何分布严重不对称的时候二者才会出现不一样的情况,而大多数统计软件如SPSS,SAS等都是采用SF算法,下面我们只介绍SF算法。
在四格表周边合计数固定不变的条件下,计算表内4个实际频数变动时的各种组合之概率Pi;再按检验假设用单侧或双侧的累计概率P,依据所取的检验水准α做出推断。
公式为:
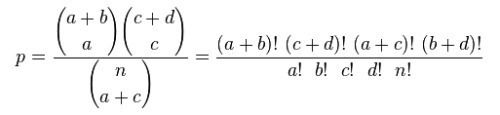
举例说明:
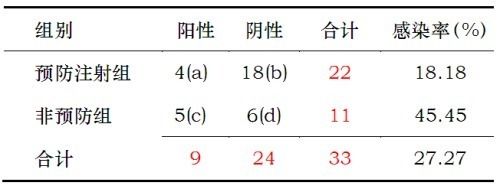
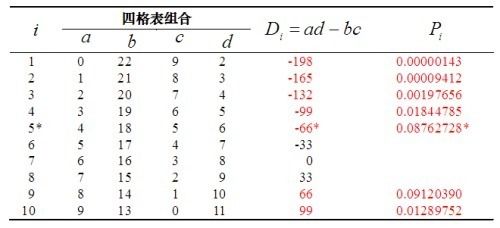
(1)各组合概率Pi的计算
在四格表周边合计数不变的条件下,表内4个实际频数 a,b,c,d 变动的组合数共有“周边合计中最小数+1”个。表内4个实际频数变动的组合数共有9+1=10个,依次为:

各组合的概率Pi服从超几何分布,其和为1
(2)累计概率的计算 ( 单、双侧检验不同)
设现有样本四格表中的交叉积差a*d*-b*c*=D*,其概率为P*,其余组合四格表的交叉积差记为Di,概率记为Pi
(1)单侧检验
若现有样本四格表中D*>0,须计算满足Di>=D*和Pi<=P*条件的各种组合下四格表的累计概率。若D*<0,则
计算满足Di<=D*和Pi>=P*条件的各种组合下四格表的累计概率。
(2)双侧检验
计算满足|Di|>=|D*|和Pi<=P*条件的各种组合下四格表的累计概率。若遇到a+b=c+d或a+c=b+d时,四格表内各种组合的序列呈对称分布,此时按单侧检验规定条件只计算单侧累计概率,然后乘以2即得双侧累计概率。
本例D*=-66 P*=0.08762728
计算同时满足Di>=66和Pi<=P*条件的四格表的累计概率。本例P1、P2、P3、P4、P5和P10满足条件,累计概率为P=P1+P2+P3+P4+P5+P10≈0.121>0.5,按α=0.05检验水准不拒绝H0
由于超几何分布穷尽了所有可能性,因此它计算出的结果更加准确,这种算法也有通用性,在r×c表格、配对表格也适用,但是缺点是计算量庞大,特别是对于较大的r×c表格,因此在样本量够大且单元格频数符合要求的情况下,我们可以用其他三种检验方法。但是随着计算机发展,这种缺点变得越来越小,在中等样本甚至多维列联表,也已经开始使用Fisher精确检验。
4.McNemar配对卡方检验
该检验方法主要用于配对样本,配对样本是对同一个样本采用不同的测量方法而得出的数据,因此对于配对样本主要分析不同测量方法之间是否存在差别。
McNemar配对卡方检验以Quinn McNemar的名字命名,其在1947年第一次提出此方法。主要用于对2×2列表的二分类性质进行分析,最常见的二分类性质就是是或否,阴或阳等相反的两种情况。如果是多分类性质,则需要使用Bowker检验,它是对McNemar检验的一般化及推广。
配对样本不宜使用Pearson卡方检验,原因有两点
1.Pearson卡方分析的是两个或多个独立样本之间的独立性或同质性,也就是对不同的样本采用相同的测量方法,而配对样本是同一样本采用不同的测量方法。
2.配对检验主要是分析不同测量方法之间的一致性或差异性,而Pearson卡方在针对两个以上不同样本的时候,分析的是不同样本间的差别,如果硬要使用Pearson卡方检验分析配对样本,则可能得出诸如“实验1中各个结果的频数分布在实验2的各个结果组中是不同的”这样的结论,这是没有多大价值的。因此在配对样本的检验中,要使用McNemar配对卡方检验和Kappa一致性检验,前者关注实验的差异性,后者关注实验的一致性。
基本思想:

图中显示了实验1和实验2,分别有正、负两种结果,这是典型的二分类配对样本,McNemar配对卡方检验的零假设是此交叉表符合边际同质化,即Pa+Pb=Pa+Pc和Pc+Pd=Pb+Pd,简化之后就是
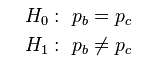
那么McNemar检验的统计量是
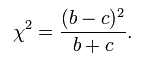
那么该如何理解这个统计量呢?为什么不是Pa+Pb=Pb+Pd和Pc+Pd=Pa+Pc呢?实际上在配对实验中,不外乎只有四种结果:
1.结果皆为正(a)
2.结果皆为负(d)
3.实验1正,实验2负(c)
4.实验1负,实验2正(b)
在这四种结果中,皆为正(a)和皆为负(d)这种一致的结果,对于分析实验没有任何贡献,我们主要是分析一正一负的这种差异情况。
McNemar检验的统计量也可以按照Pearson卡方的思想计算得出,过程如下:
设随机变量α和β如下
α=0,实验1 正
α=1,实验1 负
β=0,试验2 正
β=1,试验2 负
McNemar检验实际上是检验如下零假设和备择假设:
H0:P(α=1)=P(β=1)
H1:P(α≠1)=P(β≠1)
假定(a,b,c,d)服从参数为(p1,p2,p3,p4)的多项分布,结合H0对p1,p2,p3,p4中独立参数进行极大似然估计可得(p1,p2,p3,p4)的估计量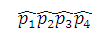 ,按照Pearson卡方的思想构造统计量为:
,按照Pearson卡方的思想构造统计量为:
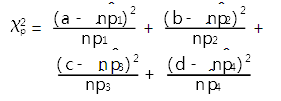 (公式1)
(公式1)
当(a,b,c,d)服从参数为(p1,p2,p3,p4)的多项分布,并且H0成立时,渐近服从自由度为1的分布,H0成立时,我们认为实验1和实验2的结果是相同的,也就是两个实验没有差别,出现正或负的概率服从B(n,0.5)分布,因此可以算得
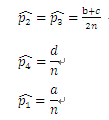
代入上述公式1得出
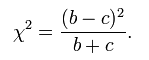
可见McNemar检验和Pearson卡方检验统计量和渐近分布是相同的,二者具有同一性。由上也可以得知,既然我们只关注二者结果不一致的情况,那么交叉表如何构造是没有影响的,而有些文献说McNemar检验只会利用非主对角线单元格上的信息,我认为是不严谨的,这等于无形当中固定了交叉表的构造,而实际上并不是每个交叉表的非主对角线上的信息都是不一致的,例如下面的这个情况,
实验1 正 实验1 负
实验2 负 a b
实验2 正 c d
所以我们还是要从本质上去理解McNemar检验统计量。
当b或c的值太小时(b+c<25),χ2不能满足服从渐近卡方分布的假设,这时,需要使用一个更精确的二项分布检验
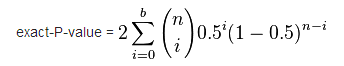
Edwards也提出了连续修正版本的McNemar检验统计量
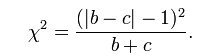
McNemar配对卡方检验在使用时,需要注意以下几点:
1.大样本性
和Pearson卡方一样,McNemar检验也是服从渐近卡方分布,因此样本量不能太小,至少要大于100
2.单元格频数不能小于5
和Pearson卡方一样,各单元格频数要求至少大于5,如有不符合条件的单元格,首先应考虑增加样本以满足需求,如果因条件所限无法增加样本,可考虑使用修正的McNemar检验,但是似乎所有的修正检验都有矫枉过正的嫌疑,因此不作为第一选择。
3.由于McNemar检验是假定(a,b,c,d)服从参数为(p1,p2,p3,p4)的多项分布,因此在收集数据时,要注意随机性,不要人为干预。
======================================
【卡方检验使用方法】
1.适合度检验
实际执行试验而得到的观察次数,与虚无假设的期望次数相比较,称为卡方适度检验或拟合优度检验,即在于检验二者接近的程度,利用样本数据以检验总体分布是否为某一特定分布的统计方法。这点对于连续变量,可以做总体分布检验(参数或非参数检验),如正态性检验,对于离散变量(分类变量),也可以检验某无序分类变量各属性出现的概率是否等于指定概率,注意:这里必须要为无序分类变量,且不能为二分类变量,因为有序分类变量和二分类变量各自均有更好的检验方法,卡方检验对这两类变量的检验结果误差较大。
卡方适度性检验主要用于单个变量的各个属性,如果是两个及以上变量,需要使用下面介绍的另一种卡方检验方法。
卡方检验做连续变量的分布检验我在正态性检验那篇文章中有所介绍,就不再多讲,这里主要介绍一下离散变量的适合度检验。
【例】 假设掷一骰子120次,各点数共出现次数为a,b为各点数出现的期望值120×1/6=20,如图所示。

在这里,1-6这六种点数可以看成是骰子的属性,理论上这六种点数出现的概率相同,均为1/6,我们以此进行假设检验
零假设H0:观察分布等于期望分布(或实际与理论一致)
备择假设H1:观察分布不等于期望分布
计算卡方检验统计量,如图右侧
D2=(B2-C2)^2/C2
D8=SUM(D2:D7)
确定自由度,(6-1)×(2-1)=5;选择显著水平α=0.05。
利用Excel提供的CHIINV函数求临界值,在D9单元格中键入“=CHIINV(0.05,5)”按回车键,得临界值11.07。
比较临界值和统计量,11.07>2.3,即临界值大于统计量,故差异不显著,接受H0
2.两个无序分类变量各属性之间的独立性检验
我们知道卡方适度性检验是分析样本和总体之间接近程度,这也可以推广到样本与样本间进行比较。样本和样本间的比较主要涉及独立性和同质性两方面,两个及以上变量间各属性的观察值,通常可以归纳为一个r×c的表格,我们称为列联表,最常见的2×2列联表,也叫做交叉列联表或交叉表。前面提到过,卡方检验对样本量有一定的要求,实际上不仅如此,它对分类变量的类型也有要求,例如二分类变量、有序分类变量等,这些变量使用卡方检验并不是最佳选择,最适合用卡方检验的变量是无序分类变量,因此我们在使用的时候要注意变量类型,不能盲目使用。
【例】某机构欲了解现在性别与收入是否有关,他们随机抽样500人,询问对此的看法。该问题中涉及的变量有两个,分别是性别和看法,其中性别变量有两个属性(男,女),看法变量有三个属性(有关,无关,不知道),现将数据整理成列联表,如图抽样数据

零假设H0:性别与收入无关。
备择假设H1:性别与收入有一定关系
确定自由度为(3-1)×(2-1)=2,选择显著水平α=0.05。
求解男女对收入与性别相关不同看法的期望次数,这里采用所在行列的合计值的乘机除以总计值来计算每一个期望值,如图4所示,在单元格B9中键入“=B5*E3/E5”,同理(第一个等于号理解为在单元格中键入):
B10=“=B5*E4/E5”,
C9=“=C5*E3/E5”,
C10=“=C5*E4/E5”,
D9=“=D5*E3/E5”,
D10=“=D5*E4/E5”。
利用卡方统计量计算公式计算统计量,在单元格B15中键入“=(B3-B9)^2/B9”,其余单元格依次类推,结果如图所示。
最终根据卡方公式计算出的χ2值为21.4675
利用Excel提供的CHIINV函数计算显著水平为0.05,自由度为2卡方分布的临界
值,在Excel单元格中键入“=CHIINV(0.05,2)”按回车键,得临界值为5.9915。
比较统计量度和临界值,统计量21.4675大于临界值5.9915,故拒绝零假设,也就是性别和收入是有一定关系的。
3.两个无序分类变量各属性之间的同质性检验
两个无序分类变量各属性之间的同质性检验实际上就是适度性检验的推广,适度性检验是观察频数和期望频数的比较,是单样本检验,而一致性检验是一个样本变量的观察频数和另一个样本变量观察频数的比较,是双样本检验。
【例】某咨询公司想了解南京和北京的市民对最低生活保障的满意程度是否相同。他们从南京抽出600居民,北京抽取600居民,每个居民对满意程度(非常满意、满意、不满意、非常不满意)任选一种,且只能选一种。将统计结果键入Excel工作表中,如图所示

下面是利用Excel解决此问题的步骤。
(1)零假设H0:南京和北京居民对最低生活保障满意程度的比例相同。
(2)确定自由度为(4-1)×(2-1)=3,选择显著水平α=0.05。
(3)求解卡方检验的l临界值,在Excel单元格中键入“=CHIINV(0.05,3)”,按回
车键得临界值为7.81。
(4)计算北京和南京不同满意程度的期望值,在单元格B11和C11中分别键入“=$B$7*D3/$D$7”和“=$C$7*D3/$D$7”,选中B11:C11,按住C11右下角填充控制点,填充至C14。
(5)计算卡方统计量,在单元格B19中键入“=(B3-B11)^2/B11”,其余单元格依次类推。
最终根据卡方公式计算出的χ2值为1.3875
(6)比较统计量和临界值,统计量1.3875小于临界值7.81,故接受零假设,也就是南京和北京居民对最低生活保障的满意度是一样的。
==============================================================
【总结】
前面介绍了Pearson卡方检验和一些基于卡方分布的其他检验,他们都有各自的适用范围和使用条件,现在来总结归纳一下
1.Pearson卡方检验
适用于无序分类变量,且不能是二分类变量和配对样本,样本量大于40,所有单元格的期望频数大于1,且至少有4/5的单元格期望频数大于5
2.Yates校正
只适用于2×2列联表,要求无序分类变量,且不能是二分类变量和配对样本,样本量大于40,所有单元格的期望频数大于1,有1/5以下的单元表期望频数小于5,它是Pearson卡方检验的连续校正
3.似然比检验
多数情况下与Pearson卡方结果一致,多用在处理多维表
4.Fisher精确检验
在Pearson卡方和Yates校正都无法使用的时候使用,也就是样本量小于40,或有单元格期望频数小于1
5.McNemar配对卡方检验
配对样本,只适用于2×2列联表,且差异之和(b+c)大于25,当b+c小于25或者维度超过2×2的时候,需要使用Bowker检验进行校正或者直接使用Fisher精确检验
应该说,基于卡方分布的检验对于样本量都是有要求的,越大效果越好,并且当有单元格频数小于1或超过1/5的单元表期望频数小于5的时候,处理方法有三种
1.首先考虑增加样本量,增大样本量可以增加单元格频数,且不会损坏任何数据信息,是最直接最有效的解决办法,但是有时候受外界条件限制导致无法做到
2.其次可以使用Fisher确切概率法,在无法增加样本量的情况下,可以选择使用Fisher确切概率法,因为该方法对于样本量和单元格频数不敏感,得出的结果会比较稳健
3.删除或合并理论频数太小的行或列,这样做会损坏样本随机性,破坏数据信息,且有时候受变量特征限制不能随意合并,如不同年龄组可以合并,但是不同血型就不能合并,因此删除或合并是在其他方法无法实现的情况下,才考虑的一种做法。