Android OkHttp 源码解析 - 拦截器
一、前言
看一下 RealCall 中的拦截器排序:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors()); //自定义的应用拦截器,是一开始添加的所以可以截断请求和一些初始化拦截
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors()); //自定义网络拦截器,在真正请求前调用,可以拦截改变一切默认的参数。
}
interceptors.add(new CallServerInterceptor(forWebSocket)); //真正请求的拦截器
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
return chain.proceed(originalRequest);
} okhttp 中拦截器自定义拦截类型有两种:
Application Interceptor(应用拦截器):我们可以自定义设置 Okhttp 的拦截器之一。一次网络请求它只会执行一次拦截,而且它是第一个触发拦截的,这里拦截到的 url 请求的信息都是最原始的信息。所以我们可以在该拦截器中添加一些我们请求中需要的通用信息,打印一些我们需要的日志。当然我们可以定义多个这样的拦截器,一个处理 header 信息,一个处理接口请求的加解密 。
Netwrok Interceptor(网络拦截器):NetwrokInterceptor 也是我们可以自定义的拦截器之一。它位于倒数第二层,会经过 RetryAndFollowIntercptor 进行重定向并且也会通过 BridgeInterceptor 进行 request 请求头和响应 resposne 的处理,因此这里可以得到的是更多的信息。在打印结果可以看到它内部重定向操作和失败重试,这里会有比 Application Interceptor 更多的日志。
关于二者的区别可以看 Android OkHttp 官方 Wiki 之 Interceptors 拦截器。
自定义拦截器可以看 OkHttp 拦截器的一些骚操作。
二、拦截器
下面我们看看 Okhttp 中默认的 5 个拦截器。
2.1、RetryAndFollowUpInterceptor
RetryAndFollowUpInterceptor 拦截器主要负责失败重连以及重定向,我们看下代码:
/**
* This interceptor recovers from failures and follows redirects as necessary. It may throw an
* {@link IOException} if the call was canceled.
*/
public final class RetryAndFollowUpInterceptor implements Interceptor {
/**
* How many redirects and auth challenges should we attempt? Chrome follows 21 redirects; Firefox,
* curl, and wget follow 20; Safari follows 16; and HTTP/1.0 recommends 5.
*/
//最大恢复追逐次数:
private static final int MAX_FOLLOW_UPS = 20;
public RetryAndFollowUpInterceptor(OkHttpClient client, boolean forWebSocket) {
this.client = client;
this.forWebSocket = forWebSocket;
}
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
// 三个参数分别对应:(1)全局的连接池,(2)连接线路Address, (3)堆栈对象
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
int followUpCount = 0;
Response priorResponse = null;
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response = null;
boolean releaseConnection = true;
try {
// 执行下一个拦截器,即BridgeInterceptor
// 这里有个很重的信息,即会将初始化好的连接对象传递给下一个拦截器,也是贯穿整个请求的连击对象,
// 上面我们说过,在拦截器执行过程中,RealInterceptorChain的几个属性字段会一步一步赋值
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
// 如果有异常,判断是否要恢复
if (!recover(e.getLastConnectException(), false, request)) {
throw e.getLastConnectException();
}
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
// 检查是否符合要求
Request followUp = followUpRequest(response);
if (followUp == null) {
if (!forWebSocket) {
streamAllocation.release();
}
// 返回结果
return response;
}
//不符合,关闭响应流
closeQuietly(response.body());
// 是否超过最大限制
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
// 是否有相同的连接
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(followUp.url()), callStackTrace);
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
request = followUp;
priorResponse = response;
}
}我们知道每个拦截器都实现了 interceptor 接口,interceptor.intercept() 方法就是子类用来处理自己的业务逻辑,所以我们仅仅需要分析这个方法即可。看源码我们得出了如下流程:
1 、根据 url 创建一个 Address 对象,初始化一个 Socket 连接对象,基于 Okio。
private Address createAddress(HttpUrl url) {
SSLSocketFactory sslSocketFactory = null;
HostnameVerifier hostnameVerifier = null;
CertificatePinner certificatePinner = null;
if (url.isHttps()) {
sslSocketFactory = client.sslSocketFactory();
hostnameVerifier = client.hostnameVerifier();
certificatePinner = client.certificatePinner();
}
return new Address(url.host(), url.port(), client.dns(), client.socketFactory(),
sslSocketFactory, hostnameVerifier, certificatePinner, client.proxyAuthenticator(),
client.proxy(), client.protocols(), client.connectionSpecs(), client.proxySelector());
}
2、用前面创建的 address 作为参数去实例化 StreamAllocation,PS:此处还没有真正的去建立连接,只是初始化一个连接对象。
3、开启一个 while(true) 循环。
4、如果取消,释放资源并抛出异常,结束流程。
5、执行下一个拦截器,一般是 BridgeInterceptor。
6、如果发生异常,走到 catch 里面,判断是否继续请求,不继续请求则退出。
7、如果 priorResponse 不为空,则说明前面已经获取到了响应,这里会结合当前获取的 Response 和先前的 Response。
8、调用 followUpRequest 查看响应是否需要重定向,如果不需要重定向则返回当前请求。
9、重定向次数+1,同时判断是否达到最大限制数量。是:退出。
10、检查是否有相同的链接,是:释放,重建创建。
11、重新设置 request,并把当前的 Response 保存到 priorResponse,继续 while 循环。
我们来看下重定向的判断 followUpRequest:
/**
* Figures out the HTTP request to make in response to receiving {@code userResponse}. This will
* either add authentication headers, follow redirects or handle a client request timeout. If a
* follow-up is either unnecessary or not applicable, this returns null.
*/
private Request followUpRequest(Response userResponse) throws IOException {
if (userResponse == null) throw new IllegalStateException();
Connection connection = streamAllocation.connection();
Route route = connection != null
? connection.route()
: null;
int responseCode = userResponse.code();
final String method = userResponse.request().method();
switch (responseCode) {
case HTTP_PROXY_AUTH:
Proxy selectedProxy = route != null
? route.proxy()
: client.proxy();
if (selectedProxy.type() != Proxy.Type.HTTP) {
throw new ProtocolException("Received HTTP_PROXY_AUTH (407) code while not using proxy");
}
return client.proxyAuthenticator().authenticate(route, userResponse);
case HTTP_UNAUTHORIZED:
return client.authenticator().authenticate(route, userResponse);
case HTTP_PERM_REDIRECT:
case HTTP_TEMP_REDIRECT:
// "If the 307 or 308 status code is received in response to a request other than GET
// or HEAD, the user agent MUST NOT automatically redirect the request"
if (!method.equals("GET") && !method.equals("HEAD")) {
return null;
}
// fall-through
case HTTP_MULT_CHOICE:
case HTTP_MOVED_PERM:
case HTTP_MOVED_TEMP:
case HTTP_SEE_OTHER:
// Does the client allow redirects?
if (!client.followRedirects()) return null;
String location = userResponse.header("Location");
if (location == null) return null;
HttpUrl url = userResponse.request().url().resolve(location);
// Don't follow redirects to unsupported protocols.
if (url == null) return null;
// If configured, don't follow redirects between SSL and non-SSL.
boolean sameScheme = url.scheme().equals(userResponse.request().url().scheme());
if (!sameScheme && !client.followSslRedirects()) return null;
// Most redirects don't include a request body.
Request.Builder requestBuilder = userResponse.request().newBuilder();
if (HttpMethod.permitsRequestBody(method)) {
final boolean maintainBody = HttpMethod.redirectsWithBody(method);
if (HttpMethod.redirectsToGet(method)) {
requestBuilder.method("GET", null);
} else {
RequestBody requestBody = maintainBody ? userResponse.request().body() : null;
requestBuilder.method(method, requestBody);
}
if (!maintainBody) {
requestBuilder.removeHeader("Transfer-Encoding");
requestBuilder.removeHeader("Content-Length");
requestBuilder.removeHeader("Content-Type");
}
}
// When redirecting across hosts, drop all authentication headers. This
// is potentially annoying to the application layer since they have no
// way to retain them.
if (!sameConnection(userResponse, url)) {
requestBuilder.removeHeader("Authorization");
}
return requestBuilder.url(url).build();
case HTTP_CLIENT_TIMEOUT:
// 408's are rare in practice, but some servers like HAProxy use this response code. The
// spec says that we may repeat the request without modifications. Modern browsers also
// repeat the request (even non-idempotent ones.)
if (userResponse.request().body() instanceof UnrepeatableRequestBody) {
return null;
}
return userResponse.request();
default:
return null;
}
}
这里主要是根据 响应码(code) 和 响应头(header) 查看是否需要重定向,并重新设置请求。当然,如果是正常响应则直接返回 Response 停止循环。
/**
* Report and attempt to recover from a failure to communicate with a server. Returns true if
* {@code e} is recoverable, or false if the failure is permanent. Requests with a body can only
* be recovered if the body is buffered or if the failure occurred before the request has been
* sent.
*/
private boolean recover(IOException e, boolean requestSendStarted, Request userRequest) {
streamAllocation.streamFailed(e);
// 1. 应用层配置不在连接,默认为true
// The application layer has forbidden retries.
if (!client.retryOnConnectionFailure()) return false;
// 2. 请求Request出错不能继续使用
// We can't send the request body again.
if (requestSendStarted && userRequest.body() instanceof UnrepeatableRequestBody) return false;
// 是否可以恢复的
// This exception is fatal.
if (!isRecoverable(e, requestSendStarted)) return false;
// 4. 没用更多线路可供选择
// No more routes to attempt.
if (!streamAllocation.hasMoreRoutes()) return false;
// For failure recovery, use the same route selector with a new connection.
return true;
}
private boolean isRecoverable(IOException e, boolean requestSendStarted) {
// If there was a protocol problem, don't recover.
if (e instanceof ProtocolException) {
return false;
}
// If there was an interruption don't recover, but if there was a timeout connecting to a route
// we should try the next route (if there is one).
if (e instanceof InterruptedIOException) {
return e instanceof SocketTimeoutException && !requestSendStarted;
}
// Look for known client-side or negotiation errors that are unlikely to be fixed by trying
// again with a different route.
if (e instanceof SSLHandshakeException) {
// If the problem was a CertificateException from the X509TrustManager,
// do not retry.
if (e.getCause() instanceof CertificateException) {
return false;
}
}
if (e instanceof SSLPeerUnverifiedException) {
// e.g. a certificate pinning error.
return false;
}
// An example of one we might want to retry with a different route is a problem connecting to a
// proxy and would manifest as a standard IOException. Unless it is one we know we should not
// retry, we return true and try a new route.
return true;
}
看上面代码可以这样理解:判断是否可以恢复,如果下面几种条件符合,则返回 true,代表可以恢复,如果返回 false,代表不可恢复。
- 应用层配置不在连接(默认为 true ),则不可恢复
- 请求 Request 是不可重复使用的 Request,则不可恢复
- 根据 Exception 的类型判断是否可以恢复的 ( isRecoverable() 方法)
3.1、如果是协议错误(ProtocolException)则不可恢复
3.2、如果是中断异常(InterruptedIOException)则不可恢复
3.3、如果是 SSL 握手错误(SSLHandshakeException && CertificateException)则不可恢复
3.4、certificate pinning错误(SSLPeerUnverifiedException)则不可恢复 - 没用更多线路可供选择 则不可恢复
如果上述条件都不满足,则这个 request 可以恢复
综上所述:一个循环来不停的获取 response。每循环一次都会获取下一个 request,如果没有,则返回 response,退出循环。而获取下一个 request 的逻辑,是根据上一个 response 返回的状态码,分别作处理。
2.2、BridgeInterceptor
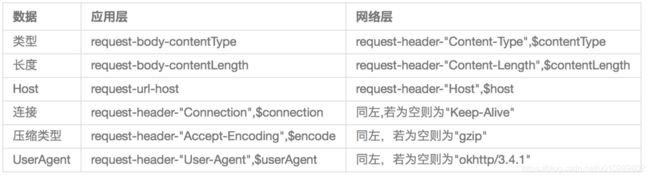
负责对Request和Response报文进行加工具体如下:
- 请求从应用层数据类型类型转化为网络调用层的数据类型。
- 将网络层返回的数据类型 转化为 应用层数据类型。
- 补充:Keep-Alive 连接:
区别如下图:
我们看下它的 intercept() 方法 :
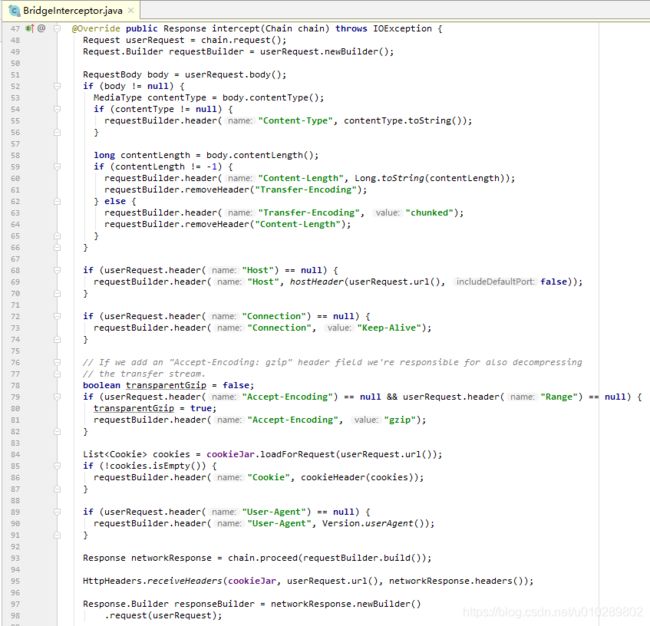

读了源码发现这个 interceptor 比较简单,可以分为发送请求和响应两个阶段来看:
1、在发送阶段 BridgeInterceptor 补全了一些 header 包括 Content-Type、Content-Length、Transfer-Encoding、Host、Connection、Accept-Encoding、User-Agent。
2、如果需要 gzip 压缩则进行 gzip 压缩。
3、加载 Cookie。
4、随后创建新的 request 并交付给后续的 interceptor 来处理,以获取响应。
5、首先保存 Cookie。
6、如果服务器返回的响应 content 是以 gzip 压缩过的,则会先进行解压缩,移除响应中的 header Content-Encoding和Content-Length,构造新的响应返回。
7、否则直接返回 response。
其中* CookieJar来自 OkHttpClient*,他是OKHttp的Cookie管理类,负责Cookie的存取。
public interface CookieJar {
/** A cookie jar that never accepts any cookies. */
CookieJar NO_COOKIES = new CookieJar() {
@Override public void saveFromResponse(HttpUrl url, List cookies) {
}
@Override public List loadForRequest(HttpUrl url) {
return Collections.emptyList();
}
};
/**
* Saves {@code cookies} from an HTTP response to this store according to this jar's policy.
*
* Note that this method may be called a second time for a single HTTP response if the response
* includes a trailer. For this obscure HTTP feature, {@code cookies} contains only the trailer's
* cookies.
*/
void saveFromResponse(HttpUrl url, List cookies);
/**
* Load cookies from the jar for an HTTP request to {@code url}. This method returns a possibly
* empty list of cookies for the network request.
*
* Simple implementations will return the accepted cookies that have not yet expired and that
* {@linkplain Cookie#matches match} {@code url}.
*/
List loadForRequest(HttpUrl url);
}
由于 OKHttpClient 默认的构造过程可以看到,OKHttp 默认是没有提供 Cookie 管理功能的,所以如果想增加 Cookie 管理需要重写里面的方法,PS:如果重写 CookieJar() 需要注意 loadForRequest() 方法的返回值不能为 null。
public static void receiveHeaders(CookieJar cookieJar, HttpUrl url, Headers headers) {
// 没有配置,不解析
if (cookieJar == CookieJar.NO_COOKIES) return;
// 此处遍历,解析Set-Cookie的值,比如max-age
List cookies = Cookie.parseAll(url, headers);
if (cookies.isEmpty()) return;
// 然后保存,即自定义
cookieJar.saveFromResponse(url, cookies);
}
2.3、CacheInterceptor
CacheInterceptor 负责将请求和返回关联的保存到缓存中。客户端和服务器根据一定的机制(策略CacheStrategy ),在需要的时候使用缓存的数据作为网络响应,节省了时间和宽带。
老规矩上源码:
@Override public Response intercept(Chain chain) throws IOException {
//1、如果配置了缓存,则从缓存中取出(可能为null)
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
//2、获取缓存的策略.
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
//3、监测缓存
if (cache != null) {
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// If we're forbidden from using the network and the cache is insufficient, fail.
//4、如果禁止使用网络(比如飞行模式),且缓存无效,直接返回
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
//5、如果缓存有效,使用网络,不使用网络
// If we don't need the network, we're done.
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
Response networkResponse = null;
try {
//6、如果缓存无效,执行下一个拦截器
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
//7、本地有缓存、根据条件判断是使用缓存还是使用网络的response
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
//这个response是用来返回的
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
//8、把response缓存到本地
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
// The cache cannot be written.
}
}
}
return response;
}简单的说下上述流程:
1、如果配置了缓存,则从缓存中取出(可能为null)。
2、获取缓存的策略。
3、监测缓存。
4、如果禁止使用网络(比如飞行模式),且缓存无效,直接返回。
5、如果缓存有效,使用网络,不使用网络。
6、如果缓存无效,执行下一个拦截器。
7、本地有缓存、根据条件判断是使用缓存还是使用网络的response。
8、把response缓存到本地。
大体流程分析完,那么咱们再详细分析下。
1、原理
(1)、okhttp 的网络缓存是基于 http 协议。
(2)、使用 DiskLruCache 的缓存策略。
2、注意事项:
(1)、目前只支持 GET,其他请求方式需要自己实现。
(2)、需要服务器配合,通过 head 设置相关头来控制缓存。
(3)、创建 OkHttpClient 时候需要配置 Cache。
缓存实际上是一个比较复杂的逻辑,单独的功能块,实际上不属于 OKhttp 上的功能,实际上是通过是 http 协议和 DiskLruCache 做了处理。
2.4、ConnectInterceptor
顾名思义连接拦截器,这才是真行的开始向服务器发起器连接。看下这个类的代码:
/** Opens a connection to the target server and proceeds to the next interceptor. */
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
主要看下 ConnectInterceptor() 方法,里面代码已经很简单了,受限了通过 streamAllocation 的 newStream 方法获取一个流(HttpCodec 是个接口,根据协议的不同,由具体的子类的去实现),第二步就是获取对应的 RealConnection。StreamAllocation 的 newStream() 内部其实是通过 findHealthyConnection() 方法获取一个 RealConnection,而在 findHealthyConnection() 里面通过一个 while(true) 死循环不断去调用 findConnection() 方法去找 RealConnection。而在 findConnection() 里面其实是真正的寻找 RealConnection,而上面提到的 findHealthyConnection() 里面主要就是调用 findConnection() 然后去验证是否是"健康"的。在 findConnection() 里面主要是通过3重判断:
1、如果有已知连接且可用,则直接返回。
2、如果在连接池有对应address的连接,则返回。
3、切换路由再在连接池里面找下,如果有则返回。
如果上述三个条件都没有满足,则直接new一个RealConnection。然后开始握手,握手结束后,把连接加入连接池,如果在连接池有重复连接,和合并连接。至此 findHealthyConnection() 就分析完毕,给大家看下大缩减后的代码:
//StreamAllocation.java
public HttpCodec newStream(OkHttpClient client, boolean doExtensiveHealthChecks) {
// 省略代码
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, connectionRetryEnabled, doExtensiveHealthChecks);
HttpCodec resultCodec = resultConnection.newCodec(client, this);
// 省略代码
}
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, boolean connectionRetryEnabled, boolean doExtensiveHealthChecks)
throws IOException {
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
connectionRetryEnabled);
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
noNewStreams();
continue;
}
return candidate;
}
}
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
//省略部分代码
//条件1如果有已知连接且可用,则直接返回
RealConnection allocatedConnection = this.connection;
if (allocatedConnection != null && !allocatedConnection.noNewStreams) {
return allocatedConnection;
}
//条件2 如果在连接池有对应address的连接,则返回
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
return connection;
}
selectedRoute = route;
}
// 条件3切换路由再在连接池里面找下,如果有则返回
if (selectedRoute == null) {
selectedRoute = routeSelector.next();
}
RealConnection result;
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
Internal.instance.get(connectionPool, address, this, selectedRoute);
if (connection != null) return connection;
route = selectedRoute;
refusedStreamCount = 0;
//以上条件都不满足则new一个
result = new RealConnection(connectionPool, selectedRoute);
acquire(result);
}
// 开始握手
result.connect(connectTimeout, readTimeout, writeTimeout, connectionRetryEnabled);
//计入数据库
routeDatabase().connected(result.route());
Socket socket = null;
synchronized (connectionPool) {
//加入连接池
Internal.instance.put(connectionPool, result);
// 如果是多路复用,则合并
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
return result;
}
这里再简单的说下 RealConnection 的 connect(),因为这个方法也很重要。不过大家要注意 RealConnection 的 connect() 是 StreamAllocation 调用的。在 RealConnection 的 connect() 的方法里面也是一个 while(true) 的循环,里面判断是隧道连接还是普通连接,如果是隧道连接就走 connectTunnel(),如果是普通连接则走 connectSocket(),最后建立协议。connectSocket() 方法里面就是通过 okio 获取 source 与 sink。establishProtocol() 方法建立连接咱们说下,里面判断是是 HTTP/1.1 还是 HTTP/2.0。如果是 HTTP/2.0 则通过 Builder 来创建一个 Http2Connection 对象,并且调用 Http2Connection 对象的 start() 方法。所以判断一个 RealConnection 是否是 HTTP/2.0 其实很简单,判断 RealConnection 对象的 http2Connection 属性是否为 null 即可,因为只有 HTTP/2 的时候 http2Connection才会被赋值。
2.5、CallServerInterceptor
上面我们已经成功连接到服务器了,那接下来要做什么那?相信你已经猜到了, 那就是发送数据了。在 OkHttp 里面读取数据主要是通过以下四个步骤来实现的:
- 写入请求头
- 写入请求体
- 读取响应头
- 读取响应体
OkHttp 的流程是完全独立的。同样读写数据是交给相关的类来处理,就是 HttpCodec(解码器)来处理。
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
long sentRequestMillis = System.currentTimeMillis();
//写入请求头
httpCodec.writeRequestHeaders(request);
Response.Builder responseBuilder = null;
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return what
// we did get (such as a 4xx response) without ever transmitting the request body.
if ("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
responseBuilder = httpCodec.readResponseHeaders(true);
}
//写入请求体
if (responseBuilder == null) {
// Write the request body if the "Expect: 100-continue" expectation was met.
Sink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength());
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
} else if (!connection.isMultiplexed()) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection from
// being reused. Otherwise we're still obligated to transmit the request body to leave the
// connection in a consistent state.
streamAllocation.noNewStreams();
}
}
httpCodec.finishRequest();
//读取响应头
if (responseBuilder == null) {
responseBuilder = httpCodec.readResponseHeaders(false);
}
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
//读取响应体
int code = response.code();
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
自此整个流程已经结束了。
三、连接机制
连接的创建是在 StreamAllocation 对象统筹下完成的,我们前面也说过它早在 RetryAndFollowUpInterceptor 就被创建了,StreamAllocation 对象主要用来管理两个关键角色:
- RealConnection:真正建立连接的对象,利用 Socket 建立连接。
- ConnectionPool:连接池,用来管理和复用连接。
在里初始化了一个 StreamAllocation 对象,我们说在这个 StreamAllocation 对象里初始化了一个 Socket 对象用来做连接,但是并没有。
3.1 创建连接
我们在前面的 ConnectInterceptor 分析中已经说过,ConnectInterceptor 用来完成连接。而真正的连接在 RealConnect 中实现,连接由连接池 ConnectPool 来管理,连接池最多保持 5 个地址的连接 keep-alive,每个 keep-alive 时长为 5 分钟,并有异步线程清理无效的连接。
主要由以下两个方法完成:
- HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
- RealConnection connection = streamAllocation.connection();
我们来具体的看一看。
StreamAllocation.newStream() 最终调动 findConnect() 方法来建立连接。
public final class StreamAllocation {
/**
* Returns a connection to host a new stream. This prefers the existing connection if it exists,
* then the pool, finally building a new connection.
*/
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
Route selectedRoute;
synchronized (connectionPool) {
if (released) throw new IllegalStateException("released");
if (codec != null) throw new IllegalStateException("codec != null");
if (canceled) throw new IOException("Canceled");
//1 查看是否有完好的连接
RealConnection allocatedConnection = this.connection;
if (allocatedConnection != null && !allocatedConnection.noNewStreams) {
return allocatedConnection;
}
//2 连接池中是否用可用的连接,有则使用
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
return connection;
}
selectedRoute = route;
}
//线程的选择,多IP操作
if (selectedRoute == null) {
selectedRoute = routeSelector.next();
}
//3 如果没有可用连接,则自己创建一个
RealConnection result;
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
// Now that we have an IP address, make another attempt at getting a connection from the pool.
// This could match due to connection coalescing.
Internal.instance.get(connectionPool, address, this, selectedRoute);
if (connection != null) {
route = selectedRoute;
return connection;
}
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
route = selectedRoute;
refusedStreamCount = 0;
result = new RealConnection(connectionPool, selectedRoute);
acquire(result);
}
//4 开始TCP以及TLS握手操作
result.connect(connectTimeout, readTimeout, writeTimeout, connectionRetryEnabled);
routeDatabase().connected(result.route());
//5 将新创建的连接,放在连接池中
Socket socket = null;
synchronized (connectionPool) {
// Pool the connection.
Internal.instance.put(connectionPool, result);
// If another multiplexed connection to the same address was created concurrently, then
// release this connection and acquire that one.
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
return result;
}
}整个流程如下:
1、查找是否有完整的连接可用:
- Socket没有关闭
- 输入流没有关闭
- 输出流没有关闭
- Http2连接没有关闭
2、连接池中是否有可用的连接,如果有则可用。
3、如果没有可用连接,则自己创建一个。
4、开始TCP连接以及TLS握手操作。
5、将新创建的连接加入连接池。
上述方法完成后会创建一个 RealConnection 对象,然后调用该方法的 connect() 方法建立连接,我们再来看看 RealConnection.connect() 方法的实现。
public final class RealConnection extends Http2Connection.Listener implements Connection {
public void connect(
int connectTimeout, int readTimeout, int writeTimeout, boolean connectionRetryEnabled) {
if (protocol != null) throw new IllegalStateException("already connected");
//线路选择
RouteException routeException = null;
List connectionSpecs = route.address().connectionSpecs();
ConnectionSpecSelector connectionSpecSelector = new ConnectionSpecSelector(connectionSpecs);
if (route.address().sslSocketFactory() == null) {
if (!connectionSpecs.contains(ConnectionSpec.CLEARTEXT)) {
throw new RouteException(new UnknownServiceException(
"CLEARTEXT communication not enabled for client"));
}
String host = route.address().url().host();
if (!Platform.get().isCleartextTrafficPermitted(host)) {
throw new RouteException(new UnknownServiceException(
"CLEARTEXT communication to " + host + " not permitted by network security policy"));
}
}
//开始连接
while (true) {
try {
//如果是通道模式,则建立通道连接
if (route.requiresTunnel()) {
connectTunnel(connectTimeout, readTimeout, writeTimeout);
}
//否则进行Socket连接,一般都是属于这种情况
else {
connectSocket(connectTimeout, readTimeout);
}
//建立https连接
establishProtocol(connectionSpecSelector);
break;
} catch (IOException e) {
closeQuietly(socket);
closeQuietly(rawSocket);
socket = null;
rawSocket = null;
source = null;
sink = null;
handshake = null;
protocol = null;
http2Connection = null;
if (routeException == null) {
routeException = new RouteException(e);
} else {
routeException.addConnectException(e);
}
if (!connectionRetryEnabled || !connectionSpecSelector.connectionFailed(e)) {
throw routeException;
}
}
}
if (http2Connection != null) {
synchronized (connectionPool) {
allocationLimit = http2Connection.maxConcurrentStreams();
}
}
}
/** Does all the work necessary to build a full HTTP or HTTPS connection on a raw socket. */
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
//根据代理类型的不同处理Socket
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
rawSocket.setSoTimeout(readTimeout);
try {
//建立Socket连接
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
ConnectException ce = new ConnectException("Failed to connect to " + route.socketAddress());
ce.initCause(e);
throw ce;
}
// The following try/catch block is a pseudo hacky way to get around a crash on Android 7.0
// More details:
// https://github.com/square/okhttp/issues/3245
// https://android-review.googlesource.com/#/c/271775/
try {
//获取输入/输出流
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
} catch (NullPointerException npe) {
if (NPE_THROW_WITH_NULL.equals(npe.getMessage())) {
throw new IOException(npe);
}
}
}
} 最终调用 Java 里的套接字 Socket 里的 connect() 方法。
3.2 连接池
我们知道在复杂的网络环境下,频繁的进行建立 Sokcet 连接(TCP 三次握手)和断开 Socket(TCP 四次分手)是非常消耗网络资源和浪费时间的,HTTP 中的 keepalive 连接对于降低延迟和提升速度有非常重要的作用。
复用连接就需要对连接进行管理,这里就引入了连接池的概念。Okhttp 支持 5 个并发 KeepAlive,默认链路生命为 5 分钟(链路空闲后,保持存活的时间),连接池由 ConectionPool 实现,对连接进行回收和管理。ConectionPool 在内部维护了一个线程池,来清理连接,如下所示:
public final class ConnectionPool {
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue(), Util.threadFactory("OkHttp ConnectionPool", true));
//清理连接,在线程池executor里调用。
private final Runnable cleanupRunnable = new Runnable() {
@Override
public void run() {
while (true) {
//执行清理,并返回下次需要清理的时间。
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
//在timeout时间内释放锁
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
} ConectionPool 在内部维护了一个线程池来清理链接,清理任务由 cleanup() 方法完成,它是一个阻塞操作,首先执行清理,并返回下次需要清理的间隔时间,调用调用 wait() 方法释放锁。等时间到了以后,再次进行清理,并返回下一次需要清理的时间,循环往复。
我们来看一看 cleanup() 方法的具体实现。
public final class ConnectionPool {
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
synchronized (this) {
//遍历所有的连接,标记处不活跃的连接。
for (Iterator i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
//1. 查询此连接内部的StreanAllocation的引用数量。
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
idleConnectionCount++;
//2. 标记空闲连接。
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
//3. 如果空闲连接超过5个或者keepalive时间大于5分钟,则将该连接清理掉。
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
//4. 返回此连接的到期时间,供下次进行清理。
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
//5. 全部都是活跃连接,5分钟时候再进行清理。
return keepAliveDurationNs;
} else {
//6. 没有任何连接,跳出循环。
cleanupRunning = false;
return -1;
}
}
//7. 关闭连接,返回时间0,立即再次进行清理。
closeQuietly(longestIdleConnection.socket());
return 0;
}
} 整个方法的流程如下所示:
- 查询此连接内部的 StreanAllocation 的引用数量。
- 标记空闲连接。
- 如果空闲连接超过 5 个或者 keepalive 时间大于 5 分钟,则将该连接清理掉。
- 返回此连接的到期时间,供下次进行清理。
- 全部都是活跃连接,5分钟时候再进行清理。
- 没有任何连接,跳出循环。
- 关闭连接,返回时间 0,立即再次进行清理。
在 RealConnection 里有个 StreamAllocation 虚引用列表,每创建一个 StreamAllocation,就会把它添加进该列表中,如果留关闭以后就将 StreamAllocation 对象从该列表中移除,正是利用这种引用计数的方式判定一个连接是否为空闲连接,
public final List> allocations = new ArrayList<>(); 查找引用计数由 pruneAndGetAllocationCount() 方法实现,具体实现如下所示:
public final class ConnectionPool {
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
//虚引用列表
List> references = connection.allocations;
//遍历虚引用列表
for (int i = 0; i < references.size(); ) {
Reference reference = references.get(i);
//如果虚引用StreamAllocation正在被使用,则跳过进行下一次循环,
if (reference.get() != null) {
//引用计数
i++;
continue;
}
// We've discovered a leaked allocation. This is an application bug.
StreamAllocation.StreamAllocationReference streamAllocRef =
(StreamAllocation.StreamAllocationReference) reference;
String message = "A connection to " + connection.route().address().url()
+ " was leaked. Did you forget to close a response body?";
Platform.get().logCloseableLeak(message, streamAllocRef.callStackTrace);
//否则移除该StreamAllocation引用
references.remove(i);
connection.noNewStreams = true;
// 如果所有的StreamAllocation引用都没有了,返回引用计数0
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs;
return 0;
}
}
//返回引用列表的大小,作为引用计数
return references.size();
}
}
四、缓存机制
4.1 缓存策略
在分析 Okhttp 的缓存机制之前,我们先来回顾一下 HTTP 与缓存相关的理论知识,这是实现 Okhttp 机制的基础。HTTP 的缓存机制也是依赖于请求和响应 header 里的参数类实现的,最终响应式从缓存中去,还是从服务端重新拉取,HTTP 的缓存机制的流程如下所示:

HTTP 的缓存可以分为两种:
- 强制缓存:需要服务端参与判断是否继续使用缓存,当客户端第一次请求数据是,服务端返回了缓存的过期时间(Expires与Cache-Control),没有过期就可以继续使用缓存,否则则不适用,无需再向服务端询问。
- 对比缓存:需要服务端参与判断是否继续使用缓存,当客户端第一次请求数据时,服务端会将缓存标识(Last-Modified/If-Modified-Since与Etag/If-None-Match)与数据一起返回给客户端,客户端将两者都备份到缓存中 ,再次请求数据时,客户端将上次备份的缓存 标识发送给服务端,服务端根据缓存标识进行判断,如果返回304,则表示通知客户端可以继续使用缓存。
强制缓存优先于对比缓存。
上面提到强制缓存使用的的两个标识:
- Expires:Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。到期时间是服务端生成的,客户端和服务端的时间可能有误差。
- Cache-Control:Expires有个时间校验的问题,所有HTTP1.1采用Cache-Control替代Expires。
Cache-Control的取值有以下几种:
- private: 客户端可以缓存。
- public: 客户端和代理服务器都可缓存。
- max-age=xxx: 缓存的内容将在 xxx 秒后失效
- no-cache: 需要使用对比缓存来验证缓存数据。
- no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发。
我们再来看看对比缓存的两个标识:
Last-Modified/If-Modified-Since
Last-Modified 表示资源上次修改的时间。
当客户端发送第一次请求时,服务端返回资源上次修改的时间:
Last-Modified: Tue, 12 Jan 2016 09:31:27 GMT客户端再次发送,会在header里携带If-Modified-Since。将上次服务端返回的资源时间上传给服务端。
If-Modified-Since: Tue, 12 Jan 2016 09:31:27 GMT 服务端接收到客户端发来的资源修改时间,与自己当前的资源修改时间进行对比,如果自己的资源修改时间大于客户端发来的资源修改时间,则说明资源做过修改, 则返回200表示需要重新请求资源,否则返回304表示资源没有被修改,可以继续使用缓存。
上面是一种时间戳标记资源是否修改的方法,还有一种资源标识码ETag的方式来标记是否修改,如果标识码发生改变,则说明资源已经被修改,ETag优先级高于Last-Modified。
Etag/If-None-Match
ETag是资源文件的一种标识码,当客户端发送第一次请求时,服务端会返回当前资源的标识码:
ETag: "5694c7ef-24dc"客户端再次发送,会在header里携带上次服务端返回的资源标识码:
If-None-Match:"5694c7ef-24dc"服务端接收到客户端发来的资源标识码,则会与自己当前的资源吗进行比较,如果不同,则说明资源已经被修改,则返回200,如果相同则说明资源没有被修改,返回 304,客户端可以继续使用缓存。
以上便是HTTP缓存策略的相关理论知识,我们来看看具体实现。
Okhttp的缓存策略就是根据上述流程图实现的,具体的实现类是CacheStrategy,CacheStrategy的构造函数里有两个参数:
CacheStrategy(Request networkRequest, Response cacheResponse) {
this.networkRequest = networkRequest;
this.cacheResponse = cacheResponse;
}这两个参数参数的含义如下:
- networkRequest:网络请求。
- cacheResponse:缓存响应,基于DiskLruCache实现的文件缓存,可以是请求中url的md5,value是文件中查询到的缓存,这个我们下面会说。
CacheStrategy就是利用这两个参数生成最终的策略,有点像map操作,将networkRequest与cacheResponse这两个值输入,处理之后再将这两个值输出,们的组合结果如下所示:
- 如果networkRequest为null,cacheResponse为null:only-if-cached(表明不进行网络请求,且缓存不存在或者过期,一定会返回503错误)。
- 如果networkRequest为null,cacheResponse为non-null:不进行网络请求,而且缓存可以使用,直接返回缓存,不用请求网络。
- 如果networkRequest为non-null,cacheResponse为null:需要进行网络请求,而且缓存不存在或者过期,直接访问网络。
- 如果networkRequest为non-null,cacheResponse为non-null:Header中含有ETag/Last-Modified标签,需要在条件请求下使用,还是需要访问网络。
那么这四种情况是如何判定的,我们来看一下。
CacheStrategy 是利用 Factory 模式进行构造的,CacheStrategy.Factory 对象构建以后,调用它的 get() 方法即可获得具体的 CacheStrategy,CacheStrategy.Factory.get() 方法内部调用的是 CacheStrategy.Factory.getCandidate() 方法,它是核心的实现。如下所示:
public static class Factory {
private CacheStrategy getCandidate() {
//1. 如果缓存没有命中,就直接进行网络请求。
if (cacheResponse == null) {
return new CacheStrategy(request, null);
}
//2. 如果TLS握手信息丢失,则返回直接进行连接。
if (request.isHttps() && cacheResponse.handshake() == null) {
return new CacheStrategy(request, null);
}
//3. 根据response状态码,Expired时间和是否有no-cache标签就行判断是否进行直接访问。
if (!isCacheable(cacheResponse, request)) {
return new CacheStrategy(request, null);
}
//4. 如果请求header里有"no-cache"或者右条件GET请求(header里带有ETag/Since标签),则直接连接。
CacheControl requestCaching = request.cacheControl();
if (requestCaching.noCache() || hasConditions(request)) {
return new CacheStrategy(request, null);
}
CacheControl responseCaching = cacheResponse.cacheControl();
if (responseCaching.immutable()) {
return new CacheStrategy(null, cacheResponse);
}
//计算当前age的时间戳:now - sent + age
long ageMillis = cacheResponseAge();
//刷新时间,一般服务器设置为max-age
long freshMillis = computeFreshnessLifetime();
if (requestCaching.maxAgeSeconds() != -1) {
//一般取max-age
freshMillis = Math.min(freshMillis, SECONDS.toMillis(requestCaching.maxAgeSeconds()));
}
long minFreshMillis = 0;
if (requestCaching.minFreshSeconds() != -1) {
//一般取0
minFreshMillis = SECONDS.toMillis(requestCaching.minFreshSeconds());
}
long maxStaleMillis = 0;
if (!responseCaching.mustRevalidate() && requestCaching.maxStaleSeconds() != -1) {
maxStaleMillis = SECONDS.toMillis(requestCaching.maxStaleSeconds());
}
//5. 如果缓存在过期时间内则可以直接使用,则直接返回上次缓存。
if (!responseCaching.noCache() && ageMillis + minFreshMillis < freshMillis + maxStaleMillis) {
Response.Builder builder = cacheResponse.newBuilder();
if (ageMillis + minFreshMillis >= freshMillis) {
builder.addHeader("Warning", "110 HttpURLConnection \"Response is stale\"");
}
long oneDayMillis = 24 * 60 * 60 * 1000L;
if (ageMillis > oneDayMillis && isFreshnessLifetimeHeuristic()) {
builder.addHeader("Warning", "113 HttpURLConnection \"Heuristic expiration\"");
}
return new CacheStrategy(null, builder.build());
}
//6. 如果缓存过期,且有ETag等信息,则发送If-None-Match、If-Modified-Since、If-Modified-Since等条件请求
//交给服务端判断处理
String conditionName;
String conditionValue;
if (etag != null) {
conditionName = "If-None-Match";
conditionValue = etag;
} else if (lastModified != null) {
conditionName = "If-Modified-Since";
conditionValue = lastModifiedString;
} else if (servedDate != null) {
conditionName = "If-Modified-Since";
conditionValue = servedDateString;
} else {
return new CacheStrategy(request, null); // No condition! Make a regular request.
}
Headers.Builder conditionalRequestHeaders = request.headers().newBuilder();
Internal.instance.addLenient(conditionalRequestHeaders, conditionName, conditionValue);
Request conditionalRequest = request.newBuilder()
.headers(conditionalRequestHeaders.build())
.build();
return new CacheStrategy(conditionalRequest, cacheResponse);
}
}整个函数的逻辑就是按照上面那个HTTP缓存判定流程图来实现,具体流程如下所示:
- 如果缓存没有命中,就直接进行网络请求。
- 如果TLS握手信息丢失,则返回直接进行连接。
- 根据response状态码,Expired时间和是否有no-cache标签就行判断是否进行直接访问。
- 如果请求header里有"no-cache"或者右条件GET请求(header里带有ETag/Since标签),则直接连接。
- 如果缓存在过期时间内则可以直接使用,则直接返回上次缓存。
- 如果缓存过期,且有ETag等信息,则发送If-None-Match、If-Modified-Since、If-Modified-Since等条件请求交给服务端判断处理
整个流程就是这样,另外说一点,Okhttp的缓存是根据服务器header自动的完成的,整个流程也是根据RFC文档写死的,客户端不必要进行手动控制。理解了缓存策略,我们来看看缓存在磁盘上是如何被管理的。
4.2 缓存管理
这篇文章我们来分析Okhttp的缓存机制,缓存机制是基于DiskLruCache做的。Cache类封装了缓存的实现,实现了InternalCache接口。InternalCache接口如下所示:
public interface InternalCache {
//获取缓存
Response get(Request request) throws IOException;
//存入缓存
CacheRequest put(Response response) throws IOException;
//移除缓存
void remove(Request request) throws IOException;
//更新缓存
void update(Response cached, Response network);
//跟踪一个满足缓存条件的GET请求
void trackConditionalCacheHit();
//跟踪满足缓存策略CacheStrategy的响应
void trackResponse(CacheStrategy cacheStrategy);
}我们接着来看看它的实现类。Cache 没有直接实现 InternalCache 这个接口,而是在其内部实现了 InternalCache 的匿名内部类,内部类的方法调用 Cache 对应的方法,如下所示:
final InternalCache internalCache = new InternalCache() {
@Override public Response get(Request request) throws IOException {
return Cache.this.get(request);
}
@Override public CacheRequest put(Response response) throws IOException {
return Cache.this.put(response);
}
@Override public void remove(Request request) throws IOException {
Cache.this.remove(request);
}
@Override public void update(Response cached, Response network) {
Cache.this.update(cached, network);
}
@Override public void trackConditionalCacheHit() {
Cache.this.trackConditionalCacheHit();
}
@Override public void trackResponse(CacheStrategy cacheStrategy) {
Cache.this.trackResponse(cacheStrategy);
}
};
InternalCache internalCache() {
return cache != null ? cache.internalCache : internalCache;
}在Cache类里还定义一些内部类,这些类封装了请求与响应信息。
- Cache.Entry:封装了请求与响应等信息,包括url、varyHeaders、protocol、code、message、responseHeaders、handshake、sentRequestMillis与receivedResponseMillis。
- Cache.CacheResponseBody:继承于ResponseBody,封装了缓存快照snapshot,响应体bodySource,内容类型contentType,内容长度contentLength。
除了两个类以外,Okhttp 还封装了一个文件系统类 FileSystem 类,这个类利用 Okio 这个库对 Java 的 File 操作进行了一层封装,简化了 IO 操作。理解了这些剩下的就是 DiskLruCahe 里的插入缓存 、获取缓存和删除缓存的操作。