统计学笔记【1】方差分析 ANOVA
1 基本概念
1.1 定义及应用
从形式上看,方差分析比较多个总体的均值是否相等,本质上是研究分类型自变量对数值型因变量的影响(eg:行业是否对被投诉次数有影响),与回归分析的方法有许多相同之处,但又有本质区别。在研究一个(或多个)分类型自变量与一个数值型因变量之间的关系时,方差分析就是其中的主要方法之一。方差分析就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。
1.2 因子、水平
在方差分析中,所要检验的对象称为因素或因子(factor)。
因素的不同表现称为水平或处理(treatment)。
每个因子水平下得到的样本数据称为观察值。
下面是一个单因素4水平的试验:

1.3 误差分解
1.3.1 组内误差 SSE
- 来自水平内部的数据误差称为组内误差。
例如在上表中,零售业中抽取的7家企业之间的投诉次数是不同的,由于企业是随机抽取的,因此他们之间的差异可以看成是随机因素的影响造成的。
- 组内误差只含有随机误差。
1.3.2 组间误差 SSA
- 来自不同水平之间的数据误差称为组间误差。
- 这种差异可能是由抽样本身形成的随机误差,也可能是由行业本身的系统性误差造成的系统误差。组间误差是随机误差和系统误差的总和。
1.3.3 SST、SSE、SSA
-
1、反应全部数据误差大小的平方和称为总平方和,记为SST。
试验中,23家企业被投诉次数之间的误差平方就是总平方和,反应全部观测值的离散状况。
自由度为n-1,n为全部观测值的个数 -
2、反应组内误差大小的平方和称为组内平方和,也称为误差平方和或者残差平方和,记为SSE。
试验中,每个样本内部的数据平方和加在一起就是组内平方和,反应每个样本内各观察值的离散情况。
自由度为n-k,k为因素水平(总体)的个数 -
3、反应组间误差大小的平方和称为组间平方和,也称为因素平方和,记为SSA。
组间误差可能是由抽样本身形成的随机误差,也可能是由行业本身的系统性因素造成的系统误差,因此,组间误差是随机误差和系统误差的总和。
试验中,四个行业被投诉次数之间的误差平方和就是组间平方和,反应了样本均值之间的差异程度。
自由度为k-1
SST = SSE + SSA
总结:
- SSA是对随机误差和系统误差大小的度量,它反映了自变量(行业)对因变量(被投诉数)的影响,也称为自变量效应****或因子效应。
- SSE是对随机误差大小的度量,它反映了除自变量对因变量的影响之外,其他因素对因变量的总影响,因此SSE也称为残差变量,它所引起的误差也称为残差效应。
- SST是对全部数据总误差程度的度量,它反映了自变量和残差变量的共同影响,因此它等于自变量效应加残差效应。
1.3.4 MSA、MSE
MSA= 组间平方和/自由度 = SSA/(k-1)
MSE=组内平方和/自由度 = SSE/(n-k)
由于各误差平方和的大小与观测值的多少有关,为了消除观测值多少对误差平方和大小的影响,需要将其平均,也就是用个平方和除以它们所对应的自由度,这一结果称为均方。
** 如果不同行业对被投诉次数没有影响,那么在组间误差中,值包含随机误差,而没有系统误差。这时,组间误差与组内误差经过平均后的数值(称为均方或方差)就应该很接近,他们的比值就会接近1。
** 反之,如果不同行业对被投诉次数有影响,在组间误差中除了包含随机误差,还会包含系统误差,这时组间误差平均后的数值就会大于组内误差平均后的数值,他们之间的比值就会大于1。
判断行业对被投诉次数是否有显著影响,实际上也就是检验被投诉次数的差异主要是由什么原因引起的,如果这种差异主要是系统误差,就认为不同行业对被投诉次数有显著影响,也就是检验四个行业被投诉次数的均值是否相等。
1.4 方差分析中的基本假定
1.4.1 每个总体都服从正态分布
对因素的每一水平,其观测值都是来自正态分布总体的简单随机样本。
1.4.2 各个总体的方差必须相同
每个行业被投诉次数的方差相同。
1.4.3 观测值是独立的
1.5 假设的一般提法
H0:u1=u2=u3=u4 (自变量对因变量没有显著影响)
H1:u1、u2、u3、u4 不全相等 (自变量对因变量有显著影响)
2 单因素方差分析
2.1分析过程
1、提出假设
2、构造检验的统计量:
(1)各样本的均值
各个行业的样本均值(X1,X2,X3,X4)
(2)全部观察值的总均值
总均值(x)
(3)计算各误差平方和:SST,SSE,SSA
SST:各个观测值和总均值(x)的误差平方和
SSE:各个行业的均值(X1,X2,X3,X4)和总均值(x)的误差平方和
SSA:各个行业内的样本数据和其组均值的误差平方和
(4)计算统计量 MSA、MSE
MSA= 组间平方和/自由度 = SSA/(k-1)
MSE=组内平方和/自由度 = SSE/(n-k)
(5)计算F统计量
F统计量
当H0为真时,msa、mse的比值服从分子自由度为k-1,分母自由度为n-k的F分布:
F=MSA/MSE ~ F(k-1,n-k)
3、统计决策
- 如果H0:u1=u2=u3=u4成立,则表明没有系统误差,组间方差MSA与组内方差MSE的比值就不会太大;如果组间方差显著大于组内方差,说明各水平(总体)之间的差异显然不仅仅有随机误差,还有系统误差。
- 显著水平a,F分布表中查找临界值Fa
- 若F>Fa,则拒绝原假设,表明行业对被投诉次数有显著影响
- 若F
2.2 关系强度的测量 R平方
-
- 只要组间平方和(组间SS)不等于零,就表明两个变量之间有关系(只是是否显著的问题)。
-
- 当组间平方和比组内平方和大,且大道一定程度时,就以为这两个变量之间的关系显著。大得越多,表明他们之间的关系就越强。
-
- 反之,当组间平方和比组内平方和小时,就意味着两个变量之间的关系不显著,小得越多,表明他们之间的关系就越弱。
![]()
eg:R平方=35%,则表明,行业对被投诉次数的影响效应占总效应的35%,而残差效应占65%。尽管R平方并不是很高,但是行业对被投诉次数的影响已经达到统计上显著的程度。
2.3 多重比较
不同行业被投诉次数的均值不完全相同,但是究竟是哪些均值之间不相等?就需要用到多重比较方法,通过对总体之间的配对比较来进一步验证到底哪些均值之间存在差异。
多重比较方法有许多种,下面的是由费希尔提出的最小显著差异方法(LSD),步骤如下:
1、提出假设:
- H0:ui=uj
- H1:ui != uj
2、计算统计量xi - xj (两个总体的均值之差)
3、计算LSD = t (a/2)*标准误
t的自由度为n-k

4、如果| xi - xj | > LSD ,拒绝H0
ps:一个因子,如果有m个水平,则要做cm2个检验
![]()
2.4 用excel进行分析
【数据】-【数据分析】-【方差分析:单因素方差分析】
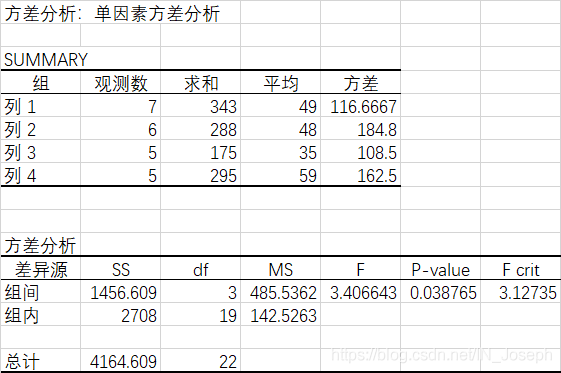
SS:平方和
MS:均方
df :自由度
F:检验的统计量
P-value:检验的P值
F crit : 给定a水平下的临界值
决策:
(1)P
3 双因素方差分析
方差分析中涉及两个分类自变量,称为双因素方差分析
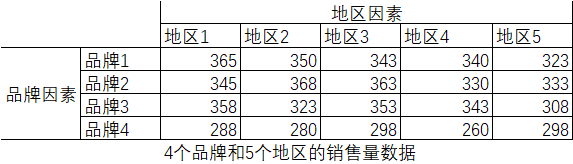
- 如果双因素分析中,如上例,品牌和地区对销售量的影响是相互独立的,分别判断品牌和地区对销售量的影响,这时的双因素分析称为无交互作用的双因素方差分析,或者称为无重复双因素分析。
- 如果两个因素除了对销售量的单独影响,两个因素的搭配还会对销售额产生一种新的影响,例如,某地区对某品牌的彩电有特殊偏好,这就是两个因素结合后产生的新的小银,这时的双因素分析称为有交互作用的双因素分析,或者称为可重复双因素分析。
3.1 无交互作用的双因素分析
3.1.1分析步骤
行因素有k个水平,列因素有r个水平
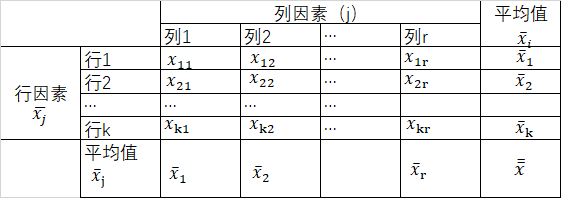
1、 提出假设
(1)对行因素提出假设:
H0:u1=u2=u3=u4=u5 (行因素对因变量没有显著影响)
H1,:u1、u2、u3、u4、u5 不全相等 (行因素对因变量有显著影响)
(2)对列因素提出假设:
H0:u1=u2=u3=u4 (列因素对因变量没有显著影响)
H1,:u1、u2、u3、u4不全相等 (列因素对因变量有显著影响)
2、构建检验的统计量:SST、SSR、SSC、SSE、F统计量
SST=SSR+SSC+SSE
-
SST:自由度:kr-1,所有观测值与总体均值的误差平方和。
SSR:自由度:k-1,行因素产生的误差平方和。(等于每一行的平均数(k个),与总体均值之间的方差)
SSC:自由度:r-1,列因数产生的误差平方和。(等于每一列的平均数(r个),与总体均值之间的方差)
SSE:自由度:(k-1)*(r-1) ,随机误差平方和。 -
均方
MSR = SSR/(k-1)
MSC = SSC/(r-1)
MSE = SSE/(k-1)(r-1)
F统计量
(1)检验行因素对因变量的影响是否显著:
Fr = MSR/MSE ~F(k-1,(k-1)(r-1))
(2)检验列因素对因变量的影响是否显著:
Fc = MSC/MSE ~F(r-1,(k-1)(r-1))
3、统计决策
根据显著水平a和两个自由度,查F分布表得到相应的两个临界值Fa,分别与Fr和Fc进行比较
Fr > Fa,拒绝H0,说明品牌对销售量有显著影响。
Fc < Fa,不拒绝H0,不能认为地区对销售量有显著影响。
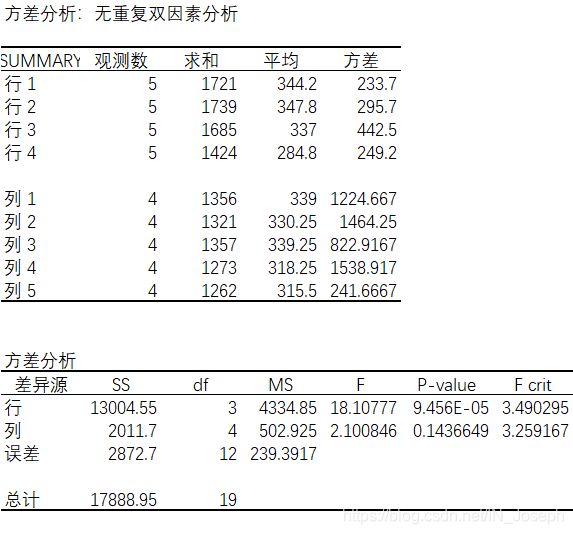
3.1.2 关系强度的测量R平方
R平方 = 联合效应/总效应 = (SSR+SSC)/SST
上述案例中,R平方= 83.94%,这表明,品牌因素和地区因素合起来总共解释了销量差异的83.94%,其他因素(残差变量)只解释了销售量差异的16.06%,而R=0.9162,这表明品牌和地区两个因素合起来与销售量之间有较强的关系。
3.1.3对比分别做单因素方差分析
分别考察品牌和地区与销售量之间的关系
(1)地区单因素方差分析

F

对比

双因素方差分析中的误差平方和等于2872.7,比分别进行单因素方差分析的任何一个平方和(488.4和15877.25)都小,且P值也变得更小了。
因为在双因素方差分析中,误差平方和不包括两个自变量中的任何一个,因而减少了残差效应。而分别做单因素方差分析时,将行因素(品牌)作自变量时,列因素(地区)被包括在残差中,同样,将列因素作自变量时,行因素被包括在残差中。
因此,对于两个自变量而言,进行双因素方差分析要优于分别对两个因素进行单因素方差分析。
3.2 有交互作用的双因素方差分析
研究:不同路段和不同时间段对形成时间的影响。
试验:分别在两个路段的高峰期和非高峰期驾车进行试验,通过试验获得20个行车时间的数据。
分析:路段、时段以及路段和时段的交互作用对行车时间的影响。

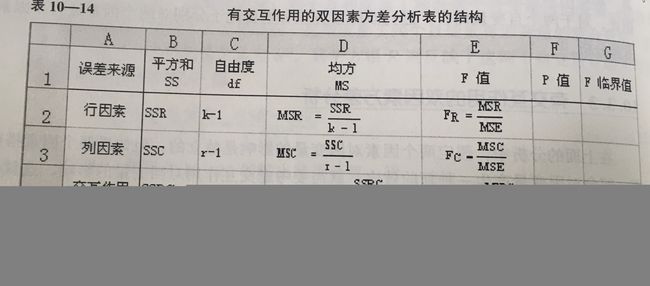

由结果可知,
- 用于检验“时段”(行因素、样本)的P值
- 用于检验“路段”(列因素)的P值
- 交互作用反应的是时段因素和路段因素联合产生的对行车时间的附加效应,用于检验的P值>a=0.05,因此不拒绝原假设,没有证据表明时段和路段的交互作用对行车时间有显著影响。

k:行变量有k个水平,此处k=2
r:列变量有r个水平,此处r=2
n:观察数据的总数,此处n=20
m:行变量中每个水平的行数(每个样本的行数),此处m=5 - 用于检验“路段”(列因素)的P值
ps:
区别:
