模型正则化与梯度消失或爆炸问题小记
过拟合与欠拟合
基本概念
首先我们需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平方损失函数和softmax回归用到的交叉熵损失函数。
机器学习模型应关注降低泛化误差。
而过拟合与欠拟合是指型训练中经常出现的两类典型问题:
- 一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting)
- 另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。
两者关系可以从下图中看出:
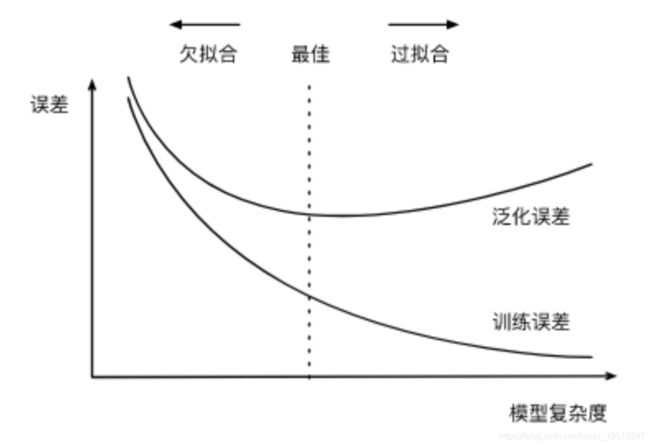
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
权重衰减
基本概念
权重衰减等价于L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。

具体实现
从零实现
按照公式,我们可以通过以下方式定义L2正则化的计算:
def l2_penalty(w):
return (w**2).sum() / 2
使用时,我们只需要在训练的过程中加上这一步骤:
net, loss = d2l.linreg, d2l.squared_loss
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
def fit_and_plot(lambd):
w, b = init_params()
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
# 添加了L2范数惩罚项
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
l = l.sum()
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
d2l.sgd([w, b], lr, batch_size)
train_ls.append(loss(net(train_features, w, b), train_labels).mean().item())
test_ls.append(loss(net(test_features, w, b), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', w.norm().item())
简洁实现
在pytorch的优化器当中已经集成了权重衰减相关的操作,使用如下:
def fit_and_plot_pytorch(wd):
# 对权重参数衰减。权重名称一般是以weight结尾
net = nn.Linear(num_inputs, 1)
nn.init.normal_(net.weight, mean=0, std=1)
nn.init.normal_(net.bias, mean=0, std=1)
optimizer_w = torch.optim.SGD(params=[net.weight], lr=lr, weight_decay=wd) # 对权重参数衰减
optimizer_b = torch.optim.SGD(params=[net.bias], lr=lr) # 不对偏差参数衰减
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y).mean()
optimizer_w.zero_grad()
optimizer_b.zero_grad()
l.backward()
# 对两个optimizer实例分别调用step函数,从而分别更新权重和偏差
optimizer_w.step()
optimizer_b.step()
train_ls.append(loss(net(train_features), train_labels).mean().item())
test_ls.append(loss(net(test_features), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', net.weight.data.norm().item())
丢弃法(dropout)
基本概念
dropout一般是对多层感知机即神经网络的隐藏层使用,当对某一层的隐藏层使用dropout时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为p,那么有p的概率hi会被清零,有1-p的概率会除以做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量为0和1的概率分别为p和1-p。使用丢弃法时我们计算新的隐藏单元hi’:
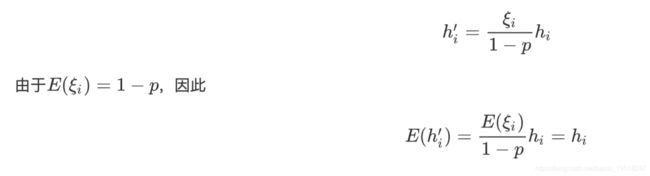
即丢弃法不改变其输入的期望值。让我们对之前多层感知机的神经网络中的隐藏层使用丢弃法,一种可能的结果是其中和被清零。这时输出值的计算不再依赖和,在反向传播时,与被清零的隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即任何一个隐藏单元都有可能被清零,输出层的计算无法过度依赖其中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法。
具体实现
从零实现
可以使用如下的方法进行实现:
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return torch.zeros_like(X)
mask = (torch.rand(X.shape) < keep_prob).float()
return mask * X / keep_prob
相当于随机出一个与X大小相同的矩阵,当某一位置的值小于keep_prob的时候,表示这一个值被清零。最终返回的时候需要进行拉伸。
在使用时,在计算得到隐藏层的值H后使用dropout:
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X, is_training=True):
X = X.view(-1, num_inputs)
H1 = (torch.matmul(X, W1) + b1).relu()
if is_training: # 只在训练模型时使用丢弃法
H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层
H2 = (torch.matmul(H1, W2) + b2).relu()
if is_training:
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return torch.matmul(H2, W3) + b3
简洁实现
pytorch中内置了dropout模块,可以直接使用:
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
梯度消失与梯度爆炸
基本概念
深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。
当神经网络的层数较多时,模型的数值稳定性容易变差。

随机初始化模型参数
在神经网络中,通常需要随机初始化模型参数。
如果将每个隐藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输入计算出相同的值,并传递至输出层。在反向传播中,每个隐藏单元的参数梯度值相等。因此,这些参数在使用基于梯度的优化算法迭代后值依然相等。之后的迭代也是如此。在这种情况下,无论隐藏单元有多少,隐藏层本质上只有1个隐藏单元在发挥作用。因此,正如在前面的实验中所做的那样,我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
pytorch中的随机初始化
随机初始化模型参数的方法有很多。在线性回归的简洁实现中,我们使用torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式。不过,PyTorch中nn.Module的模块参数都采取了较为合理的初始化策略(不同类型的layer具体采样的哪一种初始化方法的可参考源代码),因此一般不用我们考虑。
Xavier随机初始化
还有一种比较常用的随机初始化方法叫作Xavier随机初始化。 假设某全连接层的输入个数为a,输出个数为b,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布:
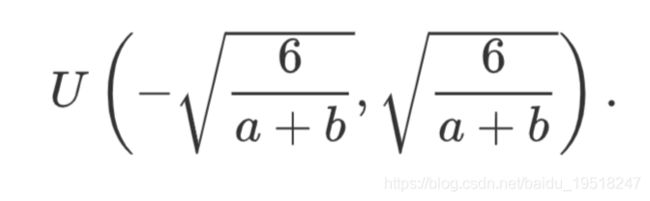
它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
其他环境因素
协变量偏移
这里我们假设,虽然输入的分布可能随时间而改变,但是标记函数,即条件分布P(y∣x)不会改变。虽然这个问题容易理解,但在实践中也容易忽视。
想想区分猫和狗的一个例子。我们的训练数据使用的是猫和狗的真实的照片,但是在测试时,我们被要求对猫和狗的卡通图片进行分类。
统计学家称这种协变量变化是因为问题的根源在于特征分布的变化(即协变量的变化)。数学上,我们可以说P(x)改变了,但P(y∣x)保持不变。尽管它的有用性并不局限于此,当我们认为x导致y时,协变量移位通常是正确的假设。
标签偏移
当我们认为导致偏移的是标签P(y)上的边缘分布的变化,但类条件分布是不变的P(x∣y)时,就会出现相反的问题。当我们认为y导致x时,标签偏移是一个合理的假设。例如,通常我们希望根据其表现来预测诊断结果。在这种情况下,我们认为诊断引起的表现,即疾病引起的症状。有时标签偏移和协变量移位假设可以同时成立。例如,当真正的标签函数是确定的和不变的,那么协变量偏移将始终保持,包括如果标签偏移也保持。有趣的是,当我们期望标签偏移和协变量偏移保持时,使用来自标签偏移假设的方法通常是有利的。这是因为这些方法倾向于操作看起来像标签的对象,这(在深度学习中)与处理看起来像输入的对象(在深度学习中)相比相对容易一些。
概念偏移
出现在概念转换中,即标签本身的定义发生变化的情况。
循环神经网络进阶小记见:
https://blog.csdn.net/baidu_19518247/article/details/104319661