“GAN之父”Goodfellow与网友互动:关于GAN的11个问题(附视频)
编者按:昨天,雷锋网根据 Ian Goodfellow 演讲视频的前20分钟整理出《“GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上)》,其中Goodfellow主要讲述了什么是 GAN 和 DCGANs、模型崩溃、小批量特征、文本转图像等问题。本文是后18分钟视频的内容,主要是 Goodfellow 回答网友提问,总共有11个问题。本文由雷锋网三川、亚萌联合编译。
原文视频连接: https://www.leiphone.com/news/201612/JMWZE6BXRZxB1A6d.html
CNN、GANs 和 DBN(Deep Belief Network)之间区别是什么?
简单来说,CNN是神经网络的一种架构,它们未必是为了学习如何生成一组图像而设计。它们可以被用来创造很多的东西,包括 GANs 和 DBN。
这个问题的另外一个方面是:DBN和 GANs 的效果或者学习区别是什么。DBN 基于统计物理学的模型,你写下一个能量函数(energy function),来描述不同图片的相似度。如果一个图像的能量较低,那么更可能发生。这类似于山上的岩石。滚到山脚的石头比山顶的石头有更低的能量,这是由于重力。所以在山脚发现大堆石头的可能性更大。DBN 的难点在于,很多必需的、模拟物理定律的计算变得非常复杂,所以它扩展到大型彩色图像的效果不好。对于类似 EM Nest 的应用,它效果很好。但在 Imagenet 上,DBN 还不能产生有竞争力的结果。
文本转图像的 GANs,是需要同时输入代码和语句吗?
基本上,省略掉代码是有可能的。但在大多数应用中,人们既输入代码也输入语句限制条件,这样才能保证最终输出结果的多样性。这样系统才能学习到整个有条件的概率分布,从一次输入信息中,得到多样化的输出样本。
高效训练 GANs 的难点在哪?如何解决?
主要的困难是模型崩溃,以及寻找模型均衡点(equilibrium)的相关问题。
主要的解决方式是,开发能找到均衡状态的新算法,而不是依靠让误差最小化的成本函数(cost function)。
这其中的均衡状态是不断演化着(Evolutionary)的吗?
其实并不是,而是随机的,神经网络训练利用梯度算法来引导更新。
(编者注:这里 Goodfellow 又回头接着讲PPT上的内容)GANs 还有一个很酷的应用是,对画家进行自动辅助。你也许不擅长绘画,但有了这个 GANs 辅助绘图软件,你只需画这么一个三角,GANs 会自动搜索有相似特点的图像,然后在你画的三角区域,填充山丘的纹理;并在你画的绿色波浪那里,填充青草的纹理。
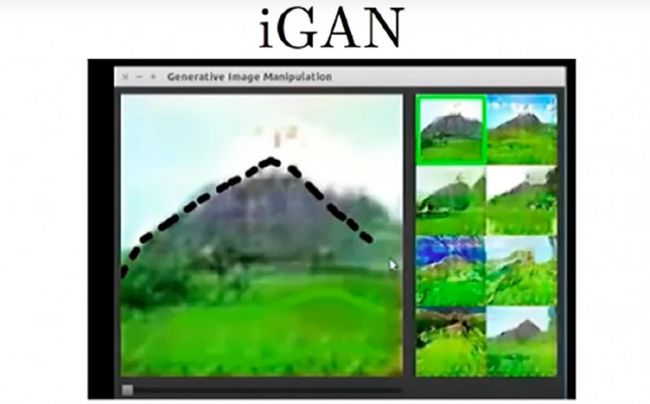
基于 GANs 的绘图辅助功能
我昨天刚听说一个很相似的主意,也使用了“内省对抗网络”( Introspective Adversarial Network)。它是一个辅助图像编辑的功能。当你绘图时,生成模型会把你画出的图形转化为照片般真实的图像。所以,你编辑的图片不会看起来很假,还能不断调整你希望看到的效果。这样,最终编辑出来的图像看起来很真实,一点也不像用鼠标涂鸦过。
你之前提到GANs无法将纹理和肢体有效结合起来的问题,那么你认为解决方案是什么?
这其实很难知道。因为训练算法不够好。目前训练算法的一个问题是,它们被设计用来最小化每一层网络的成本函数,而不是找到均衡点。拿两个人玩“剪刀包袱锤”做比方。假设你出锤,对方出包袱。你输了这局,你觉得既然对方出包袱,下一局你就出剪刀。因为你出剪刀,对方决定再下一局出锤子……这样周而复始,双方都达不到纳什均衡。
这个游戏的均衡点是,每个人以三分之一的比率分别出剪刀、包袱、锤。但如果你的学习算法的学习速率(Learning Rate)不够小,它不会找到均衡点。这个例子十分简单,只要减小学习速率就能找到均衡点。对于GANs,这更复杂。减小学习速率,并不能保证能找到均衡点。我们极有可能需要一些专门的算法,或者改变游戏方式,让使用低学习速率的梯度下降法也能找到均衡点。这是一个相对困难的研究问题。包括我在内,很多人仍在研究。
回到如何放置肢体和纹理及形成3D效果的问题。我们也许需要开发一个更复杂的架构,比方说,生成器的网络深度不够。如果我们有一个极深的生成器,它也许能学习怎么让图像的不同部分更和谐。或者,我们也可以对图形加入特殊操作,类似于 Open GL 的渲染管道。如果你见过空间变换网络处理分类任务,你可以想象用它把有纹理的多边形放置到图像中。
什么GANs应用能商业化,成为明星产品?
我认为对于 Photoshop 这样的应用,自动化绘图会是一个很好的功能。把上文中介绍的自动绘图算法推向市场会很有用处。另外一个领域是语音合成,神经网络对它非常擅长。Deepmind 最近的一篇论文提到一个名为 “Wavenet”的模型,可以创造出极为逼真的人类语音。Wavenet 的问题是,它生成样本的速度很慢。这类生成模型每一步只能完成输出的一个部分。Wavenet 以约 12 千赫的速度生成声音样本。所以你需要连续运行 12000 个神经网络,每一个神经网络的输出被用作下一个神经网络的输入。每一秒合成语音需要两分钟的计算时间,因此神经网络无法进行即时会话。软、硬件效率的提升最终能让它更快。但现在看来,我们离 Wavenet 进行即时会话还有好几年的时间。理论上,生成对抗网络能提供更快的文字到语音的合成。
如何在GANs里生成反馈回路(Feedback Loop)?
生成对抗网络会生成,和输入的参数十分相似的输出。在时间轴上预测下一步(在 Wavenet 的例子上是音频序列),你可以直接把 Wavenet 架构用作生成网络,反向传播算法(backpropagation)会正常运作。
你认为,如何才能把输出扩展为大尺寸?
其实,由于高效率的卷积,扩展输出尺寸通常不是那么难。举例来说,我演讲中展示的最大图片,它的尺寸是 128×128。最近的论文中,Facebook 已经做到输出 256×256 的图片。真正难的是,输出大量内含恰当细节的多样化图像。
GANs能否用于数据压缩?
嗯,很有可能。原则上大多数生成模型都可以。对于 GANs,你需要找到能从图像到描述图像的代码的方法。我描述的 GANs 版本只有单一方向(代码到图像)映射,但是蒙特利尔大学的对抗学习推理(Adversarially Learned Inference),还有加州大学伯克利分校的双向GANs(Bidirectional GANs),有从图像到代码的编码层(Encode Layer)。你可以用编码层生成简单代码,对于经过解码的图像的区别,再使用硬编码的压缩算法将之压缩。如果你运气好,这些区别足够小,可以被压缩,最终结果会比原始图像使用更少的比特。
你对GANs的目标是什么?
我最感兴趣、花费很多时间来研究的是提高训练稳定性,但这特别难。我还花一些时间在开发新架构上。但相比稳定性,它关系不大。
你可以详细解释上面的反馈回路问题吗?
如果你有一个生成网络,能把它自己的输出作为输入,那就能做到。如果你有一个层级,从代码映射到视频第一帧;然后你创建另一个层级,把上一帧视频映射到代码,再到下一帧;你可以把第二层级不断重复利用,它应该能做出不错的视频序列。
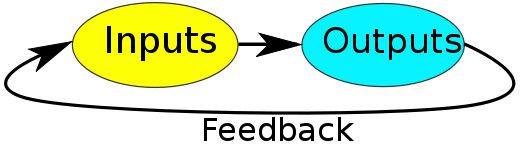
反馈回路:输入→输出→输入(照此循环)
这方面的研究很少,发表的论文也不多。大多数生成对抗网络的研究都是关于图像。Facebook AI 研究部门有一篇关于视频生成的论文,该研究用到了对抗网络损失。还有一篇讲3D合成视频序列的论文。这些论文很具体地解释了研究人员是怎么做的以及最终成效。我认为两个研究都加入了一些额外的东西,包括下一帧预测的方差。为了略微稳定训练。Facebook 的研究还加入了一个基于比较图像的边缘的损失,来保证生成的视频不模糊。
视频预测一个很难的地方是:大多数模型预测认为,你应该把同一帧永远复制下去;或者影像不断模糊下去,直到全部消失。这是由于每一个像素的不确定性太多。所以,让他们不断预测每一帧的清晰画面十分困难。
视频前20分钟讲解内容详见:http://blog.csdn.net/love666666shen/article/details/75106249 ,
转载原文链接:https://www.leiphone.com/news/201612/eAOGpvFl60EgFSwS.html