NIN(Network in Network)学习笔记
NIN(Network in Network)学习笔记
一、前言
《Network In Network》是一篇比较老的文章了(2014年ICLR的一篇paper),是当时比较牛逼的一篇论文,同时在现在看来也是一篇非常经典并且影响深远的论文,后续很多创新都有这篇文章的影子。通常里程碑式的经典是不随时间而黯淡的,同样值得好好学习。
这篇文章采用较少参数就取得了Alexnet的效果,Alexnet参数大小为230M,而Network In Network仅为29M。(缘起)卷积网络通常由卷积和池化交替堆叠,最后接全连接完成模型构建,卷积通过线性滤波器对应特征图位置相乘并求和,然后进行非线性激活得到特征图。线性模型足以抽象线性可分的隐含特征,但是实际上这些特征通常是高度非线性的,常规的卷积网络则可以通过采用一组超完备滤波器(尽可能多)提取统一潜在特征各种变体(宁可错杀一千不可放过一个),但是同一潜在特征使用太多的滤波器会给下一层带来额外的负担,需要考虑来自前一层的所有变化的组合,来自更高层的滤波器会映射到原始输入的更大区域,它通过结合下层的较低级概念生成较高级的特征,因此作者认为网络局部模块做出更好的特征抽象会更好,顺势引入Network in Network则能达到这个目标,在每个卷积层内引入一个微型网络,来计算和抽象每个局部块的特征。
二、创新点
论文Network in Network的网络结构中有由两处新的结构(当时),MLP Convolution Layers和Global Average Pooling。
1、MLP Convolution Layers(创新点1)
一言以蔽之,所谓MLPConv其实就是在常规卷积(感受野大于1的)后接若干1x1卷积,每个特征图视为一个神经元,特征图通过1x1卷积就类似多个神经元线性组合,这样就像是MLP(多层感知机)了,这是文章最大的创新点,也就是Network in Network(网络中内嵌微型网络)。
论文提到一开始并不知道潜在特征的分布,因此用一个通用的函数逼近器提取局部块特征,这样可以尽可能逼近潜在特征的抽象表示。
径向基(Radial basis network)和 从多层感知机(multilayer perceptron)是两种通用的函数逼近器,作者选择了多层感知机,因为多层感知器与卷积神经网络的结构一样,都是通过反向传播训练。其次多层感知器本身就是一个深度模型,符合特征再利用的原则。
普通卷积层(感受野大于1)及文中提到的GLM(generalized linear model)相当于单层网络,抽象能力有限,其计算公式和示意图如下:
![]()

为了提高特征的抽象表达能力,作者用MLPConv代替了GLM,计算公式为:

n为网络层数,第一层为线性卷积层(卷积核尺寸大于1),后面的为1x1卷积。
示意图:
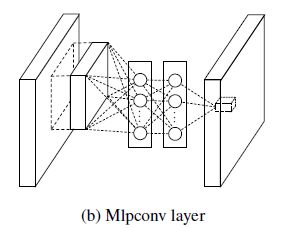
基于AlexNet修改的NIN中MLPConv为三层,conv1常规卷积,occp1和occp2为1x1卷积。

在当时作者应该是第一个使用1x1卷积的,具有划时代的意义,之后的Googlenet借鉴了1*1卷积,还专门致谢过这篇论文,现在很多优秀的网络结构都离不开1x1卷积,ResNet、ResNext、SqueezeNet、MobileNetv1-3、ShuffleNetv1-2等等。
1x1卷积作为NIN函数逼近器基本单元,除了增强了网络局部模块的抽象表达能力外,在现在看来还可以实现跨通道特征融合和通道升维降维。
2、Global Average Pooling(创新点2)
传统卷积神经网络在网络的浅层进行卷积运算。对于分类任务,最后一个卷积层得到的特征图被向量化(flatten)然后送入全连接层,接一个softmax逻辑回归层。这种结构将卷积结构与传统神经网络分类器连接起来,卷积层作为特征提取器,得到的特征用传统神经网络进行分类。全连接层参数量是非常庞大的,模型通常会容易过拟合,针对这个问题,Hinton提出Dropout方法来提高泛化能力,但是全连接的计算量依旧很大(想想4096+4096……)。
基于此,论文提出用全局平均池化代替全连接层,具体做法是对最后一层的特征图进行平均池化,得到的结果向量直接输入softmax层。这样做好处之一是使得特征图与分类任务直接关联,另一个优点是全局平均池化不需要优化额外的模型参数,因此模型大小和计算量较全连接大大减少,并且可以避免过拟合。
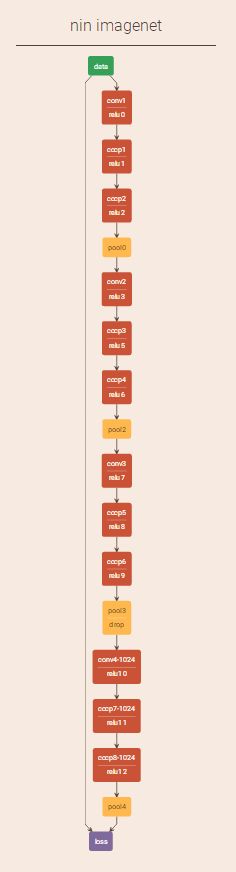
三、整体网络结构
知道NIN的基本单元,整体网络结构为Input+MLPConv+GAP+softmax,网络结构示意图如下:

Caffe实现的结构在链接:
https://gist.github.com/mavenlin/d802a5849de39225bcc6
Netscope:
四、总结
Network in Network对常规卷积网络的特征提取抽象表示进行改进,提出MLPconv,其实就是在常规卷积后接1x1卷积(首次使用1x1卷积),首次采用全局平均池化降低网络复杂度,避免过拟合,在之后的很多经典论文中都有用到,具有开创性意义;深度学习发展迅猛,论文很多,但是经典的还是少数,所以很值得学习,以前的ResNet,MobileNetv1-3,ShuffleNetv1-2等等,以及在最新的基于关键点的目标检测论文CornerNet-Lite也有用到该论文的思想,足见影响深远。
参考资料:
[1] Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013.
[2] https://gist.github.com/mavenlin/d802a5849de39225bcc6