scikit-learn中使用SimpleImputer来对数据集缺失值进行插值
简单处理数据集的缺失值
- 示例数据集
- 代码
-
- 示例代码
- 完整代码
- 比较不同的插补统计量
- 在进行预测时的SimpleImputer转换
原文来源自
示例数据集
Horse Colic Dataset(病马数据集:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv
Horse Colic Dataset Description:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.names
该数据集共有300条记录(300行),有26个输入变量和1个输出变量。这是一个二分类预测问题,标签有两个值,马匹活着是1,马匹死亡则是2。
这个数据集在多个列上包含大量的缺失值,每一个缺失值都标有问号“?”。
代码
示例代码
from pandas import read_csv
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'
dataframe = read_csv(url, header=None, na_values='?') #'?'变成NaN
scikit-learn机器学习工具库提供SimpleImputer类来支持数据缺失值插补。
SimpleImputer 是一个数据转换工具,基于每一列所计算出的统计量类型进行初始配置,例如平均值。
# define imputer
imputer = SimpleImputer(strategy='mean')
# fit on the dataset
imputer.fit(X)
# transform the dataset
Xtrans = imputer.transform(X) #每一列的缺失值都已经被统计量值所替换。
完整代码
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'
dataframe = read_csv(url, header=None, na_values='?')
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# define modeling pipeline
model = RandomForestClassifier() #随机森林分类器
imputer = SimpleImputer(strategy='mean') #用均值填充NaN值
pipeline = Pipeline(steps=[('i', imputer), ('m', model)]) #建立流水线,先imputer,再model
# define model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) #三次重复的十折交叉验证
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
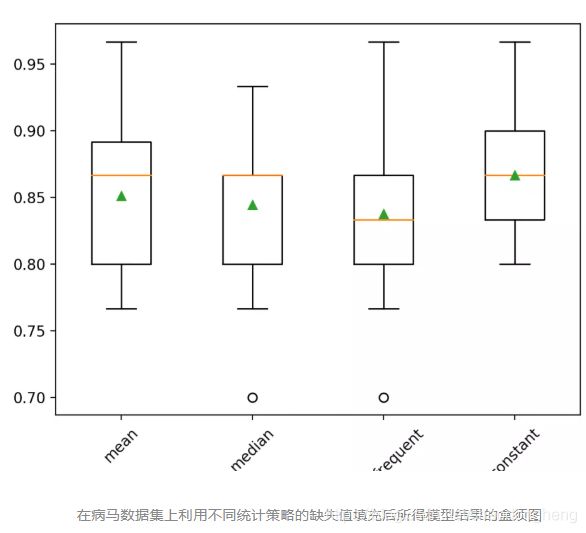
比较不同的插补统计量
比较均值、中位数、众数(更常用)和常数(0)四种策略。
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'
dataframe = read_csv(url, header=None, na_values='?')
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# evaluate each strategy on the dataset
results = list()
strategies = ['mean', 'median', 'most_frequent', 'constant'] #四种方式
for s in strategies:
# create the modeling pipeline
pipeline = Pipeline(steps=[('i', SimpleImputer(strategy=s)), ('m', RandomForestClassifier())])
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# store results
results.append(scores)
print('>%s %.3f (%.3f)' % (s, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=strategies, showmeans=True) #画盒须图
pyplot.xticks(rotation=45)
pyplot.show()
在进行预测时的SimpleImputer转换
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv'
dataframe = read_csv(url, header=None, na_values='?')
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# create the modeling pipeline
pipeline = Pipeline(steps=[('i', SimpleImputer(strategy='constant')), ('m', RandomForestClassifier())])
# fit the model
pipeline.fit(X, y)
# define new data 预测数据也存在空值
row = [2,1,530101,38.50,66,28,3,3,nan,2,5,4,4,nan,nan,nan,3,5,45.00,8.40,nan,nan,2,2,11300,00000,00000]
# make a prediction
yhat = pipeline.predict([row]) #预测
# summarize prediction
print('Predicted Class: %d' % yhat[0])