Hadoop完全分布式安装
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
实验环境:关闭selinux,iptables
添加解析(3台):
172.25.0.117 server2
172.25.0.118 server3
172.25.0.119 server4
关闭server2服务:
[hadoop@server2 hadoop-2.7.3]$ sbin/stop-yarn.sh
[hadoop@server2 hadoop-2.7.3]$ sbin/stop-dfs.sh
1.安装nfs-utils服务(3台):
[root@server2 hadoop]# yum install nfs-utils -y
[root@server2 hadoop]# id hadoop
uid=500(hadoop) gid=500(hadoop) groups=500(hadoop)
[root@server2 hadoop]# vim /etc/exports
/home/hadoop *(rw,anonuid=500,anongid=500)
[root@server2 hadoop]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server2 hadoop]# /etc/init.d/nfs start
Starting NFS services: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
挂载:
[root@server2 hadoop]# showmount -e 172.25.0.117
Export list for 172.25.0.117:
/home/hadoop *
server3和server4端安装nfs并挂载
[root@server3 ~]# yum install nfs-utils -y
[root@server3 ~]# useradd -u 500 hadoop
[root@server3 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server3 ~]# /etc/init.d/nfs start
Starting NFS services: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
[root@server3 ~]# mount 172.25.0.117:/home/hadoop /home/hadoop
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ls
hadoop-2.7.3 hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
2.设置SSH无密码登录
[hadoop@server2 ~]$ ssh-copy-id server3
[hadoop@server2 ~]$ ssh-copy-id server4
[hadoop@server2 ~]$ ssh 172.25.0.118
Last login: Sun Mar 24 23:00:54 2019 from server2
[hadoop@server3 ~]$ exit
logout
Connection to 172.25.0.118 closed.
[hadoop@server2 ~]$ ssh 172.25.0.119
Last login: Sun Mar 24 22:55:16 2019 from server2
[hadoop@server4 ~]$ exit
logout
Connection to 172.25.0.119 closed.
3.编辑hdfs-site.xml
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/hdfs-site.xml
dfs.replication
2
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/slaves
172.25.0.118
172.25.0.119
dfs.replication配置的是HDFS存储时的备份数量,slaves文件是指定HDFS上有哪些DataNode节点。
配置yarn-site.xml
[hadoop@server2 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
172.25.0.119
4.在NameNode机器上执行格式化
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs namenode -format

5.启动HDFS
[hadoop@server2 hadoop-2.7.3]$ sbin/start-dfs.sh
Starting namenodes on [server2]
server2: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server2.out
172.25.0.118: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server3.out
172.25.0.119: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server4.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-server2.out
[hadoop@server2 hadoop-2.7.3]$ jps
7381 SecondaryNameNode
7193 NameNode
7490 Jps
server3和server4上查看,server4启动ResourceManager:
[hadoop@server3 ~]$ jps
1579 DataNode
1652 Jps
[hadoop@server4 hadoop-2.7.3]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-server4.out
[hadoop@server4 hadoop-2.7.3]$ jps
3695 NodeManager
4070 Jps
3583 DataNode
3858 ResourceManager
测试Job
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -mkdir /input
[hadoop@server2 hadoop-2.7.3]$ vim file
[hadoop@server2 hadoop-2.7.3]$ cat file
aa bb cc
cat dog harry
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -put file /input
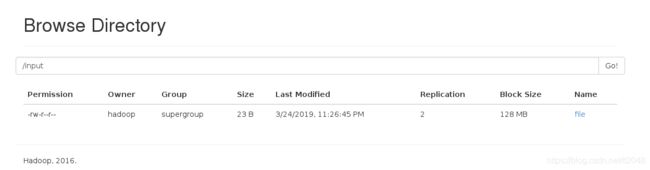
运行hadoop自带的mapreduce Demo
[hadoop@server2 hadoop-2.7.3]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/file /output
查看输出文件
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2019-03-25 17:37 /output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 35 2019-03-25 17:37 /output/part-r-00000
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -cat /output/part-r-00000
aa 1
bb 1
cat 1
cc 1
dog 1
harry 1
节点添加与删除
1.节点增加
首先在每个节点/etc/hosts文件添加解析,继续编辑文件etc/hadoop/slaves添加节点
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/slaves
172.25.0.118
172.25.0.119
172.25.0.121
开启数据节点
[hadoop@server5 hadoop-2.7.3]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server5.out
查看新增节点
[hadoop@server5 hadoop-2.7.3]$ bin/hdfs dfsadmin -report
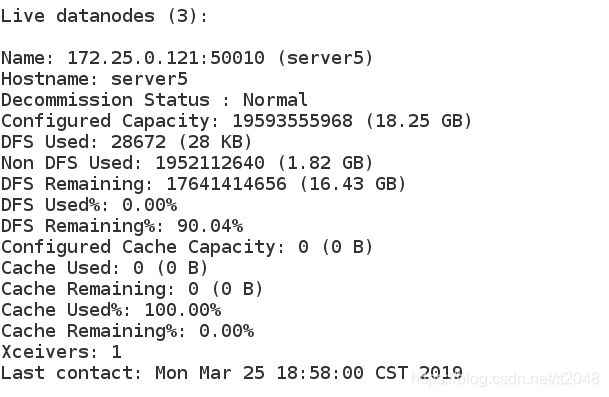
2.节点删除
在namenode中打开hdfs-site.xml,设置节点排除文件的位置
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/excludes
172.25.0.121
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/hdfs-site.xml
dfs.hosts.exclude
/home/hadoop/hadoop-2.7.3/etc/hadoop/excludes
dfs.hosts.exclude定义的文件内容为,每个需要下线的机器,一行一个。
编辑slave文件将sevrer5删除
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/slaves
172.25.0.118
172.25.0.119
重新加载配置
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfsadmin -refreshNodes
Refresh nodes successful
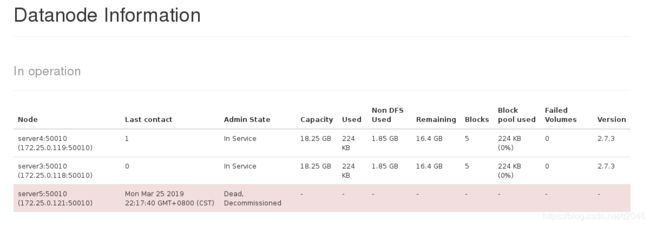
查看集群状态:
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfsadmin -report

可以查看到现在集群上连接的节点
正在执行Decommission,会显示:
DecommissionStatus : Decommission in progress
执行完毕后,会显示:
Decommission Status : Decommissioned
关闭datanode
[hadoop@server5 hadoop-2.7.3]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode