知识蒸馏与推荐系统
「写在前面:」 这是一篇介绍 「【知识蒸馏】」 在 「【推荐系统】」领域应用的文章,算是知识蒸馏简述系列文章的延续,希望能对推荐领域的同学有所帮助。
以下是本文的主要框架:
-
A brief review
-
KD & 推荐
-
Conclusion
「1. A brief review」
「1-1 知识蒸馏回顾」
当我们训练一个深度学习模型时,常常面临模型效果与工程性能冲突的问题。
在监督学习中:
-
训练模型时,通常采用 「复杂模型」 或者 「Ensemble」 方式来获取最好的结果,参数冗余严重。
-
前向预测时,需要对模型进行复杂的计算(或多个加权),导致工程性能较差
特别是在推荐系统中,系统需要从千百万级别的候选中挑选出用户最感兴趣的item。此时面临的模型效果和性能的冲突更为严重。
Hinton在NIPS 2014workshop中提出知识蒸馏(Knowledge Distillation,下面简称KD)概念:
-
KD定义:将 「复杂模型或者多个模型Ensemble(Teacher网络)」 学到的 「[知识 ]」 → 迁移到另一个 「轻量级模型( Student 网络)」 ;辅助Student网络的学习
-
目的:模型压缩、加速;也会应用于模型表现的提升
-
要求:在模型变轻量的同时(方便部署),尽量不损失性能
按照待迁移的知识类型,KD主要分为三个大类:
-
「输出迁移(Output Transfer)——将网络输出(Logits或者Softmax概率等)作为知识」
-
「特征迁移(Feature Transfer)——将网络学习的特征作为知识」
-
关系迁移(Relation Transfer)——将网络特征的关系或者样本的关系作为知识
其中,当下应用到推荐系统中的主要是前两个类别——输出迁移和特征迁移。为了方便关于”KD与推荐“部分的介绍,接下来将对这两大类方法进行简单的介绍。
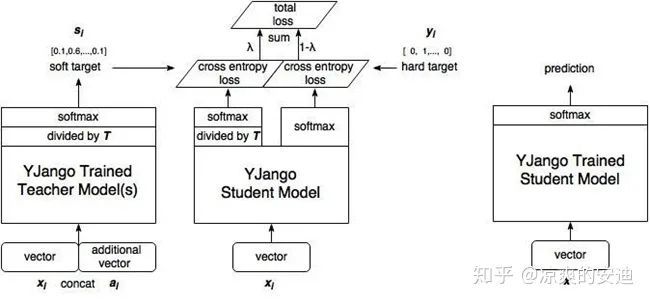
「1-2 输出迁移」
输出迁移的思路为:「学生网络拟合教师网络输出层的输出(教师输出的结果」 )
输出迁移的网络训练分为两个阶段,以分类任务为例:
-
第一阶段:在原始数据集上,使用hard target(真实0, 1标签),训练好一个teacher网络。第一阶段的训练与普通的监督学习训练过程完全相同。teacher网络的loss为普通的交叉熵loss:L=Cross Entropy(x, y)
-
第二阶段:将teacher网络的输出结果soft target(logits输出或softmax的输出等,记作q)作为student网络输出的目标,训练student网络,使得student网络的结果p接近q。「student网络的loss分为两个部分:第一部分为student网络预估的结果在真实标签上的交叉熵loss,第二部分的KD loss为student网络的输出与teacher网络输出的差异。」 student网络的loss:L=α Cross Entropy(x, y) + (1-α) Cross Entropy(p, q)
-
通过KD loss使得学生网络的输出“像”教师网络,使得教师网络输出的“知识”传递学生网络。最终使用student网络来进行预测。
Distilling the Knowledge in a Neural Network
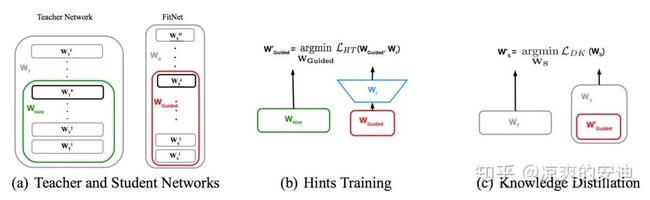
「1-3 特征迁移」
特征迁移的思路为:「学生网络拟合教师网络隐藏层的输出(教师抽取的特征)」
FitNets: Hints for Thin Deep Nets
该模型分为 「三阶段训练」 :
-
第一阶段:用ground-truth目标将教师网络训练好
-
第二阶段:让
最高层的输出拟合
-
最高层的输出用第一个Loss(特征迁移),完成学生网络的参数初始化
-
第三阶段:用Soft-target方式对学生网络进行蒸馏(输出迁移)
其中:
是教师网络的所有参数,
-
是学生网络的所有参数
- 是教师网络的部分层的参数(绿框) ;
-
是学生网络的部分层的参数 (红框)
-
是一个全连接层,用于将两个网络输出的size配齐(因为学生网络隐藏层宽度比教师网络窄)
这两篇paper是输出迁移和特征迁移中最最经典的两篇,后续的这两类KD的相关paper基本都与这两个算法相关。「特别地是,当下(截止2020年8月)KD与推荐系统结合的应用基本都是对这两个算法的借鉴与优化。」
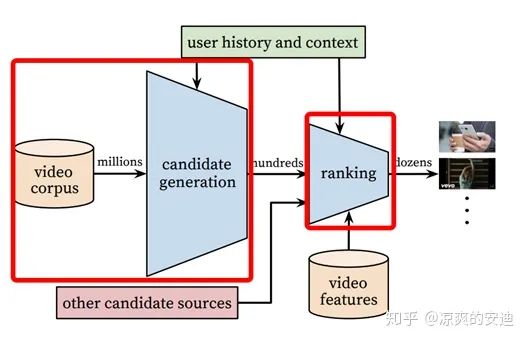
「1-4 推荐系统」
常见的推荐系统一般分为召回、粗排、精排等几个主要的环节(有的推荐系统还包含混排等),根据这几个环节,我罗列了它们各自的特点。

「1-5 潜在应用?」
结合知识蒸馏与推荐系统的特点,我们大胆设想一下,KD与推荐系统结合会有哪些有意思的点呢?
-
在推荐系统的各个阶段都高度要求模型性能。受限于网络延时和性能要求,可以用复杂模型(如带有高阶特征交叉的模型,xDeepFM等)蒸馏的知识指导简单一些的模型进行学习
-
相对于精排模型而言,在粗排和召回里,本身就相对简单。粗排阶段,是否可以不仅仅优化ground-truth目标,是否可以用精排(Teacher网络)输出的知识指导粗排或者召回模型的训练?
2 KD & 推荐
带着上面的设想,我们看一下几个知识蒸馏与推荐系统结合的一些工作。
「2-1 Rocket launching: A universal and efficient framework for training well- performing light net」
「这是一篇将输出迁移应用到推荐系统领域的paper。」
「【诉求】:」
-
精排过程对模型工程性能要求高,复杂的模型(Teacher网络)难以上线
-
通过知识蒸馏将复杂模型(Teacher网络)的知识蒸馏给简单模型(Studentr网络)
「【网络结构】:」
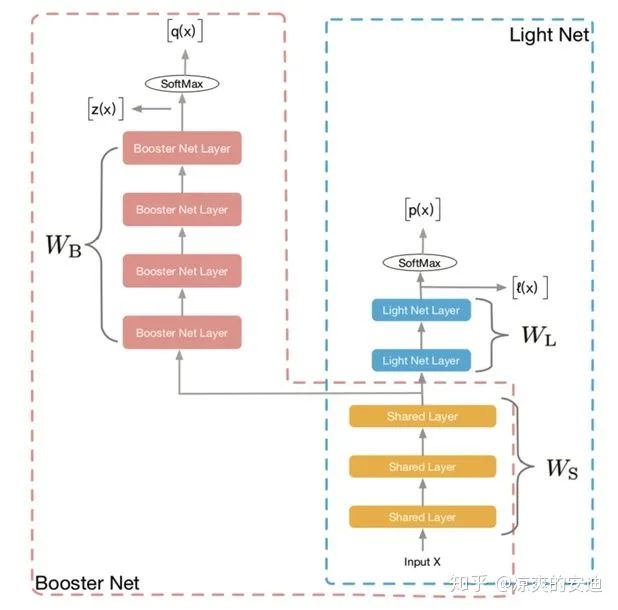
Rocket launching
「【思路】:」
-
设计了两个网络模块Booster(Teacher,红色部分)和Light(Student,蓝色部分)网络
-
Teacher网络和Student网络 「同时进行训练,不再采用经典蒸馏中两阶段训练过程」
-
Teacher网络和Student网络share底层特征参数(黄色部分)
-
Loss分为三个部分,教师网络和学生网络分别与ground-truth目标的交叉熵,教师网络和学生网络输出的差异:
「最终上线的模型是Light Net」
这里有个小问题需要注意,在rocket网络训练时,不再采用经典蒸馏网络两阶段训练的方式会带来一个小问题——教师网络的效果会受到学生网络的负面的影响(Loss加在一起对参数进行优化)。为了避免这一点,作者提出了gradient block的trick:

Rocket launching部分参数的更新方式
-
教师网络独有部分的参数只用教师网络的loss更新
-
学生网络独有部分的参数用学生网络的loss和蒸馏loss更新
-
共享部分的参数用三部分loss更新
「【模型效果】:」
模型在CIFAR-10上的错误率为:

-
WRN-16-1,0.2M——wide resnet(16层,wide参数为1,参数量0.2M);
-
KD——使用经典蒸馏网络后的base模型;
-
1. base——单独使用WRN-16-1训练的网络
-
2. Rocket——用paper的架构训练出的base模型
-
3. Rocket + KD——用paper的架构训练出的base模型,Hint loss使用经典蒸馏网络的loss(带参数温度T)
-
4. Booster——用paper架构训练出的teacher模型
-
5. Booster only——单独训练出的teacher模型
从效果上来看:
-
比较1和2可以发现,采用rocket的蒸馏架构后,小网络从大网络中明显地学习到了“知识”
-
比较4和5可以发现,使用单独的teacher网络训练的得到的结果还是最好的,但是与rocket网络中的大网络错误率接近;这说明gradient block结构比较有效地防止了小网络对于大网络的负面影响
-
比较KD与2可以发现,采用rocket的蒸馏架构后(一阶段训练),小网络的效果优于经典蒸馏网络(两阶段训练)中的小网络的效果。这点我持怀疑态度,感觉这个结论不一定普适于很多场景
此外,论文作者提到Rocket网络的架构使得阿里妈妈广告预估auc提升0.3%。
「2-2 手淘推荐——Privileged Features Distillation at Taobao Recommendations」
「这是一篇将输出迁移应用到推荐系统领域的paper」 。
「【诉求】:」
-
后验知识(点击商品详情页后发生的行为)有价值,但只能离线获取到,线上获取不到
-
通过知识蒸馏,将后验知识蒸馏到网络中
如下图所示,用户点击商品详情页之后会有进一步的行为,比如与客服沟通,看评论等等,这些行为对于推荐商品是有帮助的,但是这些信息在推荐系统实时推荐商品的时候获取不到。
猜你喜欢功能与商品详情页信息
「【网络结构】:」
手淘KD网络结构
**【思路 & Loss】:**
-
teacher网络和Student网络share底层特征参数(X),X*是Privileged Features(后验特征与信息,Teacher独有)
-
teacher网络和Student网络同时进行训练,Student网络拟合teacher网络的输出(输出迁移)
-
λ 系数是控制蒸馏Loss的比例,因为是联合训练,前期教师网络准确度也不高,容易误导学生网络,因此前期λ 较小,后面会慢慢提高
-
最终使用student网络来进行预测
「2-3 爱奇艺推荐——双DNN模型」
「这是一个将输出迁移和特征迁移结合,应用到推荐系统领域的实践」 。
「【诉求】:」
-
Wide & Deep模型转为xDeepFM模型,显式提取特征的高阶组合,提升模型效果
-
新模型QPS过低,不能达到预期
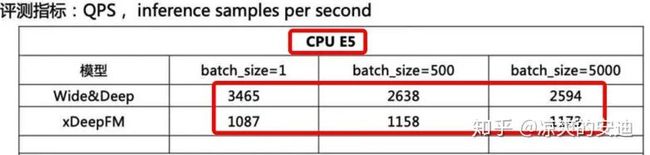
「【网络结构】:」
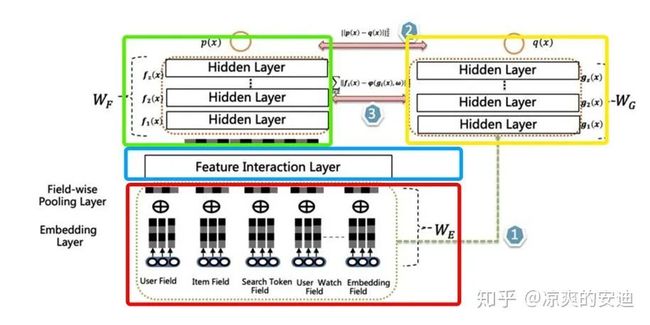
「【思路】——Rocket launching改进:」
-
设计了两个网络模块Teacher网络和Student网络
-
Teacher网络和Student网络同时进行训练
-
Teacher网络(绿框)和Student网络(黄框)share底层特征参数(红框),teacher网络多了Feature Interaction Layer层(该层时teacher网络的核心,可以容纳各种特征交互层)
-
学生网络学习教师网络的隐层输出和Logits输出(特征迁移 + 输出迁移)
最终效果为:

「2-4 Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System」
这篇paper我在 《知识蒸馏简述(二)》 已经分享过,因为是推荐和排序相关paper,有一定借鉴价值,因此也列在这里。
「【诉求】:」
-
检索系统或者推荐系统中模型庞大,可以用蒸馏网络的方式提升工程效率;
-
目标是给一个query,预测检索系统的Top K相关的doc。
「【网络结构】:」
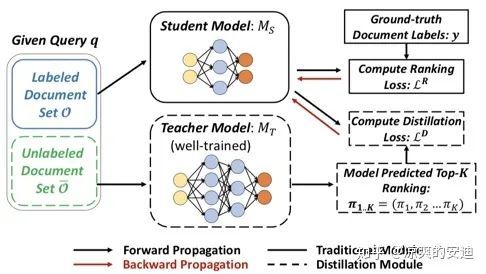
Ranking Distillation网络结构
「【思路】:」
-
第一阶段训练教师网络,对于每个query预测Top K相关doc,补充为学生网络的Ground truth信息;
-
第二阶段教师网络的Top K作为正例加到学生网络中一起进行训练,使得学生网络和教师网络的预测结果更像。
「【Loss】:」
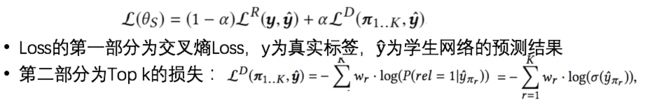
为每条教师网络中预测的样本的权重,有两种方式生成:
-
对位置进行加权(即,Top 1到K的顺序);
-
对排序相关性进行加权(考虑教师网络预测的的Item与query的相关性程度)。
3 Conclusion
-
从整个推荐系统的工作流程和业界的实践来看,在多个环节,知识蒸馏都值得尝试!我们在微信看一看的业务中,对蒸馏网络进行了尝试,效果还不错^_^
-
推荐中每个环节都有可以尝试知识蒸馏的场景:
-
线上模型往往存在性能瓶颈,导致模型不能过于复杂;但为了提升效果,模型“需要”复杂;某些序列模型前向计算很慢(比如RNNs), 这几者是天然冲突的
-
后验知识,在线获取不到但是离线可以获取到
-
「蒸馏在这方面的价值是,可以用简单模型获取部分复杂模型的“收益”」
3. 在工业届的推荐系统精排中,知识蒸馏的效果已经得到了验证;但是粗排中,还鲜有提及。如果打破推荐不同环节之间的壁垒:
-
可以获取每个doc是否点击的信息 + 精排输出的概率、logits等信息;用这些信息来指导粗排、召回模型的训练
-
「蒸馏在这方面的价值是,用复杂模型精排的输出、知识指导粗排」
4. 可以选择输出迁移和特征迁移的方法,低成本进行尝试和迭代。
5. 蒸馏的本质是要定义好“知识”和衡量“知识差异”的函数。对于整个深度网络而言,网络的输出、网络隐藏层输出,网络层与层之间的关系等都可以定义为知识;至于如何衡量“知识差异”,可以采用交叉熵、MSE、KL散度、JS散度等方式来衡量两个输出或者分布的差异,让两个输出越来越“趋同”。
「附原文作者知识蒸馏简述系列文章链接」《知识蒸馏简述(一)》(https://zhuanlan.zhihu.com/p/92166184),《知识蒸馏简述(二)》(https://zhuanlan.zhihu.com/p/92269636)
「参考文献」
-
Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39
-
Romero A , Ballas N , Kahou S E , et al. FitNets: Hints for Thin Deep Nets[J]. Computer Science, 2014.
-
Zhou G, et al. Rocket launching: A universal and efficient framework for training well-performing light net[C]. 2018.
-
Tang J, Wang K. Ranking distillation: Learning compact ranking models with high performance for recommender system[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2289-2298.
-
https:// zhuanlan.zhihu.com/p/143155437
-
https:// blog.csdn.net/weixin_38753262/article/details/104438362