汽车零部件识别算法
背景
- 人工分拣耗时耗力,且分拣正确率不高(60-70%)
- 人工智能领域正在快速发展,其中应用于识别分类方向的深度学习为重点研究方向
技术路线
基于** TensorFlow 框架,实现零件的识别**。
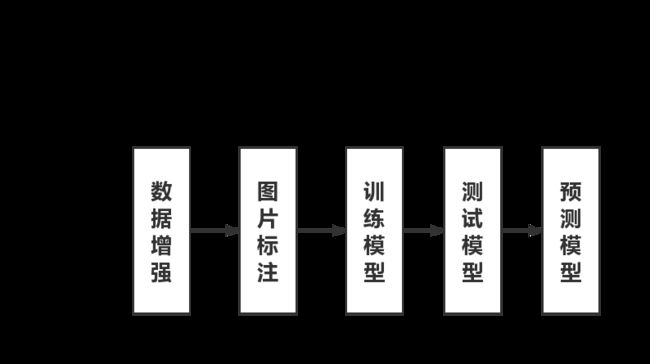
TensorFlow是一个基于数据流编程的符号数学系统,被广泛应 用于各类机器学习算法的编程实现。 本算法由五个部分组成:数据增强、图片标注、训练模型、测试模型、预测模型。数据增强用于对原始收集的图像进行数据扩增,解决初始数据量不足的问题;图片标注,为将各类图片以其特定的文件命名格式进行命名,有利于后期的训练;训练模型,为该算法的核心程序,通过搭建卷积神经网络,进行训练,从而获得最优参数模型;测试模式:通过训练模式所获得的最优参数解,来进行测试集的预测,从而获得正确率,进一步确定训练的效果;预测模型:将未知的图片输入到训练完成的最优参数模型中,从而获得相应的类别。
运行环境
tensorflow 1.5.0
CUDA 9.0.176
CUDNN 7
操作系统:Linux ubuntu 16.04
集成开发、调试及编译环境:pycharm-community-2019.2.1
系统总体结构
该算法基于TensorFlow框架,实现零件的识别。
TensorFlow是一个基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现。
本算法由五个部分组成:数据增强、图片标注、训练模型、测试模型、预测模型。
- 数据增强用于对原始收集的图像进行数据扩增,解决初始数据量不足的问题;
- 图片标注,为将各类图片以其特定的文件命名格式进行命名,有利于后期的训练;
- 训练模型,为该算法的核心程序,通过搭建卷积神经网络,进行训练,从而获得最优参数模型;
- 测试模式:通过训练模式所获得的最优参数解,来进行测试集的预测,从而获得正确率,进一步确定训练的效果;
- 预测模型:将未知的图片输入到训练完成的最优参数模型中,从而获得相应的类别。
数据增强
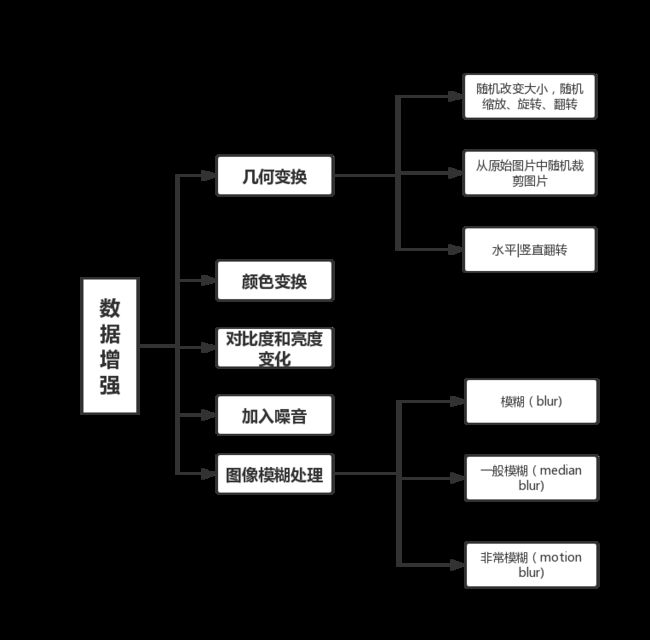
**增强训练数据,就能够提升算法的准确率,因为这样可以避免过拟合,更好地泛化。**主要调用opencv库中的图像处理函数进行按照比例的随机选择图像处理方法,从而对图像进行扩增,其中,图像处理方法,分为几何变换,颜色变换,对比度和亮度变化,加入噪音和图像模糊处理。其中几何变换由分为:随机改变图像的大小,随机进行缩放,旋转,翻转;从原始图像随机裁剪部分图片;图片的水平和竖直翻转。加入噪声主要是对主成分做一个(0,0.1)的高斯扰动。颜色变换为将RGB三个通道的分量大小按照比例进行缩放。对比度和亮度变化为给图片碎甲加一些光照,如锐化,凸点,自适应直方图均衡化等。图像模糊处理分为三个部分:普通模糊,一般模糊和非常模糊处理。
import
cv2
from imgaug import augmenters as iaa
import os
sometimes = lambda aug: iaa.Sometimes(0.5,
aug)
seq = iaa.Sequential([
iaa.SomeOf((0, 5),
[
iaa.Fliplr(0.5),
iaa.Flipud(0.5),
sometimes(
iaa.Superpixels(
p_replace=(0, 1.0),
n_segments=(20, 200)
)
),
iaa.OneOf([
iaa.GaussianBlur((0,
3.0)),
iaa.AverageBlur(k=(2, 7)),
iaa.MedianBlur(k=(3,
11)),
]),
iaa.Sharpen(alpha=(0, 1.0),
lightness=(0.75, 1.5)),
iaa.Emboss(alpha=(0, 1.0),
strength=(0, 2.0)),
iaa.AdditiveGaussianNoise(
loc=0, scale=(0.0, 0.05
* 255)
),
iaa.Invert(0.05,
per_channel=True), # invert color
channels
iaa.AddElementwise((-40,
40)),
iaa.Multiply((0.5, 1.5)),
iaa.MultiplyElementwise((0.5, 1.5)),
iaa.ContrastNormalization((0.5, 2.0)),
],
random_order=True
)
], random_order=True)
path = '/home/ubuntu/coding/test/windshield_wiper/'
imglist = []
folderlist = os.listdir(path)
for item in folderlist:
path1=os.path.join(path,item)
img = cv2.imread(path1)
print('item is ',item)
print('img is ',img)
#images = load_batch(batch_idx)
imglist.append(img)
print('imglist is ' ,imglist)
#print("the length of imglist" +
len(imglist))
print('all the picture have been appent to
imglist')
for count in range(30):
images_aug = seq.augment_images(imglist)
for index in range(len(images_aug)):
filename = str(count) + str(index) + '.jpg'
cv2.imwrite(path + filename, images_aug[index])
print('image of count%s index%s has been writen' % (count, index))
图片标注
为了利于后期的训练,故要将图片的名字按照label_id.jpg的格式进行重命名。其中,label为每一类的标签,其对应关系如表1所示,id为图片的序号,每一张图片有自己的单独的序号。
from PIL import Image
import os
import os.path
import glob
def rename(rename_path, outer_path,
folderlist):# 列举文件夹
for folder in folderlist:
if os.path.basename(folder) == 'doorknod':
foldnum = 0
elif os.path.basename(folder) == 'rearview_mirrow':
foldnum = 1
elif os.path.basename(folder) == 'steering_wheel':
foldnum = 2
elif os.path.basename(folder) == 'wheel':
foldnum = 3
elif os.path.basename(folder) == 'windshield_wiper':
foldnum = 4
inner_path = os.path.join(outer_path, folder)
total_num_folder = len(folderlist)
# 文件夹的总数
# print 'total have %d folders' % (total_num_folder) #打印文件夹的总数
filelist = os.listdir(inner_path)
# 列举图片
i = 0
for item in filelist:
total_num_file = len(filelist) # 单个文件夹内图片的总数
if item.endswith('.jpg'):#endwith
判断字符串是不是以“.jpg"结尾 字符串匹配
src =
os.path.join(os.path.abspath(inner_path), item)
# 原图的地址
#os.path.abspath(_file_): 获得当前脚本的完整路径
dst =
os.path.join(os.path.abspath(rename_path), str(foldnum) + '_' + str(
i)
+
'.jpg')
try:
os.rename(src, dst)
print 'converting %s to %s ...'
% (src, dst)
i += 1
except:
continue
rename_path1 =
'/home/ubuntu/coding/renametrain'
outer_path1 = '/home/ubuntu/coding/train'
folderlist1 =
os.listdir("/home/ubuntu/coding/train")
rename(rename_path1, outer_path1,
folderlist1)
print("train totally rename ! !
!")
rename_path2 =
'/home/ubuntu/coding/renametest'
outer_path2 = '/home/ubuntu/coding/test'
folderlist2 =
os.listdir('/home/ubuntu/coding/test')
rename(rename_path2, outer_path2,
folderlist2)
print("test totally rename ! ! !")
def convertjpg(jpgfile, outdir, width=258,
height=258): # 修改图片尺寸
img = Image.open(jpgfile)
img = img.convert('RGB')
img.save(os.path.join(outdir, os.path.basename(jpgfile)))
new_img = img.resize((width, height), Image.BILINEAR)
new_img.save(os.path.join(outdir, os.path.basename(jpgfile)))
for jpgfile in
glob.glob("/home/ubuntu/coding/renametrain/*.jpg"):
convertjpg(jpgfile, "/home/ubuntu/coding/data")
print("train totally resize ! !
!")
for jpgfile in
glob.glob("/home/ubuntu/coding/renametest/*.jpg"):
convertjpg(jpgfile, "/home/ubuntu/coding/val")
print("test totally
resize ! ! !")训练模型
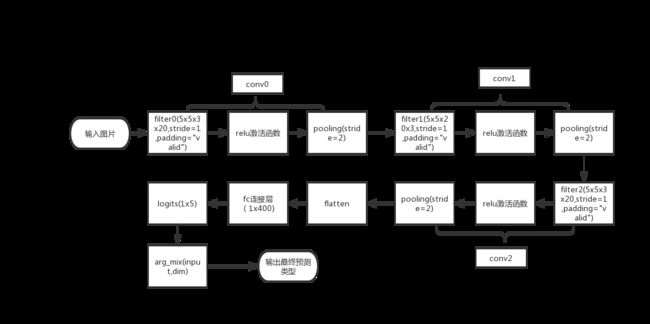
-
CNN:与普通的神经网络相似,具有可学习的权重和偏置常数的神经元组成,每个神经元都接受一些输入,并做一些点积计算,然后算出对应的分类的概率,从而选择出为哪一个类别。
-
过拟合:在样本数目过小导致训练出来的模型在训练集的准确度达到接近1,导致过于贴合训练集的特征,无法对未知的图片进行很好的分辨,泛化能力弱
-
损失函数用于没描述模型和真实值之间的差距大小,本算法选取了交叉熵的损失计算方式(熵是信息量的加权平均数,熵越小,则对应的不确定性越小CEH(p,q)=-∑p(x)logq(x)
p:真实样本分布,q 待估计的模型) -
激活函数:可以使得梯度下降的算法运行的更快。
-
梯度下降:数据不断找到最优解的过程,(学习率)数据迭代的快慢。这个学习率不可以过大,也不可以过小,过大可能会导致无法达到最优解,导致梯度爆炸,过小可以能会导致迭代速率太慢
-
梯度爆炸:初始层的权值过大,导致前面层比后面曾变化更快,导致权值越来越大,从而产生梯度爆炸
发生连乘后会导致权值越来越大,从而导致梯度爆炸=>减小模型层数,或者改用relu,权重大幅更新。 -
梯度消失:反向传播的时候,最后一层的导数几乎为0,根据链式规则,那么最后一层的值几乎为0。=>增大学习率,加深层数。
-
[2.2]最大池化层就是将输入按照[2,2]分开,选取最大的一个值,缩减模型的大小,提高计算速度,同时提高算法的鲁棒性,保留最明显的特征。
-
全连接层可以理解为将最后的输出矩阵全部变成一列,然后再经过softmax的计算得出
-
softmax:输出=ex1/∑exi 从而得到概率最大的一类,作为预测结果。
-
dropout:被丢弃的比例,如果将所有的特征都计算进去,对电脑的计算能力有较大的要求,所以设置随机抛弃部分特征值,优化计算。
-
batch:如果一次将所有的图片都放进去会导致占用过多内存,对电脑算例要求过高,所以采取一次随机挑选batch的图片进行预测。
-
可调整的参数为:迭代次数,dropout,batch等。
datas_placeholder = tf.placeholder(tf.float32, [None, 258, 258, 3])
labels_placeholder = tf.placeholder(tf.int32, [None])
dropout_placeholdr = tf.placeholder(tf.float32) # 存放DropOut参数的容器,训练时为0.25,测试时为0
conv0 = tf.layers.conv2d(datas_placeholder,10,5,padding
='same',activation=tf.nn.relu); #定义卷积层,20个卷积核,卷积核大小为5,用Relu激活
pool0 = tf.layers.max_pooling2d(conv0,[2,2],[2,2]);
conv1 = tf.layers.conv2d(pool0,20,5,padding =
'same',activation=tf.nn.relu);
pool1 = tf.layers.max_pooling2d(conv1,[2,2],[2,2]);
conv2 = tf.layers.conv2d(pool1, 40, 5, activation=tf.nn.relu) # 定义卷积层, 20个卷积核, 卷积核大小为5,用Relu激活
pool2 = tf.layers.max_pooling2d(conv2, [2, 2], [2, 2]) # 定义max-pooling层,pooling窗口为2x2,步长为2x2
conv3 = tf.layers.conv2d(pool2, 60, 5, activation=tf.nn.relu) # 定义卷积层, 40个卷积核, 卷积核大小为4,用Relu激活
pool3 = tf.layers.max_pooling2d(conv3, [2, 2], [2, 2]) # 定义max-pooling层,pooling窗口为2x2,步长为2x2
#conv4 = tf.layers.conv2d(pool3, 60, 3, activation=tf.nn.relu) # 定义卷积层, 60个卷积核, 卷积核大小为3,用Relu激活
flatten = tf.layers.flatten(pool3)
fc1 = tf.layers.dense(flatten, 1000, activation=tf.nn.relu)
fc2 = tf.layers.dense(fc1,100,activation= tf.nn.relu)
dropout_fc = tf.layers.dropout(fc2, dropout_placeholdr)
logits = tf.layers.dense(dropout_fc, 5)
predicted_labels = tf.arg_max(logits, 1)
losses = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, 5),
logits=logits
)
mean_loss = tf.reduce_mean(losses)
optimizer = tf.train.AdamOptimizer(learning_rate=1e-3).minimize(losses)
n = 0
saver = tf.train.Saver()# 用于保存和载入模型
with tf.Session() as sess:
if train:
t1 = time.time()
print("训练模式")
sess.run(tf.global_variables_initializer())
x = []
y = []
for step in range(15000):
pathDir =
os.listdir(data_dir) # 取图片的原始路径
filenumber =
len(pathDir)
rate = 0.03 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber
* rate) # 按照rate比例从文件夹中取一定数量图片
sample =
random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
#print (sample)
os.mkdir('/home/ubuntu/coding/batch')
tarDir='/home/ubuntu/coding/batch'
for name in sample:
origin_dir =
os.path.join(data_dir,name)
tar_dir
=os.path.join(tarDir,name)
shutil.copy(origin_dir, tar_dir)
fpaths, datas, labels =
read_data(tarDir)
train_feed_dict = {
datas_placeholder: datas,
labels_placeholder:
labels,
dropout_placeholdr:
0.25
}
_, mean_loss_val =
sess.run([optimizer, mean_loss], feed_dict=train_ feed_ dict)
if step % 10 == 0:
print("step = {
}\tmean loss =
{
}".format(step, mean_loss_val))
x.append(step)
y.append(mean_loss_val)
shutil.rmtree(tarDir)
saver.save(sess,
model_path)
print("训练结束,保存模型到{}".format(model_path))
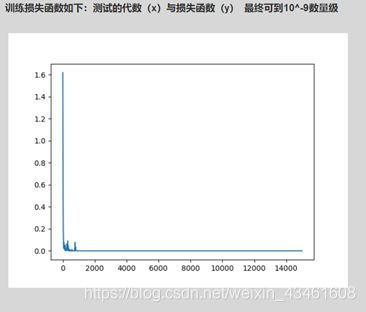
运行结果
生成对应的参数模型