【爬虫修炼和实战】二、从requests开始——爬取喜马拉雅全站音频数据(基础篇)
第二篇为利用爬虫基本的requests库和正则表达式爬取喜马拉雅全站数据。
申明:本文仅做学习用。
多图警告。
目录
一、常用函数和库
二、网站结构分析
首页 https://www.ximalaya.com/
全部分类 https://www.ximalaya.com/category/
基本分类 https://www.ximalaya.com/youshengshu/reci231/
专辑页面 https://www.ximalaya.com/yinyue/24041806/
音频页面 https://www.ximalaya.com/yinyue/24041806/294025103
xm-sign生成
三、代码架构和实现
一、常用函数和库
- re
- requests
- os
- json
- random
二、网站结构分析
-
首页 https://www.ximalaya.com/
首页为一些音乐的推荐,爬取全站只需关注网站的目录索引网址在哪即可。
可发现全部分类的链接为https://www.ximalaya.com/category/,URL地址附加了category字段
-
全部分类 https://www.ximalaya.com/category/
这个网页列出了喜马拉雅全站的所有音频分类和链接,可看做要爬取的根目录。一共有三层目录结构,例如:娱乐-音乐-纯音乐。加粗的推荐和分类下的小类实际都为一部分,目录结构可做保存到本地的文件结构的参考,最终只要获取到此页最小的分类的URL即可,例如:纯音乐 https://www.ximalaya.com/yinyue/reci310/

开发者工具查看源码逐层分析如下:
第一层
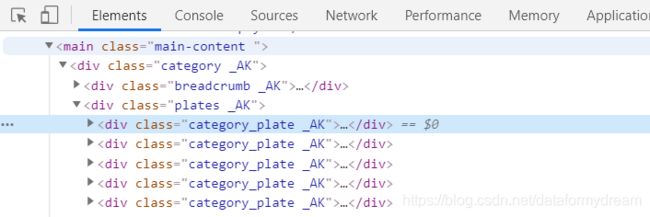
category_plate _AK类一共有5个,分别对应有声小说、娱乐、知识、生活、特色五个大类,需要获取标题名称,创建分类目录用。

标题标签所在:
获取代码:
url_response = ''
# 获取单个
title = re.search('', url_response).group(1)
# 最终获取的是列表
title_list = re.findall('', url_response)第二层
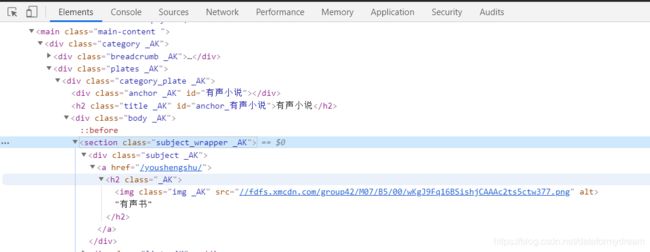
subject_wrapper _AK类为第二层,对应五个大类中的下一类,图中对应有声书,需要获取标题名称,创建分类目录用。

有声书的中文标题在subject_wrapper _AK类下的subject _AK类的h2标签中,类型为_AK:
 有声书
有声书
 有声书
有声书获取代码:
url_response = '有声书
'
title = re.search('.*?>(.*?)
', url_response).group(1)
title_list = re.findall('.*?>(.*?)
', url_response)第三层

item separator _AK类为第三层,对应最小的一类,需要获取的有URL和标题,URL用来请求分类页面,标题创建分类目录用。

这里的URL为一段,和喜马拉雅首页网址拼接即可,例如:https://www.ximalaya.com + /youshengshu/reci231/
HTML格式为:
言情获取URL和标题的代码:
url_response = '言情'
result = re.search('(.*?)', url_response)
url = result.group(1)
title = result.group(2)至此可以通过全部分类https://www.ximalaya.com/category/这个页面获取到所有音频的分类作为本地目录的结构,方便管理和进一步分析,还获取到了最小分类的URL链接字段,用来请求页面,例如:/youshengshu/reci231/
-
基本分类 https://www.ximalaya.com/youshengshu/reci231/
这类页面需要获取的有音乐专辑的URL(一页大概有三十个,用来获取专辑页面)和页数(用来爬取全部音频,图中共有34页)

暂只爬取免费音频,点此查看喜马拉雅的爬虫规则
勾选免费后,URL地址附加了/mr132t2722/字段,https://www.ximalaya.com/youshengshu/reci231/mr132t2722/
选择页码后,URL地址附加了/p%d/字段,%d为页码数,https://www.ximalaya.com/youshengshu/reci231/mr132t2722/p2/
第一页有两种表示方法,带页码:https://www.ximalaya.com/youshengshu/reci231/mr132t2722/p1/
或者不带页码,默认为第一页:https://www.ximalaya.com/youshengshu/reci231/mr132t2722
至此这部分要做的工作有三:
一、获取此分类的页码数,用来遍历所有页面
二、附加免费或其他筛选条件,进行URL拼接,遍历请求所有页面
三、获取所有页面的所有音频专辑URL,例如 https://www.ximalaya.com/youshengshu/15778372/
开发者工具查看源码分别分析如下:
一、获取此分类的页码数,用来遍历所有页面:

使用选择工具查看下方页码UI位置的源代码,1,2,3,4,5,...,34,> 这八个框对应class page-item _Xo 和class page-item page-omit _Xo等属性的li标签,要准确地找到最后一页可以查看‘请输入页码’部分的源码,标签类型为quick-jump _Xo,其中有max="34",为最大页码。
所在HTML标签如下:
获取代码:
url_response = ''
max_page = re.search('
二、附加免费或其他筛选条件,进行URL拼接,遍历请求所有页面:
暂没有找到URL的join函数,遂自己写一个拼接函数
输入:任意个有顺序的URL字段,/符号会自动补全和对齐,多余的删去,可为:
'https://www.ximalaya.com/', 'https://www.ximalaya.com',
'/youshengshu/', '/youshengshu','youshengshu/','youshengshu'
'/214214/','214214/','/214214','214214'
def url_join(*url_list):
full_url = ''
for url in url_list:
url = url.strip('/')
full_url += url + "/"
return full_url
if __name__ == '__main__':
print(url_join('https://www.ximalaya.com/', '/youshengshu/', '/214214/'))
print(url_join('https://www.ximalaya.com/', '/youshengshu/', '/reci231/', '/mr132t2722/', 'p2'))
三、获取页面的所有音频专辑URL:
如图:一页中所有的专辑都在content类的div标签下,每一个音频专辑都是一个li标签,一页有三十个

点开一个li标签,album-wrapper sm _Ht 属性的div标签下有三个子节点,
(网站结构相关),两个分别为专辑信息和作者信息,

Html代码如下:
一吻成瘾:总裁撩不起!|爆笑甜宠免费多人小说
半纸鸿鹊
这里可获取到专辑名(title)、URL(href)、作者(title)、作者详情页(href),代码如下:
url_response1 = '一吻成瘾:总裁撩不起!|爆笑甜宠免费多人小说'
url_response2 = '半纸鸿鹊'
result = re.search('', url_response1)
result2 = re.search('', url_response2)
print(result2.group(1), result2.group(2))
print(result.group(1), result.group(2))
所有的音频专辑可以用re.findall()来获取,作者和专辑的对应关系,还有之前的类别所属关系可以用代码实现来一一对应。
-
专辑页面 https://www.ximalaya.com/yinyue/24041806/
这类页面可以看到音频目录了,和之前类似,需要获取的有每个音频的链接和最大页数,并且获取title作为音频名。

一个
标签对应一个音频链接,获取代码如下:例如 https://www.ximalaya.com/yinyue/24041806/294025103
url_response=''
result=re.search('',url_response)
title=result.group(1)
url=result.group(2)

页码获取方式和之前相同,re.search即可:
url_response=''
max_page = re.search('
-
音频页面 https://www.ximalaya.com/yinyue/24041806/294025103
本页面只关心怎样抓取音频到本地,其实只需要上一步知道音频的ID就可以抓取了,不需要get这个页面,减少运行时间。
目前可以总结出https://www.ximalaya.com/yinyue/24041806/294025103 这种类型URL的结构
/yinyue/24041806/为本专辑所在类别和专辑的ID /294025103为专辑中这首歌的ID
首先要找到音频在哪里,是什么格式,先不点击播放按钮,Ctrl+R刷新一下,选择network下的media选项,此时没有文件,点击播放。

点击播放后, 服务器才反馈了一个m4a格式的音频回来,这个m4a音频就是我们最终要爬取到本地的音频。

点击此音频可以查看是怎么得来的,可以发现https://aod.cos.tx.xmcdn.com/group79/M0A/2C/D7/wKgPEF61_vTQesvyACFUpjNDga8099.m4a
就是要获取的音频地址,request headers中也找到了这个音频的ID的URL ,https://www.ximalaya.com/yinyue/24041806/294025103
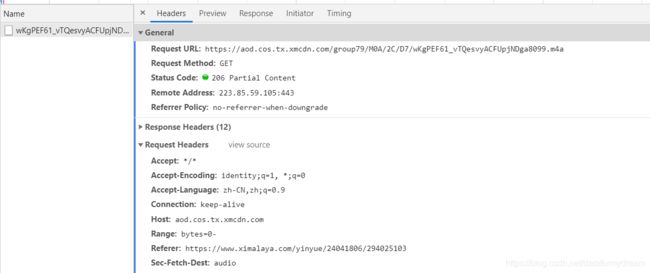
这里音频地址和实际的音频ID并没有什么明显的对应关系,并不能通过音频ID直接获取到音频地址,需要找到发送请求的过程。
发送请求的代码明显在点击播放按钮之后才发生了一次请求。这里选择network下的all选项,显示出音频网页的所有文件。
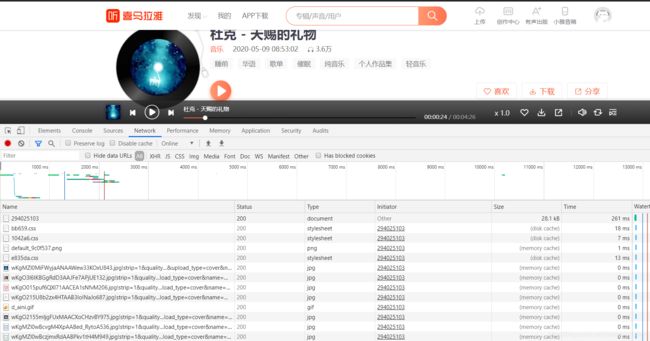
文件条数很多,很难找到点击后那些发生了变化,这里clear一下再点击播放一次。


可以发现发生变化的文件就这么多,m4a格式的为返回的音频,跳过,和音频ID 294025103相关的只有两个,点击查看即可,选择preview选项。

其中show?id开头的preview中找不到音频,跳过。
audio?id=294025103&ptype=1 这个文件即为要找的。

看到了m4a音频地址,正是服务器返回的音频文件地址,查看headers了解请求的URL是什么:

GET方式发送了一个URL,其中带有这个音频的ID,获取到了一个网页。
URL的格式为:https://www.ximalaya.com/revision/play/v1/audio?id=294025103&ptype=1 获取到的即为preview中的内容。
实际上通过音频ID构造了一个URL,向服务器请求了一次,返回的网页中有音频的地址,再拿来播放。
则要爬取音频需要做三件事:
1、构造URL请求服务器
2、在返回的网页中找到音频地址
3、保存音频到本地
代码如下:
id = '294025103'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'xm-sign': '596a655ba451ba8bf2b5541c5b029637(5)1589538181620(70)1589537946332'}
url = f'https://www.ximalaya.com/revision/play/v1/audio?id={id}&ptype=1'
response = requests.get(url, headers=headers)
m4a_url = re.search('"src":"(.*?)"', response.text).group(1)
with open('name.m4a', 'wb') as f:
f.write(requests.get(m4a_url, headers=headers).content)
headers和xm-sign 反爬的问题之后代码会解决,不添加头会被识别出来,只返回一个200的状态码。
-
xm-sign生成
暂参考这两篇博客,具体分析会放到进阶篇。
https://blog.csdn.net/steadyhzc/article/details/99708520
https://blog.csdn.net/BigBoy_Coder/article/details/103406332
至此网站结构分析结束。
三、代码架构和实现
编写多个函数模块,添加了代理池(免费的,很容易挂)、请求头、xm-sign校验,单线程爬取,亲测速度较慢,优点是居然还能用吧,很稳定,居然没报错(滑稽)。耗时主要在获取到m4a文件地址后保存到本地的时间较长,一个居然要10秒左右,浏览器保存只要1-2秒,进阶篇再分析一下,可能跟代理网速有关。。。
若要稳定使用请多添加可用的代理IP,本文仅做学习交流用,实际效率感人,请勿恶意爬取。
已实现功能:
- 代理池随即选取代理
- 遍历爬取全站
- 可指定爬取范围,默认全站全类别
- 已经爬取到本地的不会重复爬取,可获取网站更新
- 建立类别为主的多层目录结构,将所有信息保存到json文件中,方便数据处理
- 交互和显示
#!user/bin/env python
# -*- encoding=utf-8 -*-
import os
import re
import requests
import json
import random
from xm_sign import get_sign
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
" AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/81.0.4044.138 Safari/537.36",
"xm-sign": get_sign()}
root_url = 'https://www.ximalaya.com'
proxies = ['http://180.124.87.176:4216',
'http://182.108.45.238:1624',
'http://180.123.95.218:4216',
'http://115.219.115.184:3000']
# url拼接函数
def url_join(*url_list):
full_url = ''
for url in url_list:
url = url.strip('/')
full_url += url + "/"
return full_url
# 基本的网页请求函数
def get_response(url, referer=None):
try:
headers["xm-sign"] = get_sign()
headers['Referer'] = referer
response = requests.get(url, headers=headers, proxies={'http': random.choice(proxies)}, timeout=None)
# response.raise_for_status()
# print(response.status_code)
response.encoding = response.apparent_encoding
return response
except:
# 失败则重新更新xm-sign一次
print('被识别!去掉代理')
headers["xm-sign"] = get_sign()
response = requests.get(url, headers=headers, timeout=None)
response.encoding = response.apparent_encoding
return response
'''首先爬取全部分类,返回为最小分类的URL字典,外层嵌套列表,以最小分类为列表元素,[{url,板块,大类,小类},{...},...]
例如{'url':'https://www.ximalaya.com/yinyue/reci310/','plate':'娱乐',
'category':'音乐','subcategory':'纯音乐'}代表 纯音乐 这个小类'''
def get_category():
print('获取目录中...')
category = list()
category_url = url_join(root_url, 'category')
response = get_response(category_url)
plate_list = response.text.split('')[1:]
category_number = 0
for plate_html in plate_list:
plate_title = re.search('', plate_html).group(1)
category_list = plate_html.split('')[1:]
category_number += len(category_list)
for category_html in category_list:
category_title = re.search('.*?>(.*?)
', category_html).group(1)
subcategory_list = re.findall('(.*?)', category_html)
for subcategory in subcategory_list:
unit = {'url': url_join(root_url, subcategory[0]), 'plate': plate_title,
'category': category_title, 'subcategory': subcategory[1]}
category.append(unit)
print(f'获取到所有分类!\n{len(plate_list)}个板块,{category_number}个大类,一共有{len(category)}个小类')
return category
'''接着爬取一个分类所有页面的全部音频专辑,返回为音频专辑的URL字典,外层嵌套列表,[{title,url,author,author_url},{...},...]
例如{'url':'https://www.ximalaya.com/youshengshu/35712959/','title':'一吻成瘾:总裁撩不起!|爆笑甜宠免费多人小说',
'author':'半纸鸿鹊','author_url':'/zhubo/13120911/'}代表一个专辑'''
def get_album(category_url):
print('获取此分类所有专辑中...')
album = list()
free_url = url_join(category_url, 'mr132t2722/')
response = get_response(free_url, referer=category_url)
page_number = re.search(r'(.*?)', response.text, re.S)
for album_html in album_list:
album_data = re.search('', album_html)
author_data = re.search('', album_html)
unit = {'url': url_join(root_url, album_data.group(2)), 'title': album_data.group(1),
'author': author_data.group(1), 'author_url': url_join(root_url, author_data.group(2))}
album.append(unit)
print(unit)
print('此分类所有专辑获取完毕!')
return album
'''接着爬取一个专辑所有页面的全部音频id,构造URL请求服务器返回数据,找到m4a地址。
返回为此专辑所有音频的URL字典嵌套列表,[{m4a_id,m4a_url,title},{...},...]
例如{'m4a_id':'294025103','title':'杜克 - 天赐的礼物','m4a_url':
'https://aod.cos.tx.xmcdn.com/group79/M0A/2C/D7/wKgPEF61_vTQesvyACFUpjNDga8099.m4a'}
代表一个音频'''
def get_m4a(album_url):
print('获取此专辑所有音频中...')
m4a = list()
response = get_response(album_url, referer=album_url)
page_number = re.search(r'