差异表达分析(DEG)时 row.names'里不能有重复的名字 的解决方案
最近看到读者留言说在差异表达分析导入矩阵是提醒row name重复,现在就这一问题解释原因和最简单的解决方案。
原因:探针和基因是多对一的关系,比如A和B都可能是指向基因AB。在一般的基因芯片的表达矩阵中,用探针表示的表达矩阵不存在行名重复问题。但是如果先注释成gene symbol,则可能不同行的探针注释成同一个gene symbol。这个时候如果还是用转换后的矩阵进行差异分析,在导入R的时候就会提醒row name充分,这是由于R的规则将行名视为唯一标识符,如果由两个行具有相同的名称,在使用行名取数据的时候,R就不知道需要的是哪一行。
解决方案:通常情况下将不同探针获得的gene symbol按照一定规则合并成一行即可。可以使平均数、中位数、最大值、最小值等,根据自己的需求决定。这个操作可以在R中完成,但是需要一定的编程基础。下面以求平均数为例演示如何使用Excel合并相同的行。
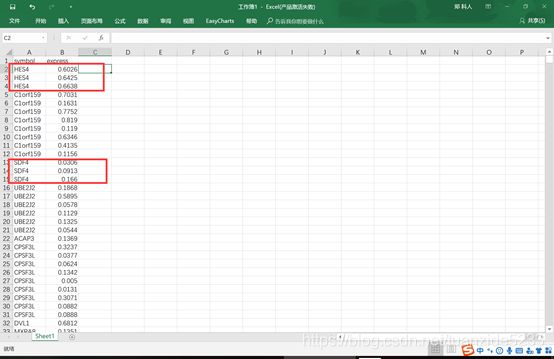
1. 这是一个带有重复行名的表达矩阵,只有一个样本。
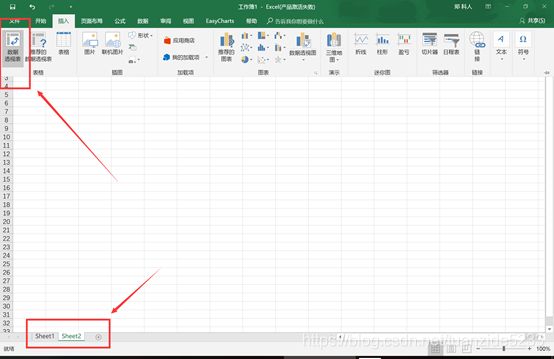
2.新建一个sheet并点击左上角的透视表
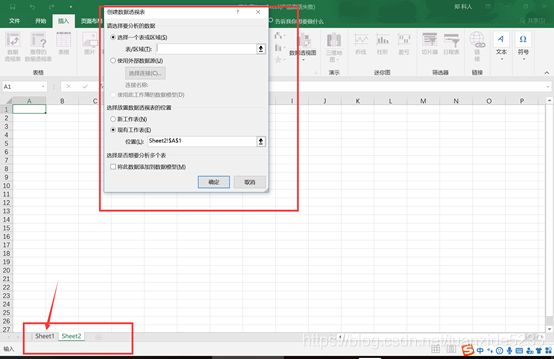
3.出现对话框后回到sheet1选择范围
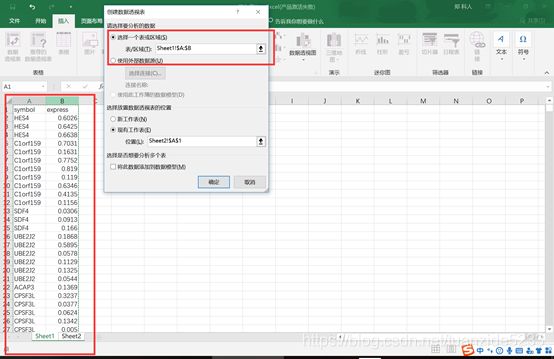
4.在sheet2中勾选需要的列
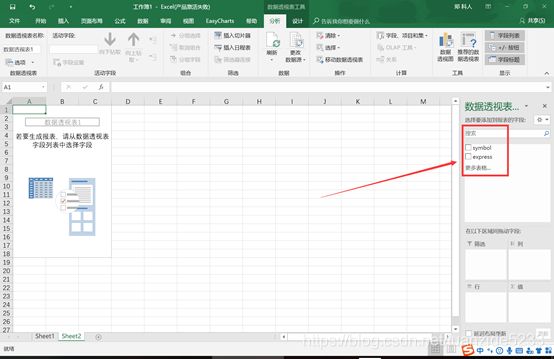
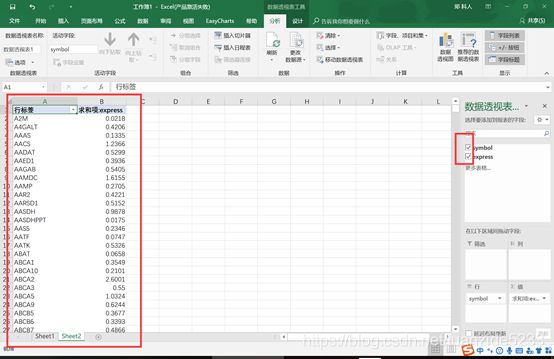
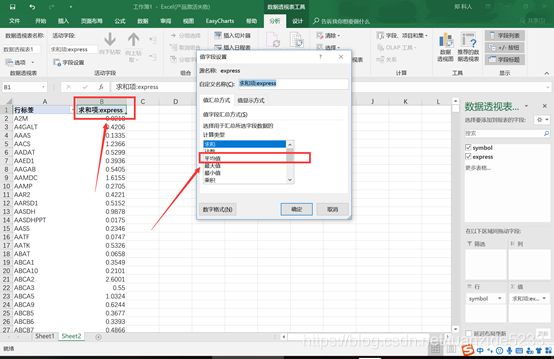
5.双击求和项(B1)在新的对话框中选择平均值,这样名称相同的行就会按照平均值对每个样本进行计算

6.需要说明的是,这种方法可能造成一些gene symbol被识别称日期。不过总的来讲对编程较弱的从业者仍是一种可用可靠的方法。
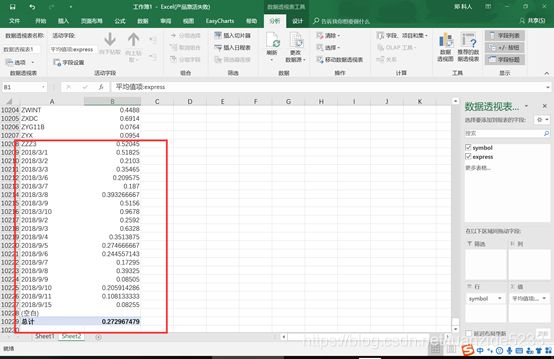
7.将转换后的矩阵导入R就不会出现问题了。
GEO芯片数据差异表达分析时需要log2处理的原因
https://blog.csdn.net/tuanzide5233/article/details/88542805
GEO芯片数据差异表达分析时是否需要log2以及标准化的问题
https://blog.csdn.net/tuanzide5233/article/details/88542558
差异表达矩阵制作教程
https://blog.csdn.net/tuanzide5233/article/details/83659768
差异表达的热图绘制详见
https://blog.csdn.net/tuanzide5233/article/details/83659501
使用edgeR对RNAseq数据进行差异表达分析教程
https://blog.csdn.net/tuanzide5233/article/details/88785486
差异表达分析(DEG)时 row.names'里不能有重复的名字 的解决方案
https://blog.csdn.net/tuanzide5233/article/details/86568155
生存分析系列教程(一)使用生信人工具盒进行生存分析
https://blog.csdn.net/tuanzide5233/article/details/83685403
富集分析与蛋白质互作用网络(PPI)的可视化 Cystocape入门指南
https://blog.csdn.net/tuanzide5233/article/details/88048439
进阶版Venn plot:Upset plot入门实战代码详解——UpSetR包介绍
https://blog.csdn.net/tuanzide5233/article/details/83109527
使用R语言ggplot2包绘制pathway富集分析气泡图(Bubble图):数据结构及代码
https://blog.csdn.net/tuanzide5233/article/details/82141817