注意力机制大总结
①SEnet
SEnet(Squeeze-and-Excitation Network)考虑了特征通道之间的关系,在特征通道上加入了注意力机制。
SEnet通过学习的方式自动获取每个特征通道的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。SEnet通过Squeeze模块和Exciation模块实现所述功能。

如上图所示,首先作者通过squeeze操作,对空间维度进行压缩,直白的说就是对每个特征图做全局池化,平均成一个实数值。该实数从某种程度上来说具有全局感受野。作者提到该操作能够使得靠近数据输入的特征也可以具有全局感受野,这一点在很多的任务中是非常有用的。紧接着就是excitaton操作,由于经过squeeze操作后,网络输出了1*1*C大小的特征图,作者利用权重w来学习C个通道直接的相关性。在实际应用时有的框架使用全连接,有的框架使用1*1的卷积实现,从参数计算角度我更加推荐使用1*1卷积,也就是下面代码中的fc2操作。该过程中作者先对C个通道降维再扩展回C通道。好处就是一方面降低了网络计算量,一方面增加了网络的非线性能力。最后一个操作时将exciation的输出看作是经过特征选择后的每个通道的重要性,通过乘法加权的方式乘到先前的特征上,从事实现提升重要特征,抑制不重要特征这个功能。
#https://github.com/Amanbhandula/AlphaPose/blob/master/train_sppe/src/models/layers/SE_module.py
class SELayer(nn.Module):
def __init__(self, channel, reduction=1):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Sequential(
nn.Linear(channel, channel / reduction),
nn.ReLU(inplace=True),
nn.Linear(channel / reduction, channel),
nn.Sigmoid())
self.fc2 = nn.Sequential(
nn.Conv2d(channel , channel / reduction, 1, bias=False)
nn.ReLU(inplace=True),
nn.Conv2d(channel , channel / reduction, 1, bias=False)
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc1(y).view(b, c, 1, 1)
return x * y②CBAM
CBAM(Convolutional Block Attention Module)结合了特征通道和特征空间两个维度的注意力机制。
CBAM通过学习的方式自动获取每个特征通道的重要程度,和SEnet类似。此外还通过类似的学习方式自动获取每个特征空间的重要程度。并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。

CBAM提取特征通道注意力的方式基本和SEnet类似,如下ChannelAttention中的代码所示,其在SEnet的基础上增加了max_pool的特征提取方式,其余步骤是一样的。将通道注意力提取厚的特征作为空间注意力模块的输入。

CBAM提取特征空间注意力的方式:经过ChannelAttention后,最终将经过通道重要性选择后的特征图送入特征空间注意力模块,和通道注意力模块类似,空间注意力是以通道为单位进行最大和平均迟化,并将两者的结果进行concat,之后再一个卷积降成1*w*h的特征图空间权重,再将该权重和输入特征进行点积,从而实现空间注意力机制。
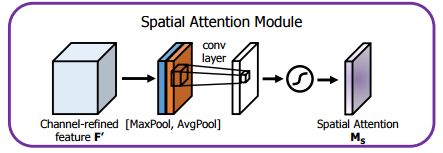
#https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes / 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes / 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)③ECAnet
上述提到的所有方法致力于开发更复杂的注意力模块,以获得更好的性能,不可避免地增加了计算负担。为了克服性能与复杂度权衡的悖论,ECANet就是一种用于提高深度CNNs性能的超轻注意模块。ECA模块,它只涉及k (k=9)参数,但带来了明显的性能增益。ECA模块通过分析SEnet的结构了解到降维和跨通道交互的影响,作者通过实验证明了降维是没有作用的(讲道理和我之前想的一样,,),并通过自适应内核大小的一维卷积实现局部跨通道的信息交互。
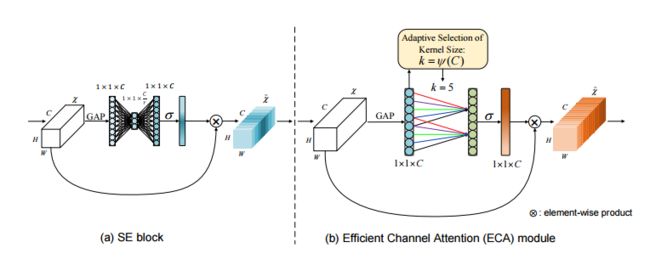
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2))
y = y.transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)④CASR
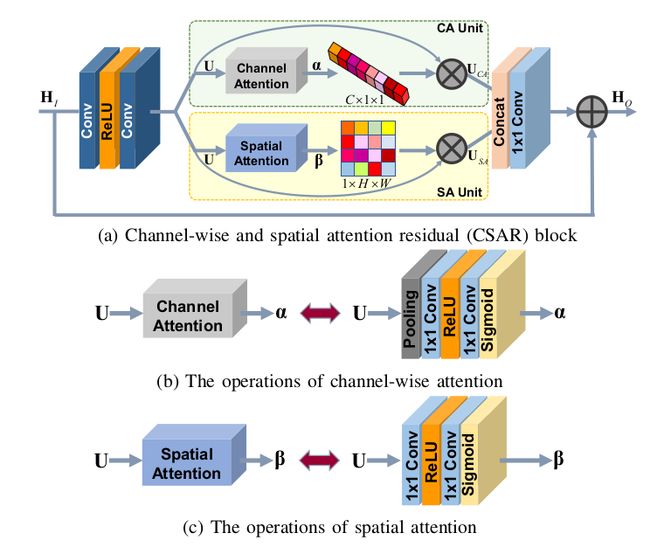
进来一个特征 Hi,先经过卷积-ReLU-卷积得到特征 U,卷积核都为 3×3。
CA 单元包含全局空间池化-卷积-ReLU-卷积-Sigmoid,卷积核都为 1×1,第一层卷积通道数变为 C/r,第二层卷积通道数为 C。
SA 单元包含卷积-ReLU-卷积-Sigmoid,卷积核都为 1×1,第一层卷积通道数变为 C*i,第二层卷积通道数为 1。
得到通道和空间的两个 mask 后,分别和特征 U 相乘,然后再将两个结果拼接起来经过一个 1×1 的卷积将通道数变为 C,最后和 Hi 相加得到输出特征 Ho。
在论文中,作者设置 r=16,i=2,CSAR 的一个 TensorFlow 实现如下所示。
def CSAR(input, reduction, increase):
"""
@Channel-wise and Spatial Feature Modulation Network for Single Image Super-Resolution
Channel-wise and spatial attention residual block
"""
_, width, height, channel = input.get_shape() # (B, W, H, C)
u = tf.layers.conv2d(input, channel, 3, padding='same', activation=tf.nn.relu) # (B, W, H, C)
u = tf.layers.conv2d(u, channel, 3, padding='same') # (B, W, H, C)
# channel attention
x = tf.reduce_mean(u, axis=(1, 2), keepdims=True) # (B, 1, 1, C)
x = tf.layers.conv2d(x, channel // reduction, 1, activation=tf.nn.relu) # (B, 1, 1, C // r)
x = tf.layers.conv2d(x, channel, 1, activation=tf.nn.sigmoid) # (B, 1, 1, C)
x = tf.multiply(u, x) # (B, W, H, C)
# spatial attention
y = tf.layers.conv2d(u, channel * increase, 1, activation=tf.nn.relu) # (B, W, H, C * i)
y = tf.layers.conv2d(y, 1, 1, activation=tf.nn.sigmoid) # (B, W, H, 1)
y = tf.multiply(u, y) # (B, W, H, C)
z = tf.concat([x, y], -1)
z = tf.layers.conv2d(z, channel, 1, activation=tf.nn.relu) # (B, W, H, C)
z = tf.add(input, z)
return z