PyTorch深度学习实战(33)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(33)——条件生成对抗网络
-
- 0. 前言
- 1. 条件生成对抗网络
-
- 1.1 模型介绍
- 1.2 模型与数据集分析
- 2. 实现条件生成对抗网络
- 小结
- 系列链接
0. 前言
条件生成对抗网络 (Conditional Generative Adversarial Network, CGAN) 是一种生成对抗网络 (Generative Adversarial Network, GAN),旨在通过给定特定条件信息的情况下生成符合条件的合成数据。这种网络结构通常用于生成图片、音频、文本等多种类型的数据。条件生成网络的核心思想是将条件信息与潜在空间中的噪声向量进行联合建模,以生成与条件一致的输出。常见的条件信息可以是类别标签、文本描述、图像特征等,这些信息可以指导网络生成具有特定属性、风格或类别的数据样本。在本节中,将构建 CGAN 根据条件向量生成指定性别的人脸图像。
1. 条件生成对抗网络
1.1 模型介绍
条件生成对抗网络 (Conditional Generative Adversarial Network, CGAN) 是生成对抗网络的一种扩展,它同时接受噪声数据和条件数据作为输入,以控制生成的数据样本。与标准的生成对抗网络 (Generative Adversarial Network, CGAN)不同,输入到 CGAN 的随机噪声向量和条件向量一起传递到生成网络中,以生成具有所需特征的样本,条件向量可以是数字或对象的标签,这样生成网络可以控制生成出来的图像具有特定的属性,例如,猫或狗的图像,或戴眼镜的人的图像。
条件生成网络由两部分组成:生成网络和判别网络。生成网络负责接收条件信息和噪声向量,通过一系列的神经网络层逐步生成合成数据。判别网络则用于评估生成的数据与真实数据之间的差异,以辨别生成数据的真实性。生成网络和判别网络通过对抗训练的方式相互竞争和改进,从而提高生成网络的性能。
条件生成网络的应用非常广泛。例如,在图像生成领域,条件生成网络可以根据特定的类别标签生成具有特定特征或风格的图像;在文本生成领域,条件生成网络可以根据给定的文本描述生成相应的文本段落或文章。
1.2 模型与数据集分析
为了训练对抗生成网络,我们需要了解本节所用的数据集,本节同样使用在 DCGAN 一节中介绍的人脸图像数据集,下载地址:https://pan.baidu.com/s/1dvDCBLSGwblg57p9RDBEJQ,提取码:y9fi。数据集包含男性和女性的面部图像及其相应的标签,在本节中,我们将学习如何根据随机噪声与条件向量生成指定性别的人脸图像,模型训练策略如下:
- 将图像标签转换为独热编码格式
- 将标签通过嵌入层以生成每个类别的多维表示
- 生成随机噪声并与嵌入层输出相连接
- 训练模型
2. 实现条件生成对抗网络
接下来,使用 PyTorch 根据以上分析实现条件生成对抗网络,构建条件生成对抗网络根据噪声和条件向量生成指定类别图像。
(1) 导入相关库:
from torchvision import transforms
import torchvision.utils as vutils
import cv2, numpy as np
import torch
import os
from glob import glob
from PIL import Image
from torch import nn, optim
from torch.utils.data import DataLoader, Dataset
from matplotlib import pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
(2) 创建数据集和数据加载器。
存储男性和女性图像路径:
female_images = glob('male_female_face_images/females/*.jpg')
male_images = glob('male_female_face_images/males/*.jpg')
裁剪图像,只保留面部区域并丢弃图像中的其他部分。首先,使用级联滤波器识别图像中的人脸:
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
OpenCV 提供了 4 个级联分类器用于人脸检测,可以从 OpenCV 官方下载这些级联分类器文件:
haarcascade_frontalface_alt.xml(FA1)haarcascade_frontalface_alt2.xml(FA2)haarcascade_frontalface_alt_tree.xml(FAT)haarcascade_frontalface_default.xml(FD)
创建两个新文件夹(一个对应男性,另一个对应女性图像)并将所有裁剪的人脸图像转储到相应的文件夹中:
if not os.path.exists('cropped_faces_female'):
os.mkdir('cropped_faces_female')
if not os.path.exists('cropped_faces_male'):
os.mkdir('cropped_faces_male')
for i in range(len(female_images)):
img = cv2.imread(female_images[i],1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
img2 = img[y:(y+h),x:(x+w),:]
cv2.imwrite('cropped_faces_female/'+str(i)+'.jpg', img2)
for i in range(len(male_images)):
img = cv2.imread(male_images[i],1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
img2 = img[y:(y+h),x:(x+w),:]
cv2.imwrite('cropped_faces_male/'+str(i)+'.jpg', img2)
定义要对每个图像执行的转换:
transform=transforms.Compose([
transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
创建 Faces 数据集类,返回图像和其中人物的相应性别:
class Faces(Dataset):
def __init__(self, folders):
super().__init__()
self.folderfemale = folders[0]
self.foldermale = folders[1]
self.images=sorted(glob(self.folderfemale))+sorted(glob(self.foldermale))
def __len__(self):
return len(self.images)
def __getitem__(self, ix):
image_path = self.images[ix]
image = Image.open(image_path)
image = transform(image)
gender = np.where('female' in str(image_path),1,0)
return image, torch.tensor(gender).long()
创建数据集对象 ds 和数据加载器:
ds = Faces(folders=['cropped_faces_female/*.jpg','cropped_faces_male/*.jpg'])
dataloader = DataLoader(ds, batch_size=64, shuffle=True, num_workers=8)
(3) 定义权重初始化函数,使权重的分布较小:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
(4) 定义判别网络模型类。
定义模型架构:
class Discriminator(nn.Module):
def __init__(self, emb_size=32):
super(Discriminator, self).__init__()
self.emb_size = 32
self.label_embeddings = nn.Embedding(2, self.emb_size)
self.model = nn.Sequential(
nn.Conv2d(3,64,4,2,1,bias=False),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64,64*2,4,2,1,bias=False),
nn.BatchNorm2d(64*2),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64*2,64*4,4,2,1,bias=False),
nn.BatchNorm2d(64*4),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64*4,64*8,4,2,1,bias=False),
nn.BatchNorm2d(64*8),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64*8,64,4,2,1,bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2,inplace=True),
nn.Flatten()
)
self.model2 = nn.Sequential(
nn.Linear(288,100),
nn.LeakyReLU(0.2,inplace=True),
nn.Linear(100,1),
nn.Sigmoid()
)
self.apply(weights_init)
在模型类中,CGAN 使用附加参数 emb_size,emb_size 表示将输入类别标签转换成的嵌入尺寸,并将转换后的嵌入存储为 label_embeddings。将输入类别标签从独热编码形式转换为高维嵌入,以便模型具有更高的调整自由度以处理不同的类别。虽然模型类与 DCGAN 类似,不同之处在于,CGAN 还需要初始化另一个用于执行分类任务的模型 model2。
定义前向计算方法 forward,将图像和图像的标签作为输入:
def forward(self, input, labels):
x = self.model(input)
y = self.label_embeddings(labels)
input = torch.cat([x, y], 1)
final_output = self.model2(input)
return final_output
在 forward 方法中,获取第一个模型的输出 self.model(input) 和通过 label_embeddings 传递标签的输出,然后将这些输出连接起来。接下来,将连接后的输出传递给第二个模型 self.model2,从而获取判别网络的输出。
self.model2 的输入维度为 288,因为 self.model 的每个数据样本输出结果有 256 个值,然后将其与输入类别标签的 32 个嵌入值连接起来,因此总共有 256 + 32 = 288 个输入值传递给 self.model2。
(5) 定义生成网络类 Generator。
定义 __init__ 方法:
class Generator(nn.Module):
def __init__(self, emb_size=32):
super(Generator,self).__init__()
self.emb_size = emb_size
self.label_embeddings = nn.Embedding(2, self.emb_size)
在以上代码中,使用 nn.Embedding 将 2D 输入(类别标签)转换为 32 维向量 (self.emb_size):
self.model = nn.Sequential(
nn.ConvTranspose2d(100+self.emb_size,64*8,4,1,0,bias=False),
nn.BatchNorm2d(64*8),
nn.ReLU(True),
nn.ConvTranspose2d(64*8,64*4,4,2,1,bias=False),
nn.BatchNorm2d(64*4),
nn.ReLU(True),
nn.ConvTranspose2d(64*4,64*2,4,2,1,bias=False),
nn.BatchNorm2d(64*2),
nn.ReLU(True),
nn.ConvTranspose2d(64*2,64,4,2,1,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64,3,4,2,1,bias=False),
nn.Tanh()
)
在以上代码中,利用 nn.ConvTranspose2d 执行上采样得到图像作为输出。
应用权重初始化:
self.apply(weights_init)
定义前向计算方法 forward,将随机噪声 (input_noise) 和输入标签 (labels) 作为输入生成图像输出:
def forward(self,input_noise,labels):
label_embeddings = self.label_embeddings(labels).view(len(labels), self.emb_size, 1, 1)
input = torch.cat([input_noise, label_embeddings], 1)
return self.model(input)
实例化生成网络与判别网络对象:
generator = Generator().to(device)
discriminator = Discriminator().to(device)
(6) 定义函数 noise() 生成随机噪声并将其注册到设备中:
def noise(size):
n = torch.randn(size, 100, 1, 1, device=device)
return n.to(device)
(7) 定义判别网络训练函数 discriminator_train_step()。
判别网络包含 4 个输入,真实图像 (real_data)、真实图像标签 (real_labels)、生成图像 (fake_data)、生成图像标签 (fake_labels)、损失函数 (loss) 和优化器 (d_optimizer):
def discriminator_train_step(real_data, real_labels, fake_data, fake_labels, loss, d_optimizer):
d_optimizer.zero_grad()
在以上代码中,重置判别网络对应的梯度。
计算对应于真实数据预测 (prediction_real) 的损失值,将 real_data 和 real_labels 通传递到判别网络中,输出的预测结果与期望值 (torch.ones(len(real_data),1).to(device)) 进行比较,得到损失 error_real 后执行反向传播:
prediction_real = discriminator(real_data, real_labels)
error_real = loss(prediction_real, torch.ones(len(real_data), 1).to(device))
error_real.backward()
计算对应于生成数据预测 (prediction_fake) 的损失值,将 fake_data 和 fake_labels 传递到判别网络中,输出的预测结果与期望 (torch.zeros(len(fake_data),1).to(device)) 进行比较,得到损失 error_fake 后执行反向传播:
prediction_fake = discriminator(fake_data, fake_labels)
error_fake = loss(prediction_fake, torch.zeros(len(fake_data), 1).to(device))
error_fake.backward()
更新权重并返回损失值:
d_optimizer.step()
return error_real + error_fake
(8) 定义生成网络训练函数,将生成图像 (fake_data) 和生成图像标签 (fake_labels) 作为输入传递:
def generator_train_step(fake_data, fake_labels, loss, g_optimizer):
g_optimizer.zero_grad()
prediction = discriminator(fake_data, fake_labels)
error = loss(prediction, torch.ones(len(fake_data), 1).to(device))
error.backward()
g_optimizer.step()
return error
generator_train_step 函数类似于 discriminator_train_step,不同之处在于 generator_train_step 函数的期望输出是 torch.ones(len(fake_data),1).to(device))。
(9) 定义生成网络和判别网络模型对象、损失优化器和损失函数:
discriminator = Discriminator().to(device)
generator = Generator().to(device)
loss = nn.BCELoss()
d_optimizer = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
g_optimizer = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
fixed_noise = torch.randn(64, 100, 1, 1, device=device)
fixed_fake_labels = torch.LongTensor([0]*(len(fixed_noise)//2) + [1]*(len(fixed_noise)//2)).to(device)
loss = nn.BCELoss()
n_epochs = 80
img_list = []
d_loss_epoch = []
g_loss_epoch = []
在以上代码中,定义 fixed_fake_labels 时,指定一半图像对应类别 0,另一半对应于类别 1,并定义 fixed_noise 用于根据随机噪声生成图像。
(10) 训练模型。
遍历批图像及其标签:
for epoch in range(n_epochs):
N = len(dataloader)
d_loss_items = []
g_loss_items = []
for bx, (images, labels) in enumerate(dataloader):
初始化 real_data 和 real_labels:
real_data, real_labels = images.to(device), labels.to(device)
初始化 fake_data 和 fake_labels:
fake_labels = torch.LongTensor(np.random.randint(0, 2, len(real_data))).to(device)
fake_data = generator(noise(len(real_data)), fake_labels)
fake_data = fake_data.detach()
使用 discriminator_train_step 函数训练判别网络以计算判别网络损失 (d_loss):
d_loss = discriminator_train_step(real_data, real_labels, fake_data, fake_labels, loss, d_optimizer)
重新利用生成网络生成图像 (fake_data) 和图像标签 (fake_labels) 并使用 generator_train_step 函数训练生成网络,计算生成网络损失 (g_loss):
fake_labels = torch.LongTensor(np.random.randint(0, 2, len(real_data))).to(device)
fake_data = generator(noise(len(real_data)), fake_labels).to(device)
g_loss = generator_train_step(fake_data, fake_labels, loss, g_optimizer)
记录模型训练过程中的关键指标:
d_loss_items.append(d_loss.item())
g_loss_items.append(g_loss.item())
d_loss_epoch.append(np.average(d_loss_items))
g_loss_epoch.append(np.average(g_loss_items))
训练完成后,测试模型生成图像:
if (epoch+1) % 20 == 0:
with torch.no_grad():
fake = generator(fixed_noise, fixed_fake_labels).detach().cpu()
imgs = vutils.make_grid(fake, padding=2, normalize=True).permute(1,2,0)
img_list.append(imgs)
plt.imshow(imgs)
plt.show()
在以上代码中,将噪声 (fixed_noise) 和标签 (fixed_fake_labels) 传递给生成网络以生成图像,训练结束后,模型的输出结果如下所示:
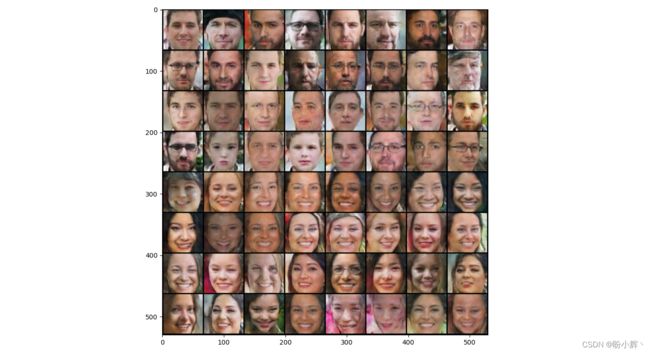
从上图中,我们可以看到前 32 幅图像对应男性图像,而后 32 幅图像对应女性图像。
小结
条件生成对抗网络通过整合条件信息和潜在空间噪声,能够根据特定的条件生成具有一定属性或风格的合成数据,为许多创造性和应用型任务提供了强大的工具和手段。本节中,介绍了条件生成对抗网络的基本原理,并利用 PyTorch 实现条件生成对抗网络生成指定性别的人脸图像。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(27)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(28)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(29)——神经风格迁移
PyTorch深度学习实战(30)——Deepfakes
PyTorch深度学习实战(31)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(32)——DCGAN详解与实现