算法的时间复杂度和空间复杂度
所有Leetcode题目不定期汇总在 Github, 欢迎大家批评指正,讨论交流。
趁假期复习了算法基础的时间复杂度和空间复杂度,整理一遍。
原文发布于个人博客(好望角),并在博客持续修改更新,此处可能更新不及时。
算法的有效性
要想理解时间复杂度和空间复杂度这两个概念,首先要明白算法的含义。
所谓算法,是解决一类问题的通法,即一系列清晰无歧义的计算指令。
具体的,一个算法应该有以下五个方面的特性:
- 输入(Input):算法必须有输入量,用以刻画算法的初始条件(特殊情况也可以没有输入量,这时算法本身定义了初始状态);
- 输出(Output):算法应有一个或以上输出量,输出量是算法计算的结果。没有输出的算法毫无意义。
- 明确性(Definiteness):算法的描述必须无歧义,以保证算法的实际执行结果是精确地匹配要求或期望,通常要求实际运行结果是确定的。
- 有限性(Finiteness):算法必须在有限个步骤内完成任务。
- 有效性(Effectiveness):算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现(又称可行性)。
根据以上的定义,不难发现。每个算法只能解决具有特定特征的一类问题。然而,每个有固定输入输出的问题可以采取多种算法来决解。
那么,要怎么来比较解决同一个问题的不同算法之间的优劣呢?
这个时候,时间复杂度和空间复杂度就有了用武之地。
时间复杂度
算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好反映出算法的优劣与否。
验证算法的时间复杂度,我们有以下两个方法。
事后统计
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。所以就有了事后统计的方法。
计算算法的时间复杂度,往往是为了评测算法的性能,设计更好的算法。这就给事后统计的方法带来了两个弊端。
- 需要先实现算法设计,并至少运行一次。
- 统计算法时间容易受到计算机硬件、编程语言效率等环境因素影响。
事前分析
由于事后统计的方法有上述的弊端,我们通常采取事先估计的方法来评价算法的时间复杂度。
为了更好的比较不同算法在处理统一问题上的效率,通常从算法中选取一种对于所研究的问题(或算法类型)来说是基本操作的原操作,以该基本操作的重复执行的次数作为算法的时间量度,记为T(n)。
在这里,n为输入问题的规模。对于同一个问题来说,他的输入规模越大,往往时间复杂度也就越大。
关于输入问题规模n,有辅助函数f(n),来统计算法基本操作的频度。因此,算法的时间复杂度往往记为 T ( n ) = O ( f ( n ) ) T(n)=O(f(n)) T(n)=O(f(n))。
为了简便,我们一般在计算时间复杂度往往选取最简单的f(n)表示。例如: O ( 2 n 2 + n + 1 ) = O ( 3 n 2 + n + 3 ) = O ( 7 n 2 + n ) = O ( n 2 ) O(2n^2+n+1) = O (3n^2+n+3) = O(7n^2+n) = O(n_2) O(2n2+n+1)=O(3n2+n+3)=O(7n2+n)=O(n2) ,一般都只用 O ( n 2 ) O(n_2) O(n2)表示就可以了。
也就是说,两个算法的时间频度不一样,但很有可能拥有相同的时间复杂度。
例如: T ( n ) = n 2 + 3 n + 4 T(n)=n^2+3n+4 T(n)=n2+3n+4 与 T ( n ) = 4 n 2 + 2 n + 1 T(n)=4n^2+2n+1 T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为 O ( n 2 ) O(n^2) O(n2)。
常见的算法时间复杂度由小到大依次为:
O ( 1 ) < O ( l o g 2 ( n ) ) < O ( n ) < O ( n l o g 2 ( n ) ) < O ( n 2 ) < O ( n 3 ) < . . . < O ( n ! ) O(1)<O(log_2(n))<O(n)<O(nlog_2(n))<O(n^2)<O(n^3)<...<O(n!) O(1)<O(log2(n))<O(n)<O(nlog2(n))<O(n2)<O(n3)<...<O(n!)
下面的图片直观的表示他们之间复杂度关系。
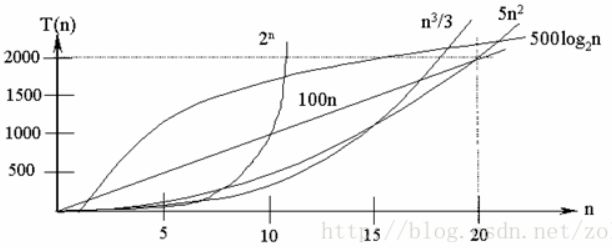
时间复杂度的分类
- 最坏时间复杂度:输入数据状态最不理想情况下的时间复杂度,也就是算法时间复杂度的上界。若没有特别声明,时间复杂度就是指最坏时间复杂度。
- 平均时间复杂度:在所有可能的输入实例均以等概率出现的情况下,算法的期望时间复杂度。
- 最好时间复杂度:输入数据状态最理想情况下的时间复杂度。
时间复杂度预估步骤
- 找出基本语句:算法中执行次数最多的那条语句就是基本语句,通常是最内层循环的循环体。
- 计算基本语句的执行次数的数量级:只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率。
- 用O()表示算法的时间性能:将基本语句执行次数的数量级放入O()中。
时间复杂度分析技巧
- 简单语句:程序的输入输出、赋值等语句都近似认为需要 O ( 1 ) O(1) O(1)时间。
- 顺序结构:需要依次执行一系列语句所用的时间可采用O()的"求和法则",
- 选择结构:如if语句,它的主要时间耗费是在执行then字句或else字句所用的时间,需注意的是检验条件也需要 O ( 1 ) O(1) O(1)时间。
- 循环结构:循环语句的运行时间主要体现在多次迭代中执行循环体以及检验循环条件的时间耗费,一般可用O()的"乘法法则"。
- 复杂算法:将其分成几个容易估算的部分,然后利用求和法则和乘法法则计算整个算法的时间复杂度。
- 其他准则
- 若 g ( n ) = O ( f ( n ) ) g(n)=O(f(n)) g(n)=O(f(n)),则 O ( f ( n ) ) + O ( g ( n ) ) = O ( f ( n ) ) O(f(n))+ O(g(n))= O(f(n)) O(f(n))+O(g(n))=O(f(n))
- O ( C f ( n ) ) = O ( f ( n ) ) O(Cf(n)) = O(f(n)) O(Cf(n))=O(f(n)) , 其中C是一个正常数。
乘法法则: 是指若算法的2个部分时间复杂度分别为 T 1 ( n ) = O ( f ( n ) ) T_1(n)=O(f(n)) T1(n)=O(f(n))和 T 2 ( n ) = O ( g ( n ) ) T_2(n)=O(g(n)) T2(n)=O(g(n)),则 T 1 T 2 = O ( f ( n ) g ( n ) ) T_1 T_2=O(f(n) g(n)) T1T2=O(f(n)g(n))
求和法则:是指若算法的2个部分时间复杂度分别为 T 1 ( n ) = O ( f ( n ) ) T_1(n)=O(f(n)) T1(n)=O(f(n)) 和 T 2 ( n ) = O ( g ( n ) ) T_2(n)=O(g(n)) T2(n)=O(g(n)),则 T 1 ( n ) + T 2 ( n ) = O ( m a x ( f ( n ) , g ( n ) ) ) T_1(n)+T_2(n)=O(max(f(n), g(n))) T1(n)+T2(n)=O(max(f(n),g(n)))
特别地,若 T 1 ( m ) = O ( f ( m ) ) T_1(m)=O(f(m)) T1(m)=O(f(m)), T 2 ( n ) = O ( g ( n ) ) T_2(n)=O(g(n)) T2(n)=O(g(n)),则 T 1 ( m ) + T 2 ( n ) = O ( f ( m ) + g ( n ) ) T_1(m)+T_2(n)=O(f(m)+g(n)) T1(m)+T2(n)=O(f(m)+g(n))
实际演练
- 三个简单语句, T ( n ) = O ( 1 ) T(n)=O(1) T(n)=O(1)。
Temp=i;
i=j;
j=temp;
如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是$O(1)$。
- 因为 O ( n 2 + 1 ) = n 2 O(n^2+1)=n^2 O(n2+1)=n2 ,忽略低阶项, 所以 T ( n ) = O ( n 2 ) T(n)=O(n^2) T(n)=O(n2);
sum=0; (一次)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
sum++; (n^2次)
一般情况下,循环语句只需考虑循环体中语句的执行次数,忽略该语句中步长加1、终值判别、控制转移等成分,当有若干个循环语句嵌套时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。
- 语句①的频度是 n − 1 n-1 n−1,语句②的频度是 ( n − 1 ) ∗ ( 2 n + 1 ) = 2 n 2 − n − 1 (n-1)*(2n+1)=2n^2-n-1 (n−1)∗(2n+1)=2n2−n−1(乘法法则), 所以 f ( n ) = 2 n 2 − n − 1 + ( n − 1 ) = 2 n 2 − 2 f(n)=2n^2-n-1+(n-1)=2n^2-2 f(n)=2n2−n−1+(n−1)=2n2−2(加法法则), 最终 $O(2n2-2)=n2 $ , 即该程序的时间复杂度 T ( n ) = O ( n 2 ) T(n)=O(n^2) T(n)=O(n2)。
for (i=1;i- 语句①的频度:2;语句②的频度一般不考虑;语句③的频度:n-1;语句④的频度:n-1;语句⑤的频度:n-1; T ( n ) = 2 + 3 ( n − 1 ) = 3 n − 1 = O ( n ) T(n)=2+3(n-1)=3n-1=O(n) T(n)=2+3(n−1)=3n−1=O(n)。
a=0; ①
b=1; ①
for (i=1;i<=n;i++) ②
{
s=a+b; ③
b=a; ④
a=s; ⑤
}
- 语句①的频度是1;设语句②的频度是f(n), 则: f ( n ) < = l o g 2 ( n ) f(n)<=log_2(n) f(n)<=log2(n)。取最大值 f ( n ) = l o g 2 ( n ) f(n)=log_2(n) f(n)=log2(n), T ( n ) = O ( l o g ( n ) ) T(n)=O(log_(n)) T(n)=O(log(n))
i=1; ①
while (i<=n)
i=i*2;
- T ( n ) = O ( ( n ) ( n + 1 ) ( n − 1 ) / 6 ) = O ( n 3 ) T(n)=O((n)(n+1)(n-1)/6)=O(n^3) T(n)=O((n)(n+1)(n−1)/6)=O(n3)
for(i=0;i空间复杂度
设计算法的时候,我们还会关注空间复杂度,空间复杂度是算法在运行过程中临时占用的存储空间大小的度量, 同样是关于问题规模n的函数。
但根本上,算法的时间运行效率才是最重要的。只要算法占用的存储空间不要达到计算机无法接受的程度即可。所以,常常通过牺牲空间复杂度来换取算法更加高效的运行时间效率。
算法在计算机存储器上占用的空间包括三个部分。
输入输出
算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不会随算法的不同而改变。这不是我们需要考虑的部分。
算法本身
存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这部分存储空间,就必须编写出较短的算法。然而,算法想要实际应用需要根据需求采取不同的编程语言来实现,不同编程语言实现的代码长短差别很大,然而存储空间都在可接受范围之内(通常不同编程语言的效率更受关注)。
运行临时占用
根据算法在运行过程中临时占用存储空间的不同,可以将算法分为两类。
- 原地算法(in-place algorithm):只需要占用少量的临时工作单元,而且不随问题规模的大小而改变,我们称这种算法是“就地”进行的,是节省存储的算法。
- 非原地算法(not-in-place):需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元。
算法临时占用空间是考虑算法空间复杂度时主要考虑的部分。相比于随着问题输入规模扩大而扩大的非原地算法,原地算法是更加简洁高效的算法(仅考虑空间复杂度时)。
实际例子
假设我们想要将拥有n个项目的数组反过来。一个最简单作这件事的方式是这样:
function reverse(a[0..n])
allocate b[0..n]
for i from 0 to n
b[n - i] = a[i]
return b
不幸地,这样需要 O ( n ) O(n) O(n)的空间来创建b数组,且配置存储器通常是一件缓慢的运算。如果我们不再需要a,我们可使用这个原地算法,用它自己反转的内容来覆盖掉:
function reverse-in-place(a[0..n])
for i from 0 to floor(n/2)
swap(a[i], a[n-i])
排序算法分析
了解算法的时间复杂度和空间复杂度之后,再看一些常用算法总结的时候就不会再向原来一样有雾里探花之感了。

参考文献
算法的时间复杂度和空间复杂度-总结
原地算法
所有Leetcode题目不定期汇总在 Github, 欢迎大家批评指正,讨论交流。