神秘国度的爱情故事 数据结构课设-广州大学
神秘国度的爱情故事
数据结构课设-广州大学
ps:本次课设程序不仅需要解决问题,更需要注重代码和算法的优化和数据测试分析
直接广度优先实现的方法时间复杂度为O(QN),优化后的方法是lca+倍增思想,时间复杂度为O(Qln(N))
是自己写的随机生成树和随机生成询问,输入数据保证准确,进行数据测试分析。
因为在博客中不在方便调整排版,所以在这里给出word文档的下载地址(内容和这次博客的内容完全一致)
此外,还有一个压缩包,包括4个cpp源文件,21组测试样例,以及上面那个完整的word文档,下载地址


三、实验内容
神秘国度的爱情故事(难度系数 1.5)
题目要求:某个太空神秘国度中有很多美丽的小村,从太空中可以想见,小村间有路相连,更精确一点说,任意两村之间有且仅有一条路径。小村 A 中有位年轻人爱上了自己村里的美丽姑娘。每天早晨,姑娘都会去小村 B 里的面包房工作,傍晚 6 点回到家。年轻人终于决定要向姑娘表白,他打算在小村 C 等着姑娘路过的时候把爱慕说出来。问题是,他不能确定小村 C 是否在小村 B 到小村 A 之间的路径上。你可以帮他解决这个问题吗?
输入要求:输入由若干组测试数据组成。每组数据的第 1 行包含一正整数 N ( l 《 N 《 50000 ) , 代表神秘国度中小村的个数,每个小村即从0到 N - l 编号。接下来有 N -1 行输入,每行包含一条双向道路的两个端点小村的编号,中间用空格分开。之后一行包含一正整数 M ( l 《 M 《 500000 ) ,代表着该组测试问题的个数。接下来 M 行,每行给出 A 、 B 、 C 三个小村的编号,中间用空格分开。当 N 为 O 时,表示全部测试结束,不要对该数据做任何处理。
输出要求:对每一组测试给定的 A 、 B 、C,在一行里输出答案,即:如果 C 在 A 和 B 之间的路径上,输出 Yes ,否则输出 No。
思路:在这个课设的题目中,非常巧妙的提出了“任意两村之间有且仅有一条路径”,我们可以想象的到,这是n个结点且刚好有n-1条边的连通图,以任意一个结点为根结点进行广度优先遍历,便会生成一棵树。所以我们处理的方法就是对一棵树的任意两个结点求他们的最近公共祖先(lca)。这里我定义了两个结构体struct Edge和struct Node,Edge为两个结点(村子)之间的相连的边,Node为结点(村子)。Node有两个变量adjnode和next,adjnode为结点向量中的相邻结点,next为指向下一邻接边的指针。Node有村子的编号信息,bfs遍历时的父亲结点,深度信息。用邻接表的方式存储每一个结点与之相连第一条边,然后每插入一个与之相连的边的时候,都会用头插法的方式更新邻接表。通过BFS预处理出这棵树的结点深度和父亲结点的信息。在查询结点a和结点b之间的最近公共祖先的时候,我们可以先把结点深度比较大的结点开始往上一个一个单位的跳,然后跳到和另外一个结点同样的深度的时候停下来,查看这时候它们是否在同一一个结点上了,如果是,那这个结点就是它们的最近公共祖先了,不是的话,我们这次就两个结点一起往它们的父亲结点那里一个一个单位的跳,直到第一次跳到相同的结点的地方,这时,该结点便是它们的最近公共祖先。通过课设的题目我们可以知道,任意两个结点之间必定存在且只有一条路径互达,所以这样处理的方法必定可以找到这两个结点的最近公共祖先。那么如何解决C点是否在A和B的路径上呢?我们可以先找出
A和B的最近公共祖先为D,A和C的最近公共祖先为AC,B和C的最近公共祖先为BC。如果AC==C并且BC==C,则说明C同时是A和B的最近公共祖先,这里需要分情况讨论,如果C==D的话,则说明C就是A和B的最近公共祖先,如果C!=D,则说明C不是A和B的最近公共祖先,则A到D再走到B的路径中,不会经过C结点。如果只有AC==C或者BC==C,则说明C是A或者B中一个且只有一个结点的祖先结点。如果C是A的祖先结点,不是B的祖先结点,则说明C在A和D的路径上,则C肯定是在A和B的路径上。如果C是B的祖先结点,不是A的祖先结点,则说明C在B和D的路径上,则C肯定是在A和B的路径上。如果C不是A和B中任意一个结点的祖先结点,那么从A到B的路径上不会经过C结点。
以下是未优化过的程序的:
时间复杂度为O(QN),其中,Q为询问次数,N为结点(村子)的数量。(byd001.cpp)
#include
#include
#include
using namespace std;
const int maxn = 50010;
const int DEG = 20;
int edgenum, nodenum;
struct Edge { //边的邻接点
int adjnode; //邻接点在结点向量中的下表
Edge *next; //指向下一邻接边的指针
};
struct Node { //结点结点(村子)
int id; //结点信息(村子编号)
int fa; //结点的父亲结点
int depth; //结点的深度
Edge *firstarc; //指向第一个邻接边的指针
};
void creatgraph(Node* node, int n) { //创建一个村落图
Edge *p;
int u, v;
nodenum = n; //结点(村庄)的个数
edgenum = n - 1; //边数是结点数-1
for (int i = 0; i> u >> v;
p = new Edge; //下面完成邻接表的建立
p->adjnode = v;
p->next = node[u].firstarc;
node[u].firstarc = p; //类似于头插法
p = new Edge;
p->adjnode = u;
p->next = node[v].firstarc;
node[v].firstarc = p; //路径是双向的
}
}
void BFS(Node* &node, int root) { //bfs广度优先遍历,预处理出每一个结点的深度和父亲结点
queueque; //队列
node[root].depth = 0; //树的根结点的深度为0
node[root].fa = root; //树的根结点的父亲结点为他自己
que.push(root); //根结点入队
while (!que.empty()) {
int u = que.front(); //将队列的头结点u出队
que.pop();
Edge* p;
for (p = node[u].firstarc; p != NULL; p = p->next) { //找出和u相连的边
int v = p->adjnode; //v为对应邻接边的邻接结点
if (v == node[u].fa) continue; //因为存储的是双向边,所以防止再访问到已经访问过的父亲结点
node[v].depth = node[u].depth + 1; //结点的深度为父亲结点的深度+1
node[v].fa = u; //记录v结点的父亲结点为u
que.push(v); //v结点入队
}
}
}
int LCA(Node* node, int u, int v) { //在树node中,找出结点u和结点v的最近公共祖先
if (node[u].depth > node[v].depth)swap(u, v); //u为深度较小的结点,v为深度较大的结点
int hu = node[u].depth, hv = node[v].depth;
int tu = u, tv = v;
for (int det = hv - hu, i = 1; i <= det; i++) //两个结点的深度差为det,结点v先往上跑det个长度,使得这两个结点在同一深度
tv = node[tv].fa;
if (tu == tv)return tu; //如果他们在同一深度的时候,在同一结点了,那么这个结点就是这两个结点的最近公共祖先
while (tu != tv) { //他们不在同一结点,却在同一深度了,那就两个结点一起往上跳一个单位
tu = node[tu].fa; //直到跳到同一个结点,那这个结点就是它们的最近公共祖先
tv = node[tv].fa;
}
return tu; //返回最近公共祖先
}
void solve(Node* node, int a, int b, int c) { //在树node中,查询结点c是否在a和b的路径上
int d = LCA(node, a, b); //找出a和b结点的最近公共祖先为d
int ac = LCA(node, a, c); //找出a和c结点的最近公共祖先为ac
int bc = LCA(node, b, c); //找出b和c结点的最近公共祖先为bc
//cout<> T; //输入测试样例数T
while (T--) {
cin >> n; //输入结点数n
Node *node = new Node[n + 1]; //动态申请n+1个结点空间
creatgraph(node, n); //建树
BFS(node, 0); //bfs预处理出树结点的深度和对应的父亲结点
cin >> m; //输入m个询问
while (m--) {
cin >> a >> b >> c; //输入结点编号a,b和c
solve(node, a, b, c); //询问c结点是否在a和b结点的路径上
}
delete node; //这组测试样例处理结束,撤销申请的空间
}
return 0;
}
未优化过的程序,在查找最近公共祖先的时候是一个一个往上面查找的,所以在最坏的情况下,时间复杂度会退化到O(QN),比如说在树退化成单链表的时候就会时间复杂度就会很高。优化的策略是按照倍增思想进行向上查找,比如说,一个结点需要跳到它的第7个祖先结点那里,一次一次的往上跳跃需要7次(如图001所示),如果把7转换成二进制111,那就是需要往上跳跃三次,第一次跳跃4个单位,第二次跳跃2个单位,第三次跳跃1个单位就可以跳跃到第7个祖先结点那里(如图002所示)。

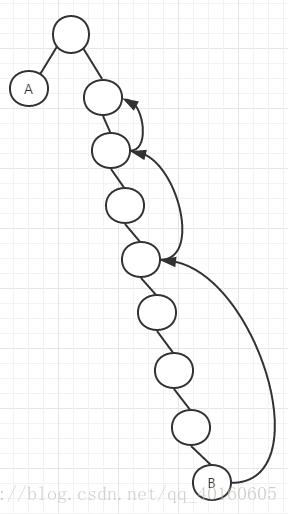
图001 图002
一开始两个结点不处于相同的深度的时候,先让深度较大的用这种方法进行往上的跳跃,使其结点达到相同的深度。然后开始不断从大的二进制那里进行试探跳跃,比如说,A现在和B在同一深度了,A和B先试探的跳跃到2^2个父亲结点处(如图003所示),此时他们跳到相同的结点地方了,这个结点就是他们的公共祖先,但不清楚是不是最近公共祖先,所以我们舍弃这一次跳跃,试探跳跃到它们对应第2^1个父亲结点(如图004所示),发现这是它们的结点不一样,说明它们距离最近的公共祖先又近了一步,下一步就是跳跃到它们对应的第2^0个结点处(如图005所示),这时i==0,这是循环结束,它们已经跳跃到最接近公共祖先的地方了(如图006所示)(即此时的父亲结点就是最近公共祖先),这时就是它们的最近公共祖先了,成功在log(n)的时间内找到A和B的最近公共祖先,优化了查询速度。

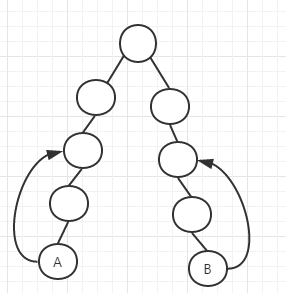
图003 图004

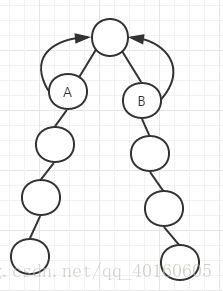
图005 图006
以下为优化查询最近公共祖先的方式后的代码:
(时间复杂度为O(Qlog(N)),其中Q为查询的次数,N为树的结点的个数)
(byd004.cpp)
#include
#include
#include
#include
using namespace std;
const int maxn = 50010;
const int DEG = 20;
int edgenum, nodenum;
struct Edge { //边的邻接点
int adjnode; //邻接点在结点向量中的下表
Edge *next; //指向下一邻接点的指针
};
struct Node { //结点(村子)
int id; //结点信息(村子编号)
int fa[20]; //结点的父亲结点,fa[i]表示的是该结点的第2^i个父亲结点
int depth; //结点的深度
Edge *firstarc; //指向第一邻接点的指针
};
void creatgraph(Node* node, int n) { //创建一个村落图
Edge *p;
int u, v;
nodenum = n; //结点(村庄)的个数
edgenum = n - 1; //边数是结点数-1
for (int i = 0; i> u >> v;
p = new Edge; //下面完成邻接表的建立
p->adjnode = v;
p->next = node[u].firstarc;
node[u].firstarc = p; //类似于头插法
p = new Edge;
p->adjnode = u;
p->next = node[v].firstarc;
node[v].firstarc = p; //路径是双向的
}
}
void BFS(Node* &node, int root) { //bfs广度优先遍历,预处理出每一个结点的深度和和对应的第2^i个父亲结点
queueque; //队列
node[root].depth = 0; //树的根结点的深度为0
node[root].fa[0] = root; //树的根结点的第2^0(第一)个父亲结点为他自己
que.push(root); //根结点入队
while (!que.empty()) {
int u = que.front(); //将队列的头结点u出队
que.pop();
for (int i = 1; i < DEG; i++) //u的第2^i个父亲结点等于u的第2^(i-1)个父亲结点的第2^(i-1)个父亲结点
node[u].fa[i] = node[node[u].fa[i - 1]].fa[i - 1];
Edge* p;
for (p = node[u].firstarc; p != NULL; p = p->next) { //找出和u相连的边
int v = p->adjnode; //v为对应邻接边的邻接结点
if (v == node[u].fa[0]) continue; //因为存储的是双向边,所以防止再访问到已经访问过的父亲结点
node[v].depth = node[u].depth + 1; //结点的深度为父亲结点的深度+1
node[v].fa[0] = u; //记录v结点的父亲结点为u
que.push(v); //v结点入队
}
}
}
int LCA(Node* node, int u, int v) { //在树node中,找出结点u和结点v的最近公共祖先
if (node[u].depth > node[v].depth)swap(u, v); //u为深度较小的结点,v为深度较大的结点
int hu = node[u].depth, hv = node[v].depth;
int tu = u, tv = v;
for (int det = hv - hu, i = 0; det; det >>= 1, i++) //两个结点的深度差为det,结点v先往上跑det个长度,使得这两个结点在同一深度
if (det & 1) //将深度差拆分成二进制进行结点的2^i跳跃,优化了之前的一个一个跳跃的方法
tv = node[tv].fa[i];
if (tu == tv)return tu; //如果他们在同一深度的时候,在同一结点了,那么这个结点就是这两个结点的最近公共祖先
for (int i = DEG - 1; i >= 0; i--) { //他们不在同一结点,却在同一深度了,那就两个结点一起往上跳2^i单位
if (node[tu].fa[i] == node[tv].fa[i]) //如果会跳过头了,则跳过这一步跳跃
continue;
tu = node[tu].fa[i];
tv = node[tv].fa[i];
}
return node[tu].fa[0]; //循环结束后,这两个结点在同一深度,并且差一个单位就会跳跃到同一个结点上,
} //则它们结点的第一个父亲结点就是它们的最近公共祖先
void solve(Node* node, int a, int b, int c) { //在树node中,查询结点c是否在a和b的路径上
int d = LCA(node, a, b); //找出a和b结点的最近公共祖先为d
int ac = LCA(node, a, c); //找出a和c结点的最近公共祖先为ac
int bc = LCA(node, b, c); //找出b和c结点的最近公共祖先为bc
bool flag = false;
if (ac == c&&bc == c) { //如果ac==c并且bc==c,说明c结点是a和b结点的公共祖先
if (c == d) { //如果c==d,说明c就是a和b的最近公共祖先,c必定在a和b的路径上
flag = true;
}
else
flag = false; //如果c!=d,说明c不是a和b的最近公共祖先,a和b的路径上不包括c
}
else if (ac == c || bc == c) { //c是a的祖先或者是b的祖先,说明c在a到d的路径上或者在b到d的路径上
flag = true; //此时c一定是a和b路径上的点
}
else {
flag = false; //如果c不是a的祖先,也不是b的祖先,则a和b的路径上不会经过c点
}
if (flag)
cout << "村子" << c << "在村子" << a << "和村子" << b << "的路径上" << endl;
else
cout << "村子" << c << "不在村子" << a << "和村子" << b << "的路径上" << endl;
}
int main() {
//DWORD start_time = GetTickCount();
int n, m; //一组测试样例包括n个村子,n-1个村子之间的关系,m组询问
int a, b, c; //每组询问包括三个结点编号a,b和c,意思为询问c结点是否在a和b结点的路径上
cin >> n; //输入结点数n
Node *node = new Node[n + 1]; //动态申请n+1个结点空间
creatgraph(node, n); //建树
BFS(node, 0); //bfs预处理出树结点的深度和对应的父亲结点
cin >> m; //输入m个询问
while (m--) {
cin >> a >> b >> c; //输入结点编号a,b和c
solve(node, a, b, c); //询问c结点是否在a和b结点的路径上
}
delete node; //这组测试样例处理结束,撤销申请的空间
//DWORD end_time = GetTickCount();
//cout << "该组测试样例的用时为:" << (end_time - start_time) << "ms!" << endl;
return 0;
}
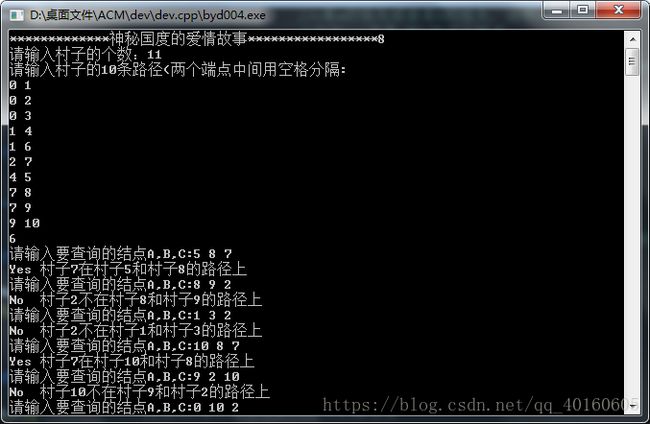
|
11
0 1
0 2
0 3
1 4
1 6
2 7
4 5
7 8
7 9
9 10
6
5 8 7
8 9 2
1 3 2
10 8 7
9 2 10
0 10 2

程序运行的结果为:
四,程序验证
优化后的程序是否真的比未优化的程序优秀呢?
1.我们先随机生成一颗N个结点的树和Q次询问,保证生成的树是合法的和询问是合法的。
思路是:先生成一个随机乱序的0~N-1组成的数组放入队列q中,队列q存储的是为匹配的结点,队列que存储的是已经即将要匹配的结点。比如说,随机生成一个乱序数组为5,3,2,4,1,0。队列q中5先出列放入却中。1.Que取出队首元素u,然后随机生成一个tmp表示u有tmp个分支结点,然后取队列中tmp个数,队列中的前tmp个数再取出来放入que中,回到1继续执行,直到q的队列为空,则生成一颗随机树成立。(byd003.cpp)
#include
#include
#include
#include
#include
using namespace std;
#define ll long long
const int maxn = 250000 + 10;
const int inf = int(1e9) + 7;
const int mod = 1000000007;
int top = 1;
queueq;
queueque;
void init(int n) { //随机生成0~n-1的乱序数组,存入队列q中
while (!q.empty())
q.pop();
int num[maxn];
for (int i = 0; i> T >> n; //生成具有T组测试样例,每组测试样例有n个结点的树
cout << T << endl;
top = 0;
for (int i = 1; i <= T; i++) {
top++; //全局变量top不断变化,和时间种子相结合,保证每一组随机生成的数据都不一样
init(n); //随机生成0~n-1的乱序数组,存入队列q中
greattree(n); //随机生成n个结点的树,和n-1条边的结点之间的关系
greatequery(n); //随机生成tmp组查询数据,保证a!=b,b!=c,a!=c
}
return 0;
}
这样我们就可以随机生成树和查询数据来测试程序的运行效率了。
这里生成21个随机数据测试文件txt如下所示:(测试文件txt也放在压缩包下的测试数据文件中)
Ps:每个文件下都是十组测试数据
以下为n个树结点500个查询(查询数先固定)
测试文件test_in1_0.txt (结点数:10)
测试文件test_in1_1.txt (结点数:20)
测试文件test_in1_2.txt (结点数:50)
测试文件test_in1_3.txt (结点数:100)
测试文件test_in1_4.txt (结点数:500)
测试文件test_in1_5.txt (结点数:1000)
测试文件test_in1_6.txt (结点数:2000)
测试文件test_in1_7.txt (结点数:5000)
测试文件test_in1_8.txt (结点数:10000)
测试文件test_in1_9.txt (结点数:50000)
以下为50000个树结点Q个查询(结点数先固定)
测试文件test_in2_0.txt (查询数:10)
测试文件test_in2_1.txt (查询数:50)
测试文件test_in2_2.txt (查询数:100)
测试文件test_in2_3.txt (查询数:500)
测试文件test_in2_4.txt (查询数:1000)
测试文件test_in2_5.txt (查询数:5000)
测试文件test_in2_6.txt (查询数:10000)
测试文件test_in2_7.txt (查询数:50000)
测试文件test_in2_8.txt (查询数:100000)
测试文件test_in2_9.txt (查询数:250000)
一组特殊的测试样例 test_in0(10组测试样例,每一组测试样例有50000,个结点,10000个询问,生成的树退化成单链表的情况下测试程序的运行时间)
优化后的能读写txt文件的程序如下所示(byd002.cpp)
#include
#include
#include
using namespace std;
const int maxn = 50010;
const int DEG = 20;
int edgenum, nodenum;
struct Edge { //边的邻接点
int adjnode; //邻接点在结点向量中的下表
Edge *next; //指向下一邻接点的指针
};
struct Node { //结点(村子)
int id; //结点信息(村子编号)
int fa[20]; //结点的父亲结点,fa[i]表示的是该结点的第2^i个父亲结点
int depth; //结点的深度
Edge *firstarc; //指向第一邻接点的指针
};
void creatgraph(Node* node, int n) { //创建一个村落图
Edge *p;
int u, v;
nodenum = n; //结点(村庄)的个数
edgenum = n - 1; //边数是结点数-1
for (int i = 0; i> u >> v;
p = new Edge; //下面完成邻接表的建立
p->adjnode = v;
p->next = node[u].firstarc;
node[u].firstarc = p; //类似于头插法
p = new Edge;
p->adjnode = u;
p->next = node[v].firstarc;
node[v].firstarc = p; //路径是双向的
}
}
void BFS(Node* &node, int root) { //bfs广度优先遍历,预处理出每一个结点的深度和和对应的第2^i个父亲结点
queueque; //队列
node[root].depth = 0; //树的根结点的深度为0
node[root].fa[0] = root; //树的根结点的第2^0(第一)个父亲结点为他自己
que.push(root); //根结点入队
while (!que.empty()) {
int u = que.front(); //将队列的头结点u出队
que.pop();
for (int i = 1; i < DEG; i++) //u的第2^i个父亲结点等于u的第2^(i-1)个父亲结点的第2^(i-1)个父亲结点
node[u].fa[i] = node[node[u].fa[i - 1]].fa[i - 1];
Edge* p;
for (p = node[u].firstarc; p != NULL; p = p->next) { //找出和u相连的边
int v = p->adjnode; //v为对应邻接边的邻接结点
if (v == node[u].fa[0]) continue; //因为存储的是双向边,所以防止再访问到已经访问过的父亲结点
node[v].depth = node[u].depth + 1; //结点的深度为父亲结点的深度+1
node[v].fa[0] = u; //记录v结点的父亲结点为u
que.push(v); //v结点入队
}
}
}
int LCA(Node* node, int u, int v) { //在树node中,找出结点u和结点v的最近公共祖先
if (node[u].depth > node[v].depth)swap(u, v); //u为深度较小的结点,v为深度较大的结点
int hu = node[u].depth, hv = node[v].depth;
int tu = u, tv = v;
for (int det = hv - hu, i = 0; det; det >>= 1, i++) //两个结点的深度差为det,结点v先往上跑det个长度,使得这两个结点在同一深度
if (det & 1) //将深度差拆分成二进制进行结点的2^i跳跃,优化了之前的一个一个跳跃的方法
tv = node[tv].fa[i];
if (tu == tv)return tu; //如果他们在同一深度的时候,在同一结点了,那么这个结点就是这两个结点的最近公共祖先
for (int i = DEG - 1; i >= 0; i--) { //他们不在同一结点,却在同一深度了,那就两个结点一起往上跳2^i单位
if (node[tu].fa[i] == node[tv].fa[i]) //如果会跳过头了,则跳过这一步跳跃
continue;
tu = node[tu].fa[i];
tv = node[tv].fa[i];
}
return node[tu].fa[0]; //循环结束后,这两个结点在同一深度,并且差一个单位就会跳跃到同一个结点上,
} //则它们结点的第一个父亲结点就是它们的最近公共祖先
void solve(Node* node, int a, int b, int c) { //在树node中,查询结点c是否在a和b的路径上
int d = LCA(node, a, b); //找出a和b结点的最近公共祖先为d
int ac = LCA(node, a, c); //找出a和c结点的最近公共祖先为ac
int bc = LCA(node, b, c); //找出b和c结点的最近公共祖先为bc
//cout<> T; //输入测试样例数T
while (T--) {
cin >> n; //输入结点数n
Node *node = new Node[n + 1]; //动态申请n+1个结点空间
creatgraph(node, n); //建树
BFS(node, 0); //bfs预处理出树结点的深度和对应的父亲结点
cin >> m; //输入m个询问
while (m--) {
cin >> a >> b >> c; //输入结点编号a,b和c
solve(node, a, b, c); //询问c结点是否在a和b结点的路径上
}
delete node; //这组测试样例处理结束,撤销申请的空间
}
return 0;
}
2.测试固定查询数,测试结点数对程序运行的影响:
0.测试文件test_in1_0.txt (结点数:10)

运行10个结点,500个查询的测试样例平均时间为0.008538s(上面的程序测试的是10组数据,下面的测试也是一样)
1. 测试文件test_in1_1.txt (结点数:20)

运行20个结点,500个查询的测试样例平均时间为0.009514s
2.测试文件test_in1_2.txt ( 结点数:50)

运行50个结点,500个查询的测试样例平均时间为0.01134s
3.测试文件test_in1_3.txt (结点数:100)

运行100个结点,500个查询的测试样例平均时间为0.0131s
4. 测试文件test_in1_4.txt (结点数:500)

运行500个结点,500个查询的测试样例平均时间为0.01524s
5.测试文件test_in1_5.txt (结点数:1000)

运行1000个结点,500个查询的测试样例平均时间为0.01829s
6.测试文件test_in1_6.txt (结点数:2000)

运行2000个结点,500个查询的测试样例平均时间为0.02163s
7. 测试文件test_in1_7.txt (结点数:5000)

运行5000个结点,500个查询的测试样例平均时间为0.03852s
8. 测试文件test_in1_8.txt (结点数:10000)

运行10000个结点,500个查询的测试样例平均时间为0.05924s
9.测试文件test_in1_9.txt (结点数:50000)

运行50000个结点,500个查询的测试样例平均时间为0.2699s
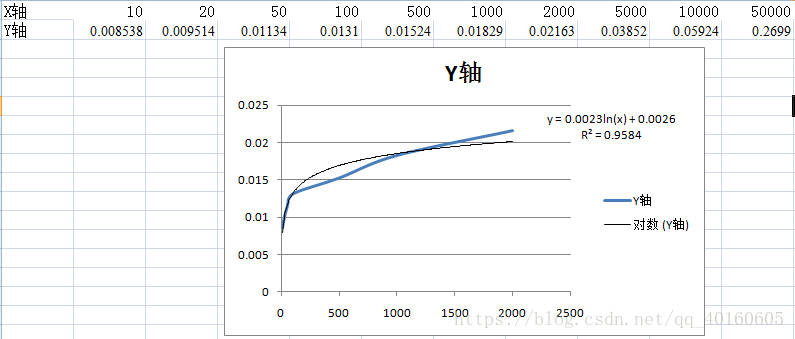
在500个询问下,在10~2000个结点组成的树,时间复杂度基本符合O(Qln(N)),其中,Q为询问的次数,在这次验证中Q为常数500,N为树结点的个数。但是在5000,10000,50000个点的时候,就不在符合这条曲线了,有点接近O(QN)的,思考了一下,觉得是输入和输出的数据量过大,在不断的读写文件的过程中,消耗的时间与程序算法求出结果的时间相比起来,在读写文件消耗的时间更起决定性作用,所以在后续的运行中,程序运行的时间与读写数据的容量大小成线性关系。(如下图所示)
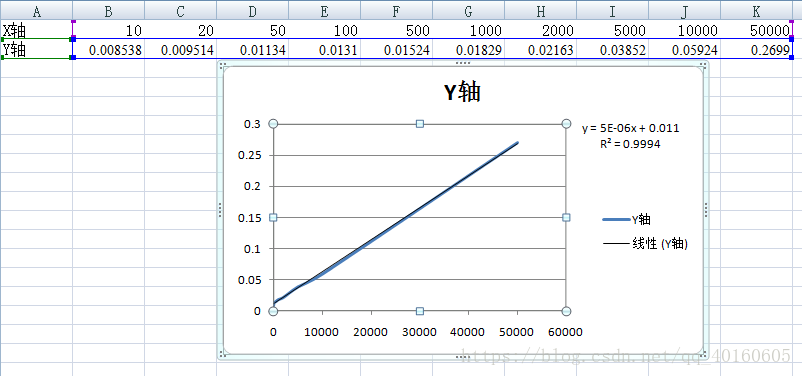
3.测试固定结点数为50000,查询数对程序运行的影响:
0. 测试文件test_in2_0.txt (查询数:10)

运行50000个结点,10个查询的测试样例平均时间为0.2539s(上面的程序测试的是10组数据,下面的测试也是一样)
1.测试文件test_in2_1.txt (查询数:50)
运行50000个结点,50个查询的测试样例平均时间为0.2553s
2.测试文件test_in2_2.txt (查询数:100)

运行50000个结点,100个查询的测试样例平均时间为0.2598s
3.测试文件test_in2_3.txt (查询数:500)
运行50000个结点,500个查询的测试样例平均时间为0.2685s
4.测试文件test_in2_4.txt (查询数:1000)

运行50000个结点,1000个查询的测试样例平均时间为0.286s
5.测试文件test_in2_5.txt (查询数:5000)
运行50000个结点,5000个查询的测试样例平均时间为0.3113s
6.测试文件test_in2_6.txt (查询数:10000)

运行50000个结点,10000个查询的测试样例平均时间为0.365s
7.测试文件test_in2_7.txt (查询数:50000)

运行50000个结点,50000个查询的测试样例平均时间为0.7855s
8.测试文件test_in2_8.txt (查询数:100000)

运行50000个结点,100000个查询的测试样例平均时间为1.306s
9.测试文件test_in2_9.txt (查询数:250000)

运行50000个结点,250000个查询的测试样例平均时间为2.977s
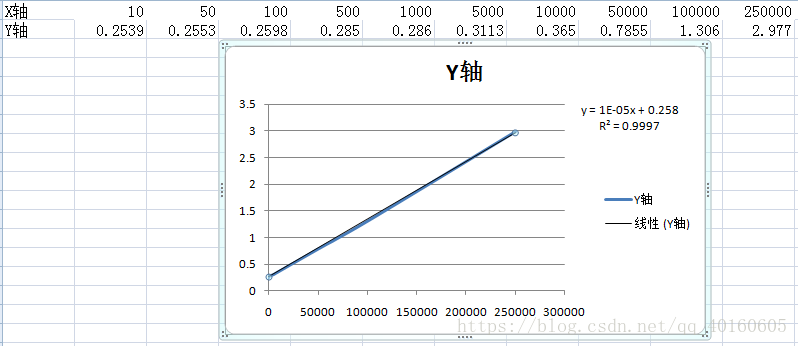
在50000个结点组成的树,询问次数为10~250000次的时间复杂度基本符合O(Qln(N)),其中,Q为询问的次数,N为树结点的个数,在这次验证中,N为常数50000。虽然符合推出来的时间复杂度,但是后面的数据也有可能是收到了大量查询数据的读入和写出的的影响,从而趋近于和查询次数Q成线性关系的。
另外,影响程序运行速度的,除了程序的算法外,还有电脑的并行运行,其他的软件在后台运行占用CPU,影响该程序的测试时间,其他还有在读取txt的内容和写入txt内容的消耗时间等等的其他因素的影响。
4.用普通的广度优先方法和这次实验优化后的程序跑这一组特殊的测试样例
测试样例 test_in0(10组测试样例,每一组测试样例有50000,个结点,10000个询问,生成的树退化成单链表)
未优化的广度优先在处理变成退化成单链表的时候,运行效率大幅降低
运行所花的时间为56.48s
本次实验中写到的优化程序在处理变成退化成单链表的时候,运行效率还是非常优秀,运行所花的时间为3.692s

五.存在的问题及体会
在本次实验报告中,选择了第三个课题“神秘国度的爱情故事”。
在一开始选择实现的算法的时候,我主要考虑了能够高效和快速的解决问题的算法LCA+ST的算法,这个算法可以在预处理一遍N个结点后,很稳定的在O(ln(N))的时间复杂度找出任意两个结点之间的最近公共祖先,然后通过AB,AC,BC之间的最近公共祖先的关系可以判断C是否在A和B结点的路径上的问题。通过和老师的沟通和交流,我也明白了,这个作为课程设计的题目,不仅仅是解决课设中的问题,还要考虑到各种优化的策略,程序的时间和空间复杂度,程序的可读性,程序的鲁棒性,程序运行时的真实时间,它随问题规模的增大会有什么变化。我原本的做法是基于dfs深度优先搜索的,在深度优先的过程中,50000个结点还是可以存储在堆栈中的,但是500000个结点的话,程序就会提示栈溢出的问题了,所以我原本的LCA+ST的做法在处理更大的问题规模的时候可能就会出错了。另外,老师提到的在bfs遍历的时候可以之间入队和出队操作,比dfs的回溯更能节省时间和空间,因此,在和老师的指导下,我选择了广度优先生成树来处理本次课设的问题。
在用广度优先遍历生成一棵树后,可以很容易的就想到的一种做法是,A结点和B结点一个一个的不断往它们对应的父亲结点跳跃,当它们之间有一个结点跳跃到C结点的时候,说明C点在A和B结点之间,此时成功找到答案,结束这次查询。如果它们先跳到它们已经跳跃过的结点上的话(即B可能跳到A已经跳过的结点上,或者A跳到已经跳过的结点上),那么该结点就是它们的最近公共祖先,此时还没找到C结点,则说明C结点不在它们的路径上。这样问题也能的到完美的解决。我们用随机生成的树和询问来测试这个程序,可以发现,在生成的树在完全随机的情况下,树都是长的非常均匀的,这样,这个算法在一次询问中找到答案的平均时间复杂度为O(k),其中k为树的层数。这个算法非常简单易懂,而且效率也非常优秀,但是却有一个严重的缺陷,就是在处理极端情况下(比如说一颗树退化成一个链表的时候),树的层数会变的非常大,导致结点在一个个跳跃的时候,会浪费大量的时间,导致程序时间复杂度退化到O(N),N为结点的个数。
结点一个一个往上跳跃会浪费大量的时间,那么我们可以优化一下跳跃的方式。这里我使用了二进制的跳跃方式,每一次跳跃都是2^i个单位。我把查询C在A和B的路径上步骤分成两部分进行。第一部分是解决给定两个结点u和v,求出u和v的最近公共祖先(lca),这一步的时间复杂度为O(ln(n)),第二部分就是求出A和B,A和C,B和C的最近公共祖先,通过对比它们之间的关系,即可得知C点是否在A和B点的路径上(这部分在以上的实验内容的思路分析上有画图讲解和简单证明),这样子处理数据的话,就可以在极端数据的保持程序的高效性,在实验验证的第三个验证可以看出优化和没有优化的程序在处理极端数据之间的区别。
以上便是我在本次课设遇到的问题,以及解决问题思路的变化过程。通过这次课程设计实验,我对树的广度优先遍历,树的邻接表存储方式有了更深刻的了解。通过对课设题目的分析,想出算法,写出程序,再进一步优化,来解决问题,要考虑很多的问题,比如说,程序的时间和空间复杂度,程序的可读性,程序的鲁棒性,程序运行时的真实时间,它随问题规模之间的关系,优化的策略,优化后的真正效果是怎么样的。尤其是在自己编写一个随机生成随机树和随机查询数据的时候,这都是对自己能力的一个巨大考验。对于一个随机生成的合法的数据,通过对拍优化和未优化的程序生成的结果,可以得出程序正确的结果。对于不同规模的数据问题,我们可以对比它们在优化程序下的运行速度。在这里有一个一直困扰我的问题是,在树结点的问题规模在5000内情况下,程序的时间复杂度基本为O(Qln(N)),其中,Q为询问的次数,N为结点的个数。但是在结点数不断的增大的时候,它们之间的关系不在是对数关系,而是趋近于线性关系。我思考了不少可能情况,最有可能的是,在树结点太多的时候,程序读写txt中大量的测试数据所消耗的时间占程序运行所画的时间的比例在不断的增大,最终读取txt文件的时间更占主导地位。我尝试只处理问题,而不输出结果的方式跑一边50000个结点的数据,程序运行时间确实少了一些,当时,需要处理的输入数据还是很大,而且没有输出的程序也没有任何意义,所以这里就没有比较好的解决方法,可以只测试程序解决问题的时间,而不考虑程序的读写txt文件的时间。另外,需要注意一下的是,程序运行的时候要读取txt文件的话,需要注意文件下的路径需要填写正确。最后,这份课设能够使用优化的策略进行各个方面的分析,解决问题,还要感谢老师对我的耐心指导。