cnn-过拟合(over-fitting)
概念
为了得到一致假设而使假设变得过度严格称为过拟合[1]
给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。
过拟合的示意图:

在上图中训练样本存在噪声,为了照顾它们,分类曲线的形状非常复杂,导致在真实测试时会产生错分类.
直白理解:在神经网络中,首先根据训练数据集进行训练,训练结果的好坏,通过一个损失函数的对预测值和实际真实值进行判断,当预测值和真实值对比,损失最小时,即拟合的很好,则训练的结果OK,如上图,蓝色的分类和红色的分类,通过复杂的曲线,完全在训练集上分类准确。其实用这个曲线去分类或预测实际(测试)数据集时,则会出现不准确的现象,则这种情况就是过拟合。如下图:

上图a,在训练集上,中间的虚线,已完全分开了小圆点和三角形,但是在测试集上(上图b),虚线还是把原点分类到了三角形这边。
表1 过拟合与欠拟合的判断标准

过拟合原因
(1)建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
(2)样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
(4)参数太多,模型复杂度过高;
(5)对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
(6)对于神经网络模型:a)对样本数据可能存在分类决策面不唯一,随着学习的进行,,BP算法使权值可能收敛过于复杂的决策面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
解决办法
(1) 在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则
理论及数学原理
方差与偏差
模型的泛化误差来自于两部分,分别称为偏差和方差。
偏差又称为表观误差,是指个别测定值与测定的平均值之差,它可以用来衡量测定结果的精密度高低。在统计学中,偏差可以用于两个不同的概念,即有偏采样与有偏估计。一个有偏采样是对总样本集非平等采样,而一个有偏估计则是指高估或低估要估计的量。方差在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
偏差(bias)是模型本身导致的误差,偏差描述的是根据样本拟合出的模型输出结果与真实结果的差距,损失函数就是依据模型偏差的大小进行反向传播的。降低偏差,就需要复杂化模型,增加模型参数,但容易造成过拟合。
假设样本特征向量为x,标签值为y,要拟合的目标函数为h(x),模型训练出来的函数为h(x),则偏差为:

根据上面的定义,高偏差意味着模型本身的输出值与期望值差距很大,因此会导致欠拟合问题。方差(variance)是由于对训练样本集的小波动敏感而导致的误差。它可以理解为模型预测值的变化范围,即模型预测值的波动程度。
方差描述的是样本上训练出的模型在测试集上的表现,降低方差,继续要简化模型,减少模型的参数,但容易造成欠拟合。根本原因是,我们总是希望用有限的训练样本去估计无限的真实数据。假定我们可以获得所有可能的数据集合,并在这个数据集上将损失函数最小化,则这样的模型称之为“真实模型”。根据概率论中方差的定义,有:

根据定义,高方差意味着算法对训练样本集中的随机噪声进行建模,从而出现过拟合问题。
模型的总体误差可以分解为偏差的平方与方差之和:

这称为偏差-方差 分解公式。如果模型过于简单,一般会有大的偏差和小的方差;反之如果模型复杂则会有大的方差但偏差很小。这是一对矛盾,因此我们需要在偏置和方差之间做一个折中。如果我一模型的复杂度作为横坐标,把方差和偏差的值作为纵坐标,可以得到下图所示的两条曲线。

下面以一个简单的例子来形象的解释偏差和方差的概念。在打靶时,子弹飞出枪管之后以曲线轨迹飞行
如果不考虑空气的阻力,这是一条标准的抛物线,如果考虑空气阻力,是一条更复杂的曲线。

我们用弹道曲线作为预测模型,在给定子弹初速度的前提下,如果知道靶心与枪口的距离,可以通过调整枪口的仰角来让子弹命中靶心。
如果使用抛物线函数就会产生偏差,因为理论上子弹的落点不会在靶心而是在靶心偏下的位置,此时需要更换弹道曲线模型。
无论选用哪种弹道曲线模型,受风速、枪口震动等因素的影响,即使瞄准的是靶心,子弹还是会随机散布在靶心周围,这就是方差
正则化
有监督机器学习算法训练的目标是最小化误差函数。以均方误差损失函数为例,它是预测值与样本真实值的误差平方和:

其中 ![]() 是样本的标签值,
是样本的标签值, ![]() 是预测函数的输出值,
是预测函数的输出值, ![]() 是模型的参数。在预测函数的类型选定之后,我们能控制的就是函数的参数。为了防止过拟合,可以为损失函数加上一个惩罚项对复杂的模型进行惩罚,即强制让模型的参数值尽可能小,加入惩罚项之后损失函数为:
是模型的参数。在预测函数的类型选定之后,我们能控制的就是函数的参数。为了防止过拟合,可以为损失函数加上一个惩罚项对复杂的模型进行惩罚,即强制让模型的参数值尽可能小,加入惩罚项之后损失函数为:

函数的后半部分称为正则化项,这里的目标是让它的值尽可能小,即参数等于0或者接近于0。 ![]() 为惩罚项系数,是人工设定的大于0的参数。正则化项可以使用L2范数即平方和,也可以使用其他范数如L1范数,即绝对值之和。L2范数在求解最优化问题时计算简单,而且有更好的数学性质,二次函数的导数为:
为惩罚项系数,是人工设定的大于0的参数。正则化项可以使用L2范数即平方和,也可以使用其他范数如L1范数,即绝对值之和。L2范数在求解最优化问题时计算简单,而且有更好的数学性质,二次函数的导数为:
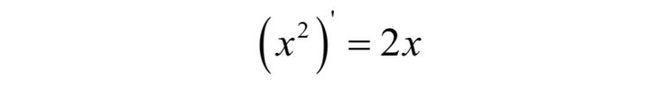
绝对值函数在0点不可导,如果不考虑这种情况,其导数为符号函数 ![]() 。与L2相比L1正则化能更有效的让参数趋向于0,产生的结果更稀疏。
。与L2相比L1正则化能更有效的让参数趋向于0,产生的结果更稀疏。
剪枝
剪枝是决策树类算法防止过拟合的方法。如果决策树的结构过于复杂,可能会导致过拟合问题,此时需要对树进行剪枝,消掉某些节点让它变得更简单。剪枝的关键问题是确定减掉哪些树节点以及减掉它们之后如何进行节点合并。决策树的剪枝算法可以分为两类,分别称为预剪枝和后剪枝。前者在树的训练过程中通过停止分裂对树的规模进行限制;后者先构造出一棵完整的树,然后通过某种规则消除掉部分节点,用叶子节点替代。
数据增广
数据增广是解决过拟合中思想比较朴素的方法。训练集越多,过拟合的概率越小,数据增广是一个比较方便有效屡试不爽的方法,但各类领域的增广方法都不同。
- 在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等。
- 在自然语言处理领域中,可以做同义词替换扩充数据集。
- 语音识别中可以对样本数据添加随机的噪声。
Dropout
Dropout是神经网络中防止过拟合的方法。dropout的做法是在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。dropout机制使得每个神经元在训练时只用了样本集中的部分样本,这相当于对样本集进行采样,即bagging的做法。最终得到的是多个神经网络的组合。
Early Stopping
提前停止的策略是在验证集误差出现增大之后,提前结束训练;而不是一直等待验证集 误差达到最小。提前停止策略十分简单,执行效率高,但需要额外的空间备份参数。