Transformer 模型
Transformer 模型
- 论文:Attention Is All You Need
- 代码:Tensor2Tensor 哈佛 Pytorch Transformer 代码 torch.nn.Transformer
Transformer 模型也是一种 seq2seq 模型结构,由 Encoder 和 Decoder 组成,输入是一个序列,输出也是一个序列,可用于文本生成等。其中 Encoders 和 Decoders 都是同质的堆叠架构。
Transformer模型的优点:
- 模型简单易懂,Encoder 和 Decoder 模块高度相似且通用
- (Encoder) 容易并行,模型训练速度快
- 效果拔群,在 NMT 等领域都取得了 state-of-the-art 的效果
下文使用 英->中 机器翻译举例,模型的输入为英文字符串,例如:“I love Shanghai”,输出为翻译后的字符串:“我爱上海”。代码为哈佛的 Pytorch 代码。

更详细的示意图

模型的参数主要有:
-
N N N:表示 Encoder 中 layer 堆叠的个数,论文中使用 6 6 6 层堆叠
-
d m o d e l d_{model} dmodel:即是词向量维度,又是隐藏层维度。论文中使用 512 512 512
-
d f f d_{ff} dff : 线性层中间维度 2048
-
h h h:表示注意力头的个数,文章设置为 8 8 8
-
d r o p o u t dropout dropout:文章中使用 0.1 0.1 0.1
模型输入
Transformer 模型的输入包括两部分:词嵌入向量 (embedding vector) 和位置编码 (positional encoding)。
Position encoding 使用一个与词向量 维度相同 的向量表示位置信息。将 position encoding 与相应位置的词向量相加作为模型的输入,维度为 [batch, seqence_len, 512]。论文中讨论了

Embedding Vector
输入为词嵌入向量。构建词嵌入层可以使用 PyTorch 中的 nn.Embedding :
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
Positional Encoding
self-Attention模块完全没有考虑 单词的顺序。即使我们将句子中单词的顺序完全打乱,对于 Transformer 这个模型来说,并没有什么区别。为了加入句子中单词的顺序信息,我们引入一个概念叫做 positional encoding。
编码位置信息的两种方式:1. 使用等式计算固定的位置向量;2. 在训练模型时直接学习位置向量。结果表明两者的效果类似。 a a a
- 用不同频率的sine和cosine函数直接计算
- 学习出一份positional embedding(参考文献)
P E ( p o s , 2 i ) = sin ( pos / 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( pos / 1000 0 2 i / d m o d e l ) P E_{(p o s, 2 i)}=\sin \left(\operatorname{pos} / 10000^{2 i / d_{m o d e l}}\right) \\ P E_{(p o s, 2 i+1)}=\cos \left(\operatorname{pos} / 10000^{2 i / d_{m o d e l}}\right) PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
p o s pos pos 表示单词在句子中的位置,如 “love” 的位置为 2。 i i i 表示位置编码的维度编号,位置编码向量的维度为 512,所以 i 的取值范围为 [1 - 512]。三角函数的周期性使得 k 位置的值可以被 k-n 表示。
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
Encoder
Encoder 是由结构相同的计算层 (Layer) 堆叠而成的,每个 Layer 由两个子计算层 (sub-layer) 组成,分别是多自注意力层 (multi-head self-attention mechanism) 和全连接层 (fully connected feed-forward network)。其中每个 sub-layer 都使用了残差连接 (residual connection) 和层正则化 (layer normalisation),因此可以将 sub-layer 的输出表示为:
s u b _ l a y e r _ o u t p u t = L a y e r N o r m ( x + ( S u b L a y e r ( x ) ) ) sub\_layer\_output = LayerNorm(x + (SubLayer(x))) sub_layer_output=LayerNorm(x+(SubLayer(x)))
Encoder 的输入首先会经过一个 self-attention 层。self-attention 的作用是让每个单词可以看到自己和其他单词的关系,并且将自己转换成一个与所有单词相关的,focus 在自己身上的词向量。self-attention之后的输出会再经过一层feed-forward神经网络。每个位置的输出被同样的feed-forward network处理。

下面这张图是更详细的 Layer 表示。

class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
# 将 EncoderLayer 层复制 N 份堆叠
self.layers = clones(layer, N)
# layer Normalization
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
"""
size: d_model 词向量维度 512
self_attn: multi-head self-attention 层,MultiHeadedAttention实例
feed_forward:全连接层,PositionwiseFeedForward 实例
"""
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
multi-head attention mechanism
我们考虑用 Transformer 模型翻译下面这一句话:
“The animal didn’t cross the street because it was too tired”。
当我们翻译到 it 的时候,我们知道 it 指代的是 animal 而不是 street。所以,如果有办法可以让 it 对应位置的 embedding 适当包含 animal 的信息,就会非常有用。self-attention的出现就是为了完成这一任务。句子中的任何一个单词使用该句子中的所有单词来表示,也就是说句子中的单词相互表示,将信息柔和到一起。
Self-Attention
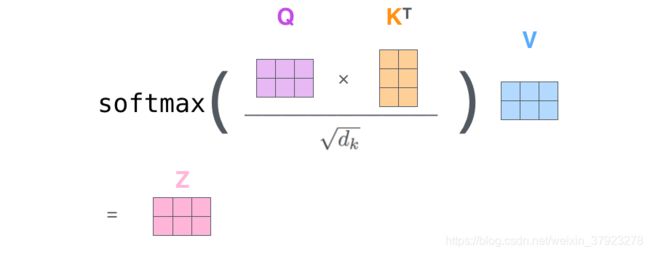
self-attention可由以下形式表示:attention_output = Attention(Q, K, V)
第一步:根据输入的 embedding vector 维度为:[seq_len, emb_dim]通过三个不同的矩阵,线性神经网络层 linear layers W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 维度为:[emb_dim, output_dim]计算出三个向量: Query vector、Key vector和 Value vector 维度为:[seq_len, output_size]。其中 e m b _ d i m emb\_dim emb_dim = 512, o u t p u t _ d i m = 64 output\_dim = 64 output_dim=64。

第二步:是计算注意力 (attention),也就是权重。我们希望知道这个单词与该句中其他单词的关系,因此我们可以使用整个句子来编码每个单词。当我们使用 self-attention 编码 某个位置上的单词时,我们需要计算这个单词在编码时需要编码其他单词的分数(权重),表示当我们编码当前单词的时候,应该放多少的关注度在其余的每个单词上。又或者说,其他单词和当前的单词有多大的相关性或者相似性。这里使用了 scaled dot-product:
A t t e n t i o n ( Q , K , V ) = softmax ( Q K T d k ) V Attention(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
在 Transformer模型中自注意力的计算过程:
- 由 Query vector 和 Key vector 做点积 (dot product) 所得的结果。所以说,当我们在对第一个单词做self-attention处理的时候,第一个单词的分数是 $q_1 $和 k 1 k_1 k1 的点积,第二个分数是 q 1 q_1 q1和 k 2 k _2 k2 的分数。点积结果的维度为 [seq_len, seq_len]。
- 将这些分数除以 key vector 维度 d k d_k dk 的平方根,64的开方为 8,也就是。这样做有利于稳定模型的梯度(gradient),防止矩阵计算的值过大。
- 然后我们将这些分数传入 softmax 层产生注意力的概率分布 (probability scores),值域为 [ 0 : 1 ] [0: 1] [0:1],维度为 [seq_len, seq_len]。
- 最后使用 softmax 的结果与 Value vector 做点积运算计算的self-Attention的输出结果 Z Z Z ,维度为 [seq_len, output_size]。
Multi-headed Attention
multi-head attention 则是拼接多个不同的 self-attention output。在论文中,每个 embedding vector 并不止产生一个 Key, Value, Query vectors,而是产生若干组这样的 vectors,称之为"multi-headed" attention。类似于 CNN 中的 Filter。这么做有几个好处:
-
模型有更强的能力产生不同的 attention 机制,focus 在不同的单词上。
-
attention layer 有多个不同的 representation space。

每个 attention head 最终都产生了一个 matrix 表示这个句子中的所有词向量。在transformer模型中,产生了八个matrices。将这8个matrices拼接到一起 [seq_len, 8*output_dim],然后将拼接的结果传入 feed-forward network 做一次前向神经网络的运算就可以了。 W O W^O WO [8*output_dim, end_output_dim]

综合起来,我们可以用下面一张图表示 Multi-head Self-Attention 模块所做的事情。

得到了 self-attention 生成的词向量之后,我们就可以将它们传入feed-forward network了。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"""Take in model size and number of heads.
h: the number of “heads”,论文中为 8
d_model: 词向量维度,论文中为 512
d_k = d_model / h = 64
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""Implements Figure 2
query, key, value: 第一个Encoder 模块的输入都为 x
维度都为 [nbatches, L, d_model],d_model = 512
"""
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 做线性变换输出 q, k, v,维度不变,
# 转换为multihead维度 [nbatches, 8, L, 64]
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 计算注意力
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
# x.shape: [nbatches, L, 512]
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
# 最后进行一次线性变换 ->[nbatches, L, 512]
return self.linears[-1](x)
def attention(query, key, value, mask=None, dropout=None):
"""Compute 'Scaled Dot Product Attention'
query, key, value 维度为 [nbatches, 8, L, 64]
"""
d_k = query.size(-1)
# [nbatches, 8, L, 64] -> [nbatches, 8, L, L]
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# softmax
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
# matrix multiplication between the attention weights p_attn
# [nbatches, 8, L, 64]
return torch.matmul(p_attn, value), p_attn
Residual Connection and Layer Normalization
另外一个细节是,encoder中的每一个子层都包含了一个 residual connection和 layer-normalization。如下图所示。layer normalization (cite).

Feed-Forward Network
feed-forward network 为带有ReLU激活函数的全连接层 + 线性变换,同样该层使用了 residual connection和 layer-normalization。
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
Encoder最后一层会输出attention vectors、 Key vector 和 Value vector。
Ptorch 实现:torch.nn.TransformerEncoder torch.nn.TransformerEncoderLayer
Decoder
Decoder 与Encoder结构基本相同,主要不同:
- 在 Self-Attention 模块会使用 mask 来防止在预测当前词汇时看到下文的信息。
- Decoder 多了一层 encoder-decoder multi-head attention。
- 在最后有一层线性层和softmax层用来输出预测单词的概率。
在解码的过程中,解码器每一步会输出一个token。一直循环往复,直到它输出了一个特殊的 end of sequence token,表示解码结束了。
Decoder的输入输出和解码过程:
- 输出:对应i位置的输出词的概率分布
- 输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出
- 解码:这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
Masked Multi-Head Attention
Decoder也有同样的 self-attention 和 feed-forward 结构,但是在这两层之间还有一层 encoder-decoder attention 层,帮助 decoder 关注到某一些特别需要关注的 encoder 位置。
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
decoder的self attention机制与encoder稍有不同。在decoder当中,self attention层只能看到之前已经解码的文字。我们只需要把当前输出位置之后的单词全都mask掉(softmax层之前全都设置成-inf)即可。
Encoder-Decoder Attention 层和普通的 multiheaded self-attention 一样,除了它的 Queries 完全来自下面的 decoder 层,然后Key和Value来自 Encoder 的输出 Key vector 和 Value vector。
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# x comes from the previous DecoderLayer,
# while m or “memory” comes from the output of the Encoder
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
最后的线性层和 softmax 层
解码器最后输出浮点向量,如何将它转成词?这是最后的线性层和softmax层的主要工作。
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的 logits 向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
损失函数
采用 cross-entropy 或者 Kullback-Leibler divergence 中的一种。
使用一个句子作为输入。比如,输入是“je suis étudiant”,期望输出是“i am a student”。在这个例子下,我们期望模型输出连续的概率分布满足如下条件:
- 每个概率分布都与词表同维度。
- 第一个概率分布对“i”具有最高的预测概率值。
- 第二个概率分布对“am”具有最高的预测概率值。
- 一直到第五个输出指向"
"标记。

对一个句子而言,训练模型的目标概率分布。我们期望模型产生的概率分布如下所示:

预测:模型每步只产生一组输出,假设模型选择最高概率,扔掉其他的部分,这是种产生预测结果的方法,叫做greedy 解码。另外一种方法是beam search,每一步仅保留最头部高概率的两个输出,根据这俩输出再预测下一步,再保留头部高概率的两个输出,重复直到预测结束。
teacher forcing
In teacher forcing, we make use of the fact that we know what the correct translation should be, and we feed the decoder the symbols that it should have predicted so far. Note that we don’t want the decoder to just learn a copying task, so we’ll only feed it “ Me gustan los” at the step where it’s supposed to be predicting the word “arboles.”
附录
- The Illustrated Transformer 中文翻译
- TF-Transformer model for language understanding
- Transformer 模型的 PyTorch 实现
- 搞懂Transformer结构,看这篇PyTorch实现就够了
- How to code The Transformer in Pytorch