高级程序员知识学习(Redis的扩展应用知识1)
Redis的资源:https://github.com/2462612540/Senior_Architect.git
Redis 基础数据结构
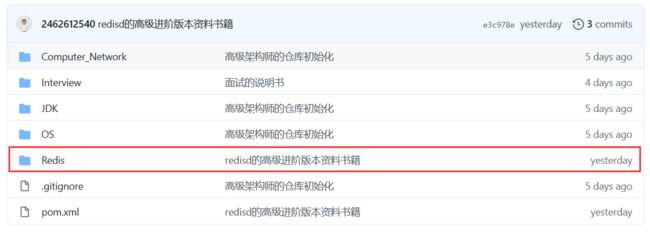
Redis 有 5 种基础数据结构,分别为: string (字符串)、 list (列表)、 set (集合)、 hash (哈希) 和 zset (有序集合)。
string (字符串):字符串 string 是 Redis 最简单的数据结构。 Redis 所有的数据结构都是以唯一的 key字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。同样,取用户信息会经过一次反序列化的过程。Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。

list (列表):Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为O(n),这点让人非常意外。当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。Redis 的列表结构常用来做异步队列使用。 将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
快速列表(qicklist):

如果再深入一点,你会发现 Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的。指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
hash (字典):Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
不同的是, Redis 的字典的值只能是字符串,另外它们 rehash 的方式不一样,因为Java 的 HashMap 在字典很大时, rehash 是个耗时的操作,需要一次性全部 rehash。 Redis为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。

渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。hash 结构也可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分
获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。hash 也有缺点, hash 结构的存储消耗要高于单个字符串,到底该使用 hash 还是字符串,需要根据实际情况再三权衡。
set (集合):Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。 set 结构可以用来存储活动中奖的用户 ID,因为有去重功能,可以保证同一个用户不会中奖两次。(能够保证用户不能同时登入,保证唯一性的一种作用)。
zset (有序列表):zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫着「跳跃列表」的数据结构。zset 中最后一个 value 被移除后,数据结构自动删除,内存被回收。 zset 可以用来存粉丝列表, value 值是粉丝的用户 ID, score 是关注时间。我们可以对粉丝列表按关注时间进行排序。zset 还可以用来存储学生的成绩, value 值是学生的 ID, score 是他的考试成绩。我们可以对成绩按分数进行排序就可以得到他的名次。
跳跃列表:zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较复杂。因为 zset 要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的链表结构。

我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,
那该怎么办?
想想一个创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安排。公司规模进一步扩展,需要再增加一个层级 —— 部门,每个部门会从组长列表中推选出一个代表来作为部长。部长们之间还会有自己的高层会议安排。跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。 想想你老家在世界地图中的位置:亚洲-->中国->安徽省->安庆市->枞阳县->汤沟镇->田间村->xxxx 号,也是这样一个类似的结构。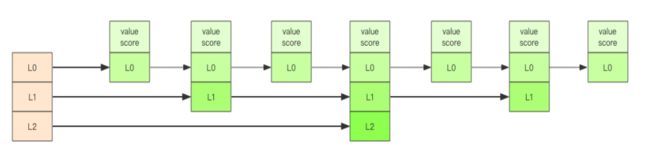
「跳跃列表」之所以「跳跃」,是因为内部的元素可能「身兼数职」,比如上图中间的这个元素,同时处于 L0、 L1 和 L2 层,可以快速在不同层次之间进行「跳跃」。定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合
适的位置,将新元素插进去。你也许会问,那新插入的元素如何才有机会「身兼数职」呢?
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层。首先 L0 层肯定是 100% 了, L1 层只有 50% 的概率, L2 层只有 25% 的概率, L3层只有 12.5% 的概率,一直随机到最顶层 L31 层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
容器型数据结构的通用规则
list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
1、 create if not exists
如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的,Redis 就会自动创建一个,然后再 rpush 进去新元素。
2、 drop if no elements
如果容器里元素没有了,那么立即删除元素,释放内存。这意味着 lpop 操作到最后一个元素,列表就消失了。
过期时间
Redis 所有的数据结构都可以设置过期时间,时间到了, Redis 会自动删除相应的对象。需要注意的是过期是以对象为单位,比如一个 hash 结构的过期是整个 hash 对象的过期,而不是其中的某个子 key。还有一个需要特别注意的地方是如果一个字符串已经设置了过期时间,然后你调用了set 方法修改了它,它的过期时间会消失。
Redis——分布式锁
分布式应用进行逻辑处理时经常会遇到并发问题。比如一个操作要修改用户的状态,修改状态需要先读出用户的状态,在内存里进行修改,改完了再存回去。如果这样的操作同时进行了,就会出现并发问题,因为读取和保存状态这两个操作不是原子的。( Wiki 解释:所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch 线程切换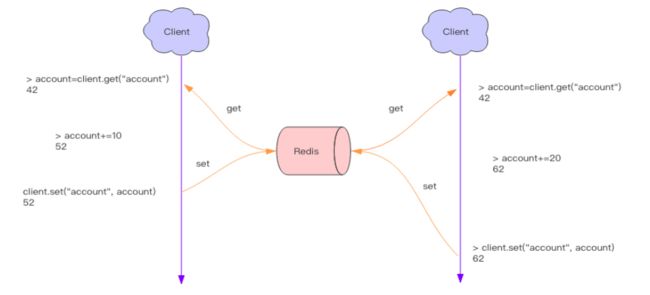
这个时候就要使用到分布式锁来限制程序的并发执行。 Redis 分布式锁使用非常广泛,它是面试的重要考点之一,很多同学都知道这个知识,也大致知道分布式锁的原理,但是具体到细节的使用上往往并不完全正确。
分布式锁:分布式锁本质上要实现的目标就是在 Redis 里面占一个“茅坑”,当别的进程也要来占时,发现已经有人蹲在那里了,就只好放弃或者稍后再试。占坑一般是使用 setnx(set if not exists) 指令,只允许被一个客户端占坑。先来先占, 用完了,再调用 del 指令释放茅坑。
但是有个问题,如果逻辑执行到中间出现异常了,可能会导致 del 指令没有被调用,这样就会陷入死锁,锁永远得不到释放。于是我们在拿到锁之后,再给锁加上一个过期时间,比如 5s,这样即使中间出现异常也可以保证 5 秒之后锁会自动释放。但是以上逻辑还有问题。如果在 setnx 和 expire 之间服务器进程突然挂掉了,可能是因为机器掉电或者是被人为杀掉的,就会导致 expire 得不到执行,也会造成死锁。
这种问题的根源就在于 setnx 和 expire 是两条指令而不是原子指令。如果这两条指令可以一起执行就不会出现问题。也许你会想到用 Redis 事务来解决。但是这里不行,因为 expire是依赖于 setnx 的执行结果的,如果 setnx 没抢到锁, expire 是不应该执行的。事务里没有 ifelse 分支逻辑,事务的特点是一口气执行,要么全部执行要么一个都不执行。为了解决这个疑难, Redis 开源社区涌现了一堆分布式锁的 library,专门用来解决这个问题。实现方法极为复杂,小白用户一般要费很大的精力才可以搞懂。如果你需要使用分布式锁,意味着你不能仅仅使用 Jedis 或者 redis-py 就行了,还得引入分布式锁的 library。
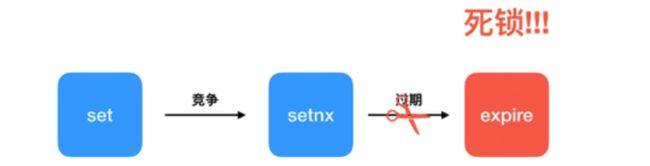
为了治理这个乱象, Redis 2.8 版本中作者加入了 set 指令的扩展参数,使得 setnx 和expire 指令可以一起执行,彻底解决了分布式锁的乱象。从此以后所有的第三方分布式锁library 可以休息了。 > set lock:codehole true ex 5 nx OK ... do something critical ... > del lock:codehole 上面这个指令就是 setnx 和 expire 组合在一起的原子指令,它就是分布式锁的奥义所在。
超时问题:Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。因为这时候锁过期了,第二个线程重新持有了这把锁,但是紧接着第一个线程执行完了业务逻辑,就把锁给释放了,第三个线程就会在第二个线程逻辑执行完之间拿到了锁。为了避免这个问题, Redis 分布式锁不要用于较长时间的任务。如果真的偶尔出现了,数据出现的小波错乱可能需要人工介入解决。
tag = random.nextint() # 随机数
if redis.set(key, tag, nx=True, ex=5):
do_something()
redis.delifequals(key, tag)有一个更加安全的方案是为 set 指令的 value 参数设置为一个随机数,释放锁时先匹配随机数是否一致,然后再删除 key。但是匹配 value 和删除 key 不是一个原子操作, Redis 也没有提供类似于 delifequals 这样的指令,这就需要使用 Lua 脚本来处理了,因为 Lua 脚本可以保证连续多个指令的原子性执行。
# delifequals
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
可重入性:可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持同一个线程的多次加锁,那么这个锁就是可重入的。比如 Java 语言里有个 ReentrantLock 就是可重入锁。 Redis 分布式锁如果要支持可重入,需要对客户端的 set 方法进行包装,使用线程的 Threadlocal 变量存储当前持有锁的计数
# -*- coding: utf-8
import redis
import threading
locks = threading.local()
locks.redis = {}
def key_for(user_id):
return "account_{}".format(user_id)
def _lock(client, key):
return bool(client.set(key, True, nx=True, ex=5))
def _unlock(client, key):
client.delete(key)
def lock(client, user_id):
key = key_for(user_id)
if key in locks.redis:
locks.redis[key] += 1
return True
ok = _lock(client, key)
if not ok:
return False
locks.redis[key] = 1
return True
def unlock(client, user_id):
key = key_for(user_id)
if key in locks.redis:
locks.redis[key] -= 1
if locks.redis[key] <= 0:
del locks.redis[key]
return True
return False
client = redis.StrictRedis()
print "lock", lock(client, "codehole")
print "lock", lock(client, "codehole")
print "unlock", unlock(client, "codehole")
print "unlock", unlock(client, "codehole")以上还不是可重入锁的全部,精确一点还需要考虑内存锁计数的过期时间,代码复杂度将会继续升高。老钱不推荐使用可重入锁,它加重了客户端的复杂性,在编写业务方法时注意在逻辑结构上进行调整完全可以不使用可重入锁。下面是 Java 版本的可重入锁。
public class RedisWithReentrantLock {
private ThreadLocalRedis——延时队列
我们平时习惯于使用 Rabbitmq 和 Kafka 作为消息队列中间件,来给应用程序之间增加异步消息传递功能。这两个中间件都是专业的消息队列中间件,特性之多超出了大多数人的理解能力。
使用过 Rabbitmq 的同学知道它使用起来有多复杂,发消息之前要创建 Exchange,再创建 Queue,还要将 Queue 和 Exchange 通过某种规则绑定起来,发消息的时候要指定 routingkey,还要控制头部信息。消费者在消费消息之前也要进行上面一系列的繁琐过程。但是绝大多数情况下,虽然我们的消息队列只有一组消费者,但还是需要经历上面这些繁琐的过程。有了 Redis,它就可以让我们解脱出来,对于那些只有一组消费者的消息队列,使用 Redis就可以非常轻松的搞定。 Redis 的消息队列不是专业的消息队列,它没有非常多的高级特性,没有 ack 保证,如果对消息的可靠性有着极致的追求,那么它就不适合使用。
异步消息队列:Redis 的 list(列表) 数据结构常用来作为异步消息队列使用,使用 rpush/lpush操作入队列,使用 lpop 和 rpop 来出队列。
队列空了怎么办?
客户端是通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息,再进行处理。如此循环往复,这便是作为队列消费者的客户端的生命周期。可是如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop,没有数据,接着再 pop,又没有数据。这就是浪费生命的空轮询。空轮询不但拉高了客户端的 CPU, redis 的 QPS 也会被拉高,如果这样空轮询的客户端有几十来个, Redis 的慢查询可能会显著增多。通常我们使用 sleep 来解决这个问题,让线程睡一会,睡个 1s 钟就可以了。不但客户端的 CPU 能降下来, Redis 的 QPS 也降下来了
队列延迟(来保证队列中的是不会有空轮训的效果)
用上面睡眠的办法可以解决问题。但是有个小问题,那就是睡眠会导致消息的延迟增大。如果只有 1 个消费者,那么这个延迟就是 1s。如果有多个消费者,这个延迟会有所下降,因为每个消费者的睡觉时间是岔开来的。有没有什么办法能显著降低延迟呢?你当然可以很快想到:那就把睡觉的时间缩短点。这种方式当然可以,不过有没有更好的解决方案呢?当然也有,那就是 blpop/brpop。这两个指令的前缀字符 b 代表的是 blocking,也就是阻塞读。
阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用 blpop/brpop 替代前面的 lpop/rpop,就完美解决了上面的问题。 ...
空闲连接自动断开
你以为上面的方案真的很完美么?先别急着开心,其实他还有个问题需要解决。什么问题? —— 空闲连接的问题。如果线程一直阻塞在哪里, Redis 的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候 blpop/brpop 会抛出异常来。所以编写客户端消费者的时候要小心,注意捕获异常,还要重试。 ...
锁冲突处理
上节课我们讲了分布式锁的问题,但是没有提到客户端在处理请求时加锁没加成功怎么办。一般有 3 种策略来处理加锁失败:
1、 直接抛出异常, 通知用户稍后重试;
2、 sleep 一会再重试;
3、 将请求转移至延时队列, 过一会再试;
直接抛出特定类型的异常
这种方式比较适合由用户直接发起的请求,用户看到错误对话框后,会先阅读对话框的内容,再点击重试,这样就可以起到人工延时的效果。如果考虑到用户体验,可以由前端的代码替代用户自己来进行延时重试控制。它本质上是对当前请求的放弃,由用户决定是否重新发起新的请求。
sleep
sleep 会阻塞当前的消息处理线程,会导致队列的后续消息处理出现延迟。如果碰撞的比较频繁或者队列里消息比较多, sleep 可能并不合适。如果因为个别死锁的 key 导致加锁不成功,线程会彻底堵死,导致后续消息永远得不到及时处理。
延时队列
这种方式比较适合异步消息处理,将当前冲突的请求扔到另一个队列延后处理以避开冲突。延时队列的实现延时队列可以通过 Redis 的 zset(有序列表) 来实现。我们将消息序列化成一个字符串作为 zset 的 value,这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理,多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处
理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。
def delay(msg):
msg.id = str(uuid.uuid4()) # 保证 value 值唯一
value = json.dumps(msg)
retry_ts = time.time() + 5 # 5 秒后重试
redis.zadd("delay-queue", retry_ts, value)
def loop():
while True:
# 最多取 1 条
values = redis.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1)
if not values:
time.sleep(1) # 延时队列空的,休息 1s
continue
value = values[0] # 拿第一条,也只有一条
success = redis.zrem("delay-queue", value) # 从消息队列中移除该消息
if success: # 因为有多进程并发的可能,最终只会有一个进程可以抢到消息
msg = json.loads(value)
handle_msg(msg)进一步优化:
上面的算法中同一个任务可能会被多个进程取到之后再使用 zrem 进行争抢,那些没抢到的进程都是白取了一次任务,这是浪费。可以考虑使用 lua scripting 来优化一下这个逻辑,将zrangebyscore 和 zrem 一同挪到服务器端进行原子化操作,这样多个进程之间争抢任务时就不会出现这种浪费了。
Redis——位图
在我们平时开发过程中,会有一些 bool 型数据需要存取,比如用户一年的签到记录,签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365个,当用户上亿的时候,需要的存储空间是惊人的。为了解决这个问题, Redis 提供了位图数据结构,这样每天的签到记录只占据一个位,365 天就是 365 个位, 46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大节约了存储空间。

位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit等将 byte 数组看成「位数组」来处理。以老钱的经验,在面试中有 Redis 位图使用经验的同学很少,如果你对 Redis 的位图有所了解,它将会是你的面试加分项
基本使用:Redis 的位数组是自动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
接下来我们使用位操作将字符串设置为 hello (不是直接使用 set 指令),首先我们需要得到 hello 的 ASCII 码,用 Python 命令行可以很方便地得到每个字符的 ASCII 码的二进制值。
统计和查找
Redis 提供了位图统计指令 bitcount 和位图查找指令 bitpos, bitcount 用来统计指定位置范围内 1 的个数, bitpos 用来查找指定范围内出现的第一个 0 或 1。比如我们可以通过 bitcount 统计用户一共签到了多少天,通过 bitpos 指令查找用户从哪一天开始第一次签到。如果指定了范围参数[start, end],就可以统计在某个时间范围内用户签到了多少天,用户自某天以后哪天开始签到。
遗憾的是, start 和 end 参数是字节索引,也就是说指定的位范围必须是 8 的倍数,而不能任意指定。这很奇怪,我表示不是很能理解 Antirez 为什么要这样设计。因为这个设计,我们无法直接计算某个月内用户签到了多少天,而必须要将这个月所覆盖的字节内容全部取出来 (getrange 可以取出字符串的子串) 然后在内存里进行统计,这个非常繁琐。
魔术指令 bitfield
前文我们设置 (setbit) 和获取 (getbit) 指定位的值都是单个位的,如果要一次操作多个位,就必须使用管道来处理。 不过 Redis 的 3.2 版本以后新增了一个功能强大的指令,有了这条指令,不用管道也可以一次进行多个位的操作。 bitfield 有三个子指令,分别是get/set/incrby,它们都可以对指定位片段进行读写,但是最多只能处理 64 个连续的位,如果超过 64 位,就得使用多个子指令, bitfield 可以一次执行多个子指令。

Redis——HyperLogLog
在开始这一节之前,我们先思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求, incrby 一次,最终就可以统计出所有的 PV数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一ID 来标识。
你也许已经想到了一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。没错,这是一个非常简单的方案。但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大
的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实老板需要的数据又不需要太精确, 105w 和 106w 这两个数字对于老板们来说并没有多大区别, So,有没有更好的解决方案呢?
这就是本节要引入的一个解决方案, Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。 HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用,但是令人感到意外的是,使用过它的人非常少。
pfmerge 适合什么场合用?
HyperLogLog 除了上面的 pfadd 和 pfcount 之外,还提供了第三个指令 pfmerge,用于将多个 pf 计数值累加在一起形成一个新的 pf 值。比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。其中页面的 UV 访问量也需要合并,那这个时候 pfmerge 就可以派上用场了。
注意事项
HyperLogLog 这个数据结构不是免费的,不是说使用这个数据结构要花钱,它需要占据一定 12k 的存储空间,所以它不适合统计单个用户相关的数据。如果你的用户上亿,可以算算,这个空间成本是非常惊人的。但是相比 set 存储方案, HyperLogLog 所使用的空间那真是可以使用千斤对比四两来形容了。不过你也不必过于当心,因为 Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。
HyperLogLog 实现原理
HyperLogLog 的使用非常简单,但是实现原理比较复杂,如果读者没有特别的兴趣,下面的内容暂时可以跳过不看。为了方便理解 HyperLogLog 的内部实现原理,我画了下面这张图。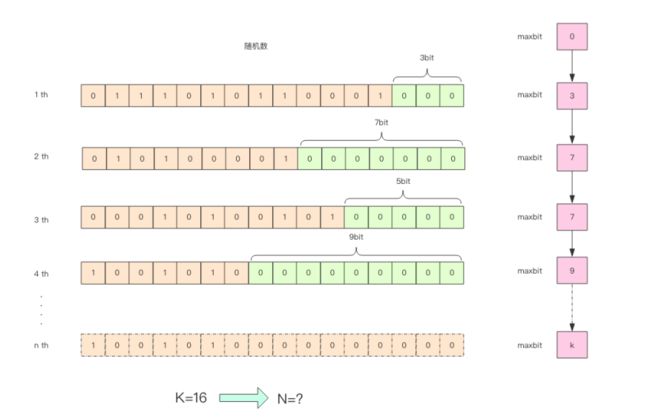
这张图的意思是,给定一系列的随机整数,我们记录下低位连续零位的最大长度 k,通过这个 k 值可以估算出随机数的数量。 首先不问为什么,我们编写代码做一个实验,观察一下随机整数的数量和 k 值的关系。
pf 的内存占用为什么是 12k?
我们在上面的算法中使用了 1024 个桶进行独立计数,不过在 Redis 的 HyperLogLog实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是 2^14 * 6 / 8 = 12k 字节。
Redis——布隆过滤器
上一节我们学会了使用 HyperLogLog 数据结构来进行估数,它非常有价值,可以解决很多精确度不高的统计需求。但是如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面了,它就无能为力了,它只提供了 pfadd 和 pfcount 方法,没有提供 pfcontains 这种方法。
讲个使用场景,比如我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的?
你会想到服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。问题是当用户量很大,每个用户看过的新闻又很多的情况下,这种方式,推荐系统的去重工作在性能上跟的上么?
实际上,如果历史记录存储在关系数据库里,去重就需要频繁地对数据库进行 exists 查询,当系统并发量很高时,数据库是很难扛住压力的。你可能又想到了缓存,但是如此多的历史记录全部缓存起来,那得浪费多大存储空间啊?而且这个存储空间是随着时间线性增长,你撑得住一个月,你能撑得住几年么?但是不缓存的话,性能又跟不上,这该怎么办?
这时,布隆过滤器 (Bloom Filter) 闪亮登场了,它就是专门用来解决这种去重问题的。它在起到去重的同时,在空间上还能节省 90% 以上,只是稍微有那么点不精确,也就是有一定的误判概率。
布隆过滤器是什么?
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见
过你。
套在上面的使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极小一部分 (误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
Redis 中的布隆过滤器:
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。下面我们来体验一下 Redis 4.0 的布隆过滤器,为了省去繁琐安装过程,我们直接用
Docker 吧。
> docker pull redislabs/rebloom # 拉取镜像
> docker run -p6379:6379 redislabs/rebloom # 运行容器
> redis-cli # 连接容器中的 redis 服务
如果上面三条指令执行没有问题,下面就可以体验布隆过滤器了。布隆过滤器基本使用
布隆过滤器有二个基本指令, bf.add 添加元素, bf.exists 查询元素是否存在,它的用法和 set 集合的 sadd 和 sismember 差不多。注意 bf.add 只能一次添加一个元素,如果想要一次添加多个,就需要用到 bf.madd 指令。同样如果需要一次查询多个元素是否存在,就需要用到 bf.mexists 指令。

Redis——简单的限流
限流算法在分布式领域是一个经常被提起的话题,当系统的处理能力有限时,如何阻止计划外的请求继续对系统施压,这是一个需要重视的问题。在这里用 “断尾求生” 形容限流背后的思想,限流还有一个应用目的是用于控制用户行为,避免垃圾请求。比如在UGC 社区,用户的发帖、回复、点赞等行为都要严格受控,一般要严格限定某行为在规定时间内允许的次数,超过了次数那就是非法行为。对非法行为,业务必须规定适当的惩处策略。
首先我们来看一个常见的简单的限流策略。系统要限定用户的某个行为在指定的时间里只能允许发生 N 次,如何使用 Redis 的数据结构来实现这个限流的功能?我们先定义这个接口,理解了这个接口的定义,读者就应该能明白我们期望达到的功能。
# 指定用户 user_id 的某个行为 action_key 在特定的时间内 period 只允许发生一定的次数
max_count
def is_action_allowed(user_id, action_key, period, max_count):
return True
# 调用这个接口 , 一分钟内只允许最多回复 5 个帖子
can_reply = is_action_allowed("laoqian", "reply", 60, 5)
if can_reply:
do_reply()
else:
raise ActionThresholdOverflow()这个限流需求中存在一个滑动时间窗口,想想 zset 数据结构的 score 值,是不是可以通过 score 来圈出这个时间窗口来。而且我们只需要保留这个时间窗口,窗口之外的数据都可以砍掉。那这个 zset 的 value 填什么比较合适呢?它只需要保证唯一性即可,用 uuid 会比较浪费空间,那就改用毫秒时间戳吧。
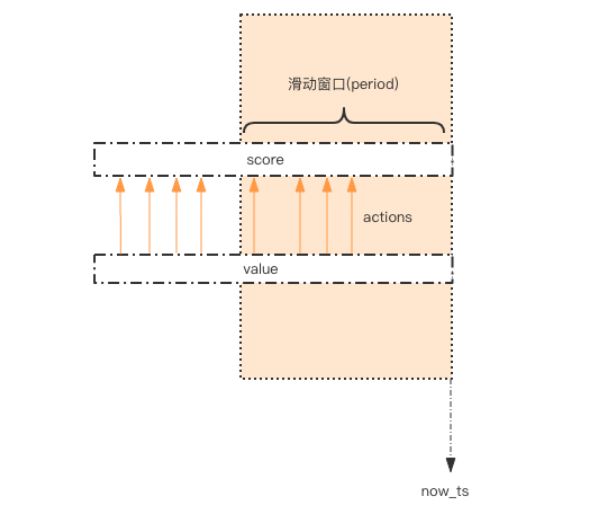
如图所示,用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个key 保存下来。同一个用户同一种行为用一个 zset 记录。为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。通过统计滑动窗口内的行为数量与阈值 max_count 进行比较就可以得出当前的行为是否允许。用代码表示如下:
# coding: utf8
import time
import redis
client = redis.StrictRedis()
def is_action_allowed(user_id, action_key, period, max_count):
key = 'hist:%s:%s' % (user_id, action_key)
now_ts = int(time.time() * 1000) # 毫秒时间戳
with client.pipeline() as pipe: # client 是 StrictRedis 实例
# 记录行为
pipe.zadd(key, now_ts, now_ts) # value 和 score 都使用毫秒时间戳
# 移除时间窗口之前的行为记录,剩下的都是时间窗口内的
pipe.zremrangebyscore(key, 0, now_ts - period * 1000)
# 获取窗口内的行为数量
pipe.zcard(key)
# 设置 zset 过期时间,避免冷用户持续占用内存
# 过期时间应该等于时间窗口的长度,再多宽限 1s
pipe.expire(key, period + 1)
# 批量执行
_, _, current_count, _ = pipe.execute()
# 比较数量是否超标
return current_count <= max_count
for i in range(20):
print is_action_allowed("laoqian", "reply", 60, 5)如何使用 Redis 来实现简单限流策略?
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。

Redis—— GeoHash算法
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能了。
用数据库来算附近的人
地图元素的位置数据使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90,90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为界,东正西负。比如掘金办公室在望京 SOHO,它的经纬度坐标是 (116.48105,39.996794),都是正数,因为中国位于东北半球。当两个元素的距离不是很远时,可以直接使用勾股定理就能算得元素之间的距离。我们平时使用的「附近的人」的功能,元素距离都不是很大,勾股定理算距离足矣。不过需要注意的是,经纬度坐标的密度不一样 (经度总共 360 度,纬度总共 180 度),勾股定律计算平方差时之后再求和时,需要按一定的系数比加权求和。
现在,如果要计算「附近的人」,也就是给定一个元素的坐标,然后计算这个坐标附近的其它元素,按照距离进行排序,该如何下手?
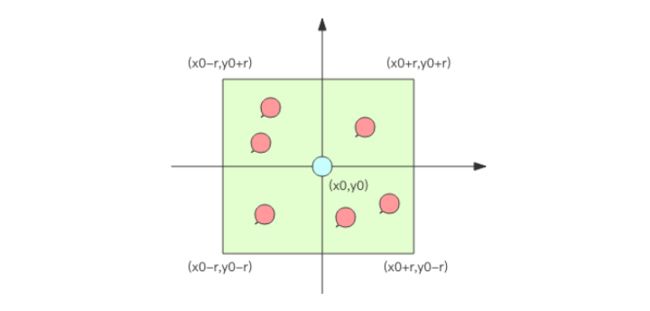
如果现在元素的经纬度坐标使用关系数据库 (元素 id, 经度 x, 纬度 y) 存储,你该如何计算?
首先,你不可能通过遍历来计算所有的元素和目标元素的距离然后再进行排序,这个计算量太大了,性能指标肯定无法满足。一般的方法都是通过矩形区域来限定元素的数量,然后对区域内的元素进行全量距离计算再排序。这样可以明显减少计算量。如何划分矩形区域呢?可以指定一个半径 r,使用一条 SQL 就可以圈出来。当用户对筛出来的结果不满意,那就扩大半径继续筛选。
select id from positions where x0-r < x < x0+r and y0-r < y < y0+r为了满足高性能的矩形区域算法,数据表需要在经纬度坐标加上双向复合索引 (x, y),这样可以最大优化查询性能。但是数据库查询性能毕竟有限,如果「附近的人」查询请求非常多,在高并发场合,这可能并不是一个很好的方案。注意在高并发的场景中的时候。
GeoHash 算法
业界比较通用的地理位置距离排序算法是 GeoHash 算法, Redis 也使用 GeoHash 算法。 GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了
那这个映射算法具体是怎样的呢?
它将整个地球看成一个二维平面,然后划分成了一系列正方形的方格,就好比围棋棋盘。所有的地图元素坐标都将放置于唯一的方格中。方格越小,坐标越精确。然后对这些方格进行整数编码,越是靠近的方格编码越是接近。
那如何编码呢?
一个最简单的方案就是切蛋糕法。设想一个正方形的蛋糕摆在你面前,二刀下去均分分成四块小正方形,这四个小正方形可以分别标记为 00,01,10,11 四个二进制整数。然后对每一个小正方形继续用二刀法切割一下,这时每个小小正方形就可以使用 4bit 的二进制整数予以表示。然后继续切下去,正方形就会越来越小,二进制整数也会越来越长,精确度就会越来越高。上面的例子中使用的是二刀法,真实算法中还会有很多其它刀法,最终编码出来的整数数字也都不一样。编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程度就越小。对于「附近的人」这个功能而言,损失的一点精确度可以忽略不计。
GeoHash 算法会继续对这个整数做一次 base32 编码 (0-9,a-z 去掉 a,i,l,o 四个字母) 变成一个字符串。在 Redis 里面,经纬度使用 52 位的整数进行编码,放进了 zset 里面, zset的 value 是元素的 key, score 是 GeoHash 的 52 位整数值。 zset 的 score 虽然是浮点数,但是对于 52 位的整数值,它可以无损存储。
在使用 Redis 进行 Geo 查询时,我们要时刻想到它的内部结构实际上只是一个zset(skiplist)。通过 zset 的 score 排序就可以得到坐标附近的其它元素 (实际情况要复杂一些,不过这样理解足够了),通过将 score 还原成坐标值就可以得到元素的原始坐标。
小结 & 注意事项
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。所以,这里建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。
Redis-Scan
在平时线上 Redis 维护工作中,有时候需要从 Redis 实例成千上万的 key 中找出特定前缀的 key 列表来手动处理数据,可能是修改它的值,也可能是删除 key。这里就有一个问题,如何从海量的 key 中找出满足特定前缀的 key 列表来?这个指令使用非常简单,提供一个简单的正则字符串即可,但是有很明显的两个缺点。
1、 没有 offset、 limit 参数, 一次性吐出所有满足条件的 key, 万一实例中有几百 w 个key 满足条件, 当你看到满屏的字符串刷的没有尽头时, 你就知道难受了。
2、 keys 算法是遍历算法, 复杂度是 O(n), 如果实例中有千万级以上的 key, 这个指令就会导致 Redis 服务卡顿, 所有读写 Redis 的其它的指令都会被延后甚至会超时报错, 因为Redis 是单线程程序, 顺序执行所有指令, 其它指令必须等到当前的 keys 指令执行完了才可以继续。
面对这两个显著的缺点该怎么办呢?Redis 为了解决这个问题,它在 2.8 版本中加入了大海捞针的指令——scan。 scan 相比keys 具备有以下特点:
- 复杂度虽然也是 O(n), 但是它是通过游标分步进行的, 不会阻塞线程;
- 提供 limit 参数, 可以控制每次返回结果的最大条数, limit 只是一个 hint, 返回的结果可多可少;
- 同 keys 一样, 它也提供模式匹配功能;
- 服务器不需要为游标保存状态, 游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复, 需要客户端去重复, 这点非常重要;
- 遍历的过程中如果有数据修改, 改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束, 而要看返回的游标值是否为零;
scan 遍历顺序
scan 的遍历顺序非常特别。它不是从第一维数组的第 0 位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
普通加法和高位进位加法的区别
高位进位法从左边加,进位往右边移动,同普通加法正好相反。但是最终它们都会遍历所有的槽位并且没有重复。
在平时的业务开发中,要尽量避免大 key 的产生。
如果你观察到 Redis 的内存大起大落,这极有可能是因为大 key 导致的,这时候你就需要定位出具体是那个 key,进一步定位出具体的业务来源,然后再改进相关业务代码设计。
那如何定位大 key 呢?
为了避免对线上 Redis 带来卡顿,这就要用到 scan 指令,对于扫描出来的每一个key,使用 type 指令获得 key 的类型,然后使用相应数据结构的 size 或者 len 方法来得到它的大小,对于每一种类型,保留大小的前 N 名作为扫描结果展示出来。
上面这样的过程需要编写脚本,比较繁琐,不过 Redis 官方已经在 redis-cli 指令中提供了这样的扫描功能,我们可以直接拿来即用。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys
如果你担心这个指令会大幅抬升 Redis 的 ops 导致线上报警,还可以增加一个休眠参数。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
上面这个指令每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长。
Redis——线程IO模型的原理
非阻塞 IO 在套接字对象上提供了一个选项 Non_Blocking,当这个选项打开时,读写方法不会阻塞,而是能读多少读多少,能写多少写多少。能读多少取决于内核为套接字分配的读缓冲区内部的数据字节数,能写多少取决于内核为套接字分配的写缓冲区的空闲空间字节数。读方法和写方法都会通过返回值来告知程序实际读写了多少字节。有了非阻塞 IO 意味着线程在读写 IO 时可以不必再阻塞了,读写可以瞬间完成然后线程可以继续干别的事了。
事件轮询 (多路复用):
非阻塞 IO 有个问题,那就是线程要读数据,结果读了一部分就返回了,线程如何知道何时才应该继续读。也就是当数据到来时,线程如何得到通知。写也是一样,如果缓冲区满了,写不完,剩下的数据何时才应该继续写,线程也应该得到通知:

事件轮询 API 就是用来解决这个问题的,最简单的事件轮询 API 是 select 函数,它是操作系统提供给用户程序的 API。输入是读写描述符列表 read_fds & write_fds,输出是与之对应的可读可写事件。同时还提供了一个 timeout 参数,如果没有任何事件到来,那么就最多等待 timeout 时间,线程处于阻塞状态。一旦期间有任何事件到来,就可以立即返回。时间过了之后还是没有任何事件到来,也会立即返回。 拿到事件后,线程就可以继续挨个处理相应的事件。处理完了继续过来轮询。于是线程就进入了一个死循环,我们把这个死循环称为事件循环,一个循环为一个周期。
现代操作系统的多路复用 API 已经不再使用 select 系统调用,而改用 epoll(linux)和 kqueue(freebsd & macosx),因为 select 系统调用的性能在描述符特别多时性能会非常差。它们使用起来可能在形式上略有差异,但是本质上都是差不多的,都可以使用上面的伪代码逻辑进行理解。服务器套接字 serversocket 对象的读操作是指调用 accept 接受客户端新连接。何时有新连接到来,也是通过 select 系统调用的读事件来得到通知的。
定时任务
服务器处理要响应 IO 事件外,还要处理其它事情。比如定时任务就是非常重要的一件事。如果线程阻塞在 select 系统调用上,定时任务将无法得到准时调度。那 Redis 是如何解决这个问题的呢?Redis 的定时任务会记录在一个称为最小堆的数据结构中。这个堆中,最快要执行的任务排在堆的最上方。在每个循环周期, Redis 都会将最小堆里面已经到点的任务立即进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是 select 系统调用的 timeout 参数。因为 Redis 知道未来 timeout 时间内,没有其它定时任务需要处理,所以可以安心睡眠 timeout 的时间。
Redis——通信协议
RESP 是 Redis 序列化协议的简写。它是一种直观的文本协议,优势在于实现异常简单,解析性能极好。Redis 协议将传输的结构数据分为 5 种最小单元类型,单元结束时统一加上回车换行符号\r\n。

小结
Redis 协议里有大量冗余的回车换行符,但是这不影响它成为互联网技术领域非常受欢迎的一个文本协议。有很多开源项目使用 RESP 作为它的通讯协议。在技术领域性能并不总是一切,还有简单性、易理解性和易实现性,这些都需要进行适当权衡。
Redis——持久化
Redis 的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制。Redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志。快照是一次全量备
份, AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧而 AOF 日志记录的是内存数据修改的指令记录文本。 AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
Redis 使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化,这个机制很有意思,也很少人知道。多进程 COW 也是鉴定程序员知识广度的一个重要指标。
fork(多进程)
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时你可以将父子进程想像成一个连体婴儿,共享身体。这是 Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享起来。进程分离的一瞬间,内存的增长几乎没有明显变化。
AOF 原理:AOF 日志存储的是 Redis 服务器的顺序指令序列, AOF 日志只记录对内存进行修改的指令记录。
假设 AOF 日志记录了自 Redis 实例创建以来所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例顺序执行所有的指令,也就是「重放」,来恢复 Redis 当前实例的内存数据结构的状态。Redis 会在收到客户端修改指令后,先进行参数校验,如果没问题,就立即将该指令文本存储到 AOF 日志中,也就是先存到磁盘,然后再执行指令。这样即使遇到突发宕机,已经存储到 AOF 日志的指令进行重放一下就可以恢复到宕机前的状态。Redis 在长期运行的过程中, AOF 的日志会越变越长。如果实例宕机重启,重放整个AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志瘦身。
Redis——管道

这便是管道操作的本质,服务器根本没有任何区别对待,还是收到一条消息,执行一条消息,回复一条消息的正常的流程。客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。管道中指令越多,效果越好。
接下来我们深入分析一个请求交互的流程,真实的情况是它很复杂,因为要经过网络协议栈,这个就得深入内核了。
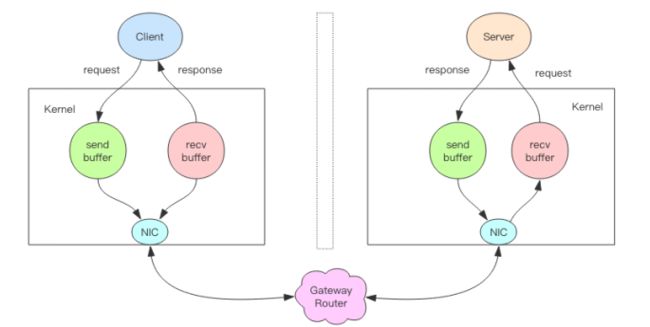
上图就是一个完整的请求交互流程图。我用文字来仔细描述一遍:
- 1、 客户端进程调用 write 将消息写到操作系统内核为套接字分配的发送缓冲 send buffer。
- 2、 客户端操作系统内核将发送缓冲的内容发送到网卡, 网卡硬件将数据通过「网际路由」送到服务器的网卡。
- 3、 服务器操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer。
- 4、 服务器进程调用 read 从接收缓冲中取出消息进行处理。
- 5、 服务器进程调用 write 将响应消息写到内核为套接字分配的发送缓冲 send buffer。
- 6、 服务器操作系统内核将发送缓冲的内容发送到网卡, 网卡硬件将数据通过「网际路由」送到客户端的网卡。
- 7、 客户端操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer。
- 8、 客户端进程调用 read 从接收缓冲中取出消息返回给上层业务逻辑进行处理。
- 9、 结束。
我们开始以为 write 操作是要等到对方收到消息才会返回,但实际上不是这样的。 write操作只负责将数据写到本地操作系统内核的发送缓冲然后就返回了。剩下的事交给操作系统内核异步将数据送到目标机器。但是如果发送缓冲满了,那么就需要等待缓冲空出空闲空间来,这个就是写操作 IO 操作的真正耗时。
我们开始以为 read 操作是从目标机器拉取数据,但实际上不是这样的。 read 操作只负责将数据从本地操作系统内核的接收缓冲中取出来就了事了。但是如果缓冲是空的,那么就需要等待数据到来,这个就是读操作 IO 操作的真正耗时。
所以对于 value = redis.get(key)这样一个简单的请求来说, write 操作几乎没有耗时,直接写到发送缓冲就返回,而 read 就会比较耗时了,因为它要等待消息经过网络路由到目标机器处理后的响应消息,再回送到当前的内核读缓冲才可以返回。这才是一个网络来回的真正开销。
而对于管道来说,连续的 write 操作根本就没有耗时,之后第一个 read 操作会等待一个网络的来回开销,然后所有的响应消息就都已经回送到内核的读缓冲了,后续的 read 操作直接就可以从缓冲拿到结果,瞬间就返回了。
小结:这就是管道的本质了,它并不是服务器的什么特性,而是客户端通过改变了读写的顺序带来的性能的巨大提升。
Redis——事务
每个事务的操作都有 begin、 commit 和 rollback, begin 指示事务的开始, commit 指示事务的提交, rollback 指示事务的回滚。它大致的形式如下:
begin();
try {
command1();
command2();
....
commit();
} catch(Exception e) {
rollback();
}Redis 在形式上看起来也差不多,分别是 multi/exec/discard。 multi 指示事务的开始,exec 指示事务的执行, discard 指示事务的丢弃。
Watch:考虑到一个业务场景, Redis 存储了我们的账户余额数据,它是一个整数。现在有两个并发的客户端要对账户余额进行修改操作,这个修改不是一个简单的 incrby 指令,而是要对余额乘以一个倍数。 Redis 可没有提供 multiplyby 这样的指令。我们需要先取出余额然后在内存里乘以倍数,再将结果写回 Redis。这就会出现并发问题,因为有多个客户端会并发进行操作。我们可以通过 Redis 的分布式锁来避免冲突,这是一个很好的解决方案。 分布式锁是一种悲观锁,那是不是可以使用乐观锁的方式来解决冲突呢?Redis 提供了这种 watch 的机制,它就是一种乐观锁。有了 watch 我们又多了一种可以用来解决并发修改的方法。 watch 的使用方式如下:
while True:
do_watch()
commands()
multi()
send_commands()
try:
exec()
break
except WatchError:
continuewatch 会在事务开始之前盯住 1 个或多个关键变量,当事务执行时,也就是服务器收到了 exec 指令要顺序执行缓存的事务队列时, Redis 会检查关键变量自 watch 之后,是否被修改了 (包括当前事务所在的客户端)。如果关键变量被人动过了, exec 指令就会返回 null回复告知客户端事务执行失败,这个时候客户端一般会选择重试。
> watch books
OK
> incr books # 被修改了
(integer) 1
> multi
OK
> incr books
QUEUED
> exec # 事务执行失败
(nil)当服务器给 exec 指令返回一个 null 回复时,客户端知道了事务执行是失败的,通常客户端 (redis-py) 都会抛出一个 WatchError 这种错误,不过也有些语言 (jedis) 不会抛出异常,而是通过在 exec 方法里返回一个 null,这样客户端需要检查一下返回结果是否为 null来确定事务是否执行失败。
注意事项:Redis 禁止在 multi 和 exec 之间执行 watch 指令,而必须在 multi 之前做好盯住关键变量,否则会出错。
Redis——pubsub
前面我们讲了 Redis 消息队列的使用方法,但是没有提到 Redis 消息队列的不足之处,那就是它不支持消息的多播机制。
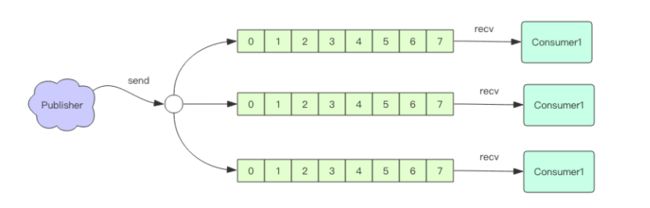
消息多播:
消息多播允许生产者生产一次消息,中间件负责将消息复制到多个消息队列,每个消息队列由相应的消费组进行消费。它是分布式系统常用的一种解耦方式,用于将多个消费组的逻辑进行拆分。支持了消息多播,多个消费组的逻辑就可以放到不同的子系统中。如果是普通的消息队列,就得将多个不同的消费组逻辑串接起来放在一个子系统中,进行连续消费。

PubSub
为了支持消息多播, Redis 不能再依赖于那 5 种基本数据类型了。它单独使用了一个模块来支持消息多播,这个模块的名字叫着 PubSub,也就是 PublisherSubscriber,发布者订阅者模型。我们使用 Python 语言来演示一下 PubSub 如何使用。
pybsub的缺点:PubSub 的生产者传递过来一个消息, Redis 会直接找到相应的消费者传递过去。如果一个消费者都没有,那么消息直接丢弃。如果开始有三个消费者,一个消费者突然挂掉了,生产者会继续发送消息,另外两个消费者可以持续收到消息。但是挂掉的消费者重新连上的时候,这断连期间生产者发送的消息,对于这个消费者来说就是彻底丢失了。如果 Redis 停机重启, PubSub 的消息是不会持久化的,毕竟 Redis 宕机就相当于一个消费者都没有,所有的消息直接被丢弃。正是因为 PubSub 有这些缺点,它几乎找不到合适的应用场景。所以 Redis 的作者单独开启了一个项目 Disque 专门用来做多播消息队列。该项目目前没有成熟,一直长期处于Beta 版本,但是相应的客户端 sdk 已经非常丰富了,就待 Redis 作者临门一脚发布一个Release 版本。
Redis——小对象压缩
Redis 是一个非常耗费内存的数据库,它所有的数据都放在内存里。如果我们不注意节约使用内存, Redis 就会因为我们的无节制使用出现内存不足而崩溃。 Redis 作者为了优化数据结构的内存占用,也苦心孤诣增加了非常多的优化点,这些优化也是以牺牲代码的可读性为代价的,但是毫无疑问这是非常值得的,尤其像 Redis 这种数据库。
Redis 如果使用 32bit 进行编译,内部所有数据结构所使用的指针空间占用会少一半,如果你对 Redis 使用内存不超过 4G,可以考虑使用 32bit 进行编译,可以节约大量内存。4G 的容量作为一些小型站点的缓存数据库是绰绰有余了,如果不足还可以通过增加实例的方式来解决。
小对象压缩存储 (ziplist)
如果 Redis 内部管理的集合数据结构很小,它会使用紧凑存储形式压缩存储。这就好比 HashMap 本来是二维结构,但是如果内部元素比较少,使用二维结构反而浪费空间,还不如使用一维数组进行存储,需要查找时,因为元素少进行遍历也很快,甚至可
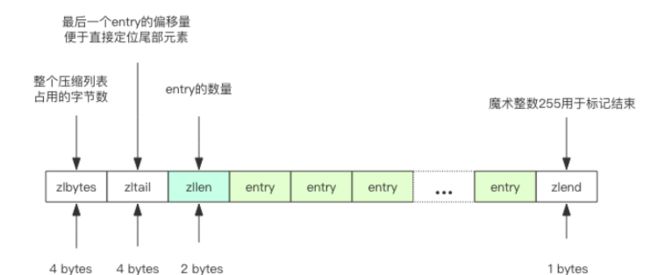
以比 HashMap 本身的查找还要快。比如下面我们可以使用数组来模拟 HashMap 的增删改操作。Redis 的 ziplist 是一个紧凑的字节数组结构,如下图所示,每个元素之间都是紧挨着的。我们不用过于关心 zlbytes/zltail 和 zlend 的含义,稍微了解一下就好
Redis 的 intset 是一个紧凑的整数数组结构,它用于存放元素都是整数的并且元素个数较少的 set 集合。
如果整数可以用 uint16 表示,那么 intset 的元素就是 16 位的数组,如果新加入的整数超过了 uint16 的表示范围,那么就使用 uint32 表示,如果新加入的元素超过了 uint32的表示范围,那么就使用 uint64 表示, Redis 支持 set 集合动态从 uint16 升级到 uint32,再升级到 uint64

内存回收机制:Redis 并不总是可以将空闲内存立即归还给操作系统。如果当前 Redis 内存有 10G,当你删除了 1GB 的 key 后,再去观察内存,你会发现内存变化不会太大。原因是操作系统回收内存是以页为单位,如果这个页上只要有一个 key还在使用,那么它就不能被回收。 Redis 虽然删除了 1GB 的 key,但是这些 key 分散到了很多页面中,每个页面都还有其它 key 存在,这就导致了内存不会立即被回收。不过,如果你执行 flushdb,然后再观察内存会发现内存确实被回收了。原因是所有的key 都干掉了,大部分之前使用的页面都完全干净了,会立即被操作系统回收。Redis 虽然无法保证立即回收已经删除的 key 的内存,但是它会重用那些尚未回收的空闲内存。这就好比电影院里虽然人走了,但是座位还在,下一波观众来了,直接坐就行。而
操作系统回收内存就好比把座位都给搬走了。
内存分配算法:内存分配是一个非常复杂的课题,需要适当的算法划分内存页,需要考虑内存碎片,需要平衡性能和效率。Redis 为了保持自身结构的简单性,在内存分配这里直接做了甩手掌柜,将内存分配的细节丢给了第三方内存分配库去实现。目前Redis 可以使用 jemalloc(facebook) 库来管理内存,也可以切换到 tcmalloc(google)。因为 jemalloc 相比 tcmalloc 的性能要稍好一些,所以Redis 默认使用了 jemalloc。
Redis的——主从同步
CAP 原理:CAP 原理就好比分布式领域的牛顿定律,它是分布式存储的理论基石。自打 CAP 的论文发表之后,分布式存储中间件犹如雨后春笋般一个一个涌现出来。理解这个原理其实很简单,本节我们首先对这个原理进行一些简单的讲解。
- C - Consistent , 一致性
- A - Availability , 可用性
- P - Partition tolerance , 分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫着「 网络分区」。在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点进行的修改操作将无法同步到另外一个节点,所以数据的「一致性」将无法满足,因为两个分布式节点的数据不再保持一致。除非我们牺牲「可用性」,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复正常再继续对外提供服务.
最终一致
Redis 的主从数据是异步同步的,所以分布式的 Redis 系统并不满足「 一致性」要求。当客户端在 Redis 的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务,所以 Redis 满足「 可用性」。Redis 保证「 最终一致性」,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态将保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,一旦网络恢复,从节点会采用多种策略努力追赶上落后的数据,继续尽力保持和主节点一致。
主从同步:Redis 同步支持主从同步和从从同步,从从同步功能是 Redis 后续版本增加的功能,为了减轻主库的同步负担。后面为了描述上的方便,统一理解为主从同步。

增量同步:Redis 同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一遍向主节点反馈自己同步到哪里了 (偏移量)。因为内存的 buffer 是有限的,所以 Redis 主库不能将所有的指令都记录在内存 buffer中。 Redis 的复制内存 buffer 是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当网络状况恢复时, Redis 的主节点中那些没有同步的指令在 buffer 中有可能已经被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更加复杂的同步机制 —— 快照同步。
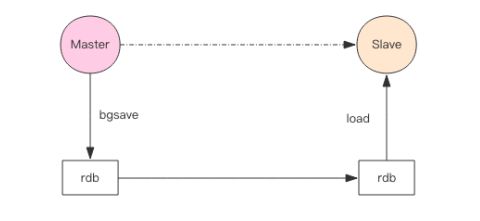
快照同步:快照同步是一个非常耗费资源的操作,它首先需要在主库上进行一次 bgsave 将当前内存的数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节点。从节点将快照文件接受完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空。加载完毕后通知主节点继续进行增量同步。在整个快照同步进行的过程中,主节点的复制 buffer 还在不停的往前移动,如果快照同步的时间过长或者复制 buffer 太小,都会导致同步期间的增量指令在复制 buffer 中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次发起快照同步,如此极有可能会陷入快照同步的死循环。所以务必配置一个合适的复制 buffer 大小参数,避免快照复制的死循环。
Redis——Sentinel
Redis 官方提供了这样一种方案 —— Redis Sentinel(哨兵)

我们可以将 Redis Sentinel 集群看成是一个 ZooKeeper 集群,它是集群高可用的心脏,它一般是由 3~5 个节点组成,这样挂了个别节点集群还可以正常运转。它负责持续监控主从节点的健康,当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 要地址, sentinel 会将最新的主节点地址告诉客户端。如此应用程序将无需重启即可自动完成节点切换。比如上图的主节点挂掉后,集群将可能自动调整为下图所示结构。
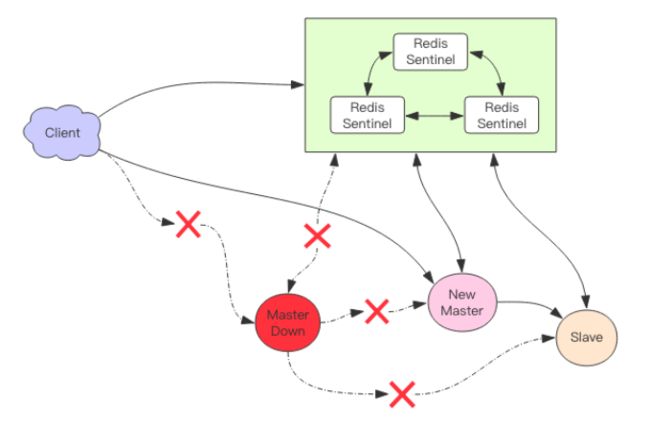
从这张图中我们能看到主节点挂掉了,原先的主从复制也断开了,客户端和损坏的主节点也断开了。从节点被提升为新的主节点,其它从节点开始和新的主节点建立复制关系。客户端通过新的主节点继续进行交互。 Sentinel 会持续监控已经挂掉了主节点,待它恢复后,集群会调整为下面这张图。
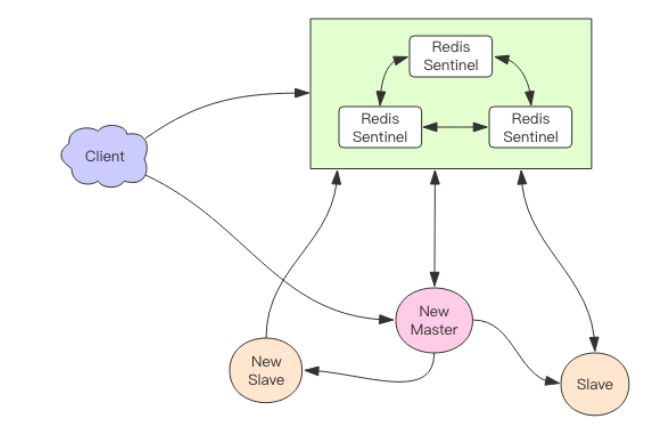
Redis 主从采用异步复制,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息就丢失了。如果主从延迟特别大,那么丢失的数据就可能会特别多。 Sentinel 无法保证消息完全不丢失,但是也尽可能保证消息少丢失。它有两个选项可以限制主从延迟过大。
Redis——cluster
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。

Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分的更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不需要另外的分布式存储来存储节点槽位信息。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
这点不同于 Codis, Codis 需要通过 Proxy 来定位目标节点, RedisCluster 是直接定位。客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。另外, RedisCluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
槽位定位算法:Cluster 默认会对 key 值使用 crc32 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。

跳转:当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。
迁移:Redis Cluster 提供了工具 redis-trib 可以让运维人员手动调整槽位的分配情况,它使用Ruby 语言进行开发,通过组合各种原生的 Redis Cluster 指令来实现。这点 Codis 做的更加人性化,它不但提供了 UI 界面可以让我们方便的迁移,还提供了自动化平衡槽位工具,无需人工干预就可以均衡集群负载。不过 Redis 官方向来的策略就是提供最小可用的工具,其都交由社区完成。
Redis 迁移的单位是槽, Redis 一个槽一个槽进行迁移,当一个槽正在迁移时,这个槽就处于中间过渡状态。这个槽在原节点的状态为 migrating,在目标节点的状态为 importing,表示数据正在从源流向目标。
迁移工具 redis-trib 首先会在源和目标节点设置好中间过渡状态,然后一次性获取源节点槽位的所有 key 列表(keysinslot 指令,可以部分获取),再挨个 key 进行迁移。每个 key的迁移过程是以原节点作为目标节点的「客户端」,原节点对当前的 key 执行dump 指令得到序列化内容,然后通过「客户端」向目标节点发送指令 restore 携带序列化的内容作为参数,目标节点再进行反序列化就可以将内容恢复到目标节点的内存中,然后返回「客户端」OK,原节点「客户端」收到后再把当前节点的 key 删除掉就完成了单个 key 迁移的整个过程。
从源节点获取内容 => 存到目标节点 => 从源节点删除内容。
注意这里的迁移过程是同步的,在目标节点执行 restore 指令到原节点删除 key 之间,原节点的主线程会处于阻塞状态,直到 key 被成功删除。如果迁移过程中突然出现网络故障,整个 slot 的迁移只进行了一半。这时两个节点依旧处于中间过渡状态。待下次迁移工具重新连上时,会提示用户继续进行迁移。在迁移过程中,如果每个 key 的内容都很小, migrate 指令执行会很快,它就并不会影响客户端的正常访问。如果 key 的内容很大,因为 migrate 指令是阻塞指令会同时导致原节点和目标节点卡顿,影响集群的稳定型。所以在集群环境下业务逻辑要尽可能避免大 key 的产生。
在迁移过程中,客户端访问的流程会有很大的变化。首先新旧两个节点对应的槽位都存在部分 key 数据。客户端先尝试访问旧节点,如果对应的数据还在旧节点里面,那么旧节点正常处理。如果对应的数据不在旧节点里面,那么有两种可能,要么该数据在新节点里,要么根本就不存在。旧节点不知道是哪种情况,所以它会向客户端返回一个-ASK targetNodeAddr 的重定向指令。客户端收到这个重定向指令后,先去目标节点执行一个不带任何参数的 asking 指令,然后在目标节点再重新执行原先的操作指令。
为什么需要执行一个不带参数的 asking 指令呢?
为在迁移没有完成之前,按理说这个槽位还是不归新节点管理的,如果这个时候向目标节点发送该槽位的指令,节点是不认的,它会向客户端返回一个-MOVED 重定向指令告诉它去源节点去执行。如此就会形成 重定向循环。 asking 指令的目标就是打开目标节点的选项,告诉它下一条指令不能不理,而要当成自己的槽位来处理。从以上过程可以看出,迁移是会影响服务效率的,同样的指令在正常情况下一个 ttl 就能完成,而在迁移中得 3 个 ttl 才能搞定。
容错:Redis Cluster 可以为每个主节点设置若干个从节点,单主节点故障时,集群会自动将其中某个从节点提升为主节点。如果某个主节点没有从节点,那么当它发生故障时,集群将完全处于不可用状态。不过 Redis 也提供了一个参数 cluster-require-full-coverage 可以允许部分节点故障,其它节点还可以继续提供对外访问。
网络抖动:真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。为解决这种问题, Redis Cluster 提供了一种选项 cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。还有另外一个选项 cluster-slave-validity-factor 作为倍乘系数来放大这个超时时间来宽松容错的紧急程度。如果这个系数为零,那么主从切换是不会抗拒网络抖动的。如果这个系数大于 1,它就成了主从切换的松弛系数。
可能下线 (PFAIL-Possibly Fail) 与确定下线 (Fail)
因为 Redis Cluster 是去中心化的,一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。所以集群还得经过一次协商的过程,只有当大多数节点都认定了某个节点失联了,集群才认为该节点需要进行主从切换来容错。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了(PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。