mmdetection环境配置以及自定义数据的训练与测试
1.简介
mmdetection是商汤科技(2018COCO目标检测挑战赛冠军)和香港中文大学开源的一个基于Pytorch实现的深度学习目标检测工具箱。
源码详情见GitHub
mmdetection支持多种主流目标检测方法和backbone:
| ResNet | ResNeXt | SENet | VGG | HRNet | |
|---|---|---|---|---|---|
| RPN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Fast R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Faster R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Mask R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Cascade R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Cascade Mask R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| SSD | ✗ | ✗ | ✗ | ✓ | ✗ |
| RetinaNet | ✓ | ✓ | ☐ | ✗ | ✓ |
| GHM | ✓ | ✓ | ☐ | ✗ | ✓ |
| Mask Scoring R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Double-Head R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Grid R-CNN (Plus) | ✓ | ✓ | ☐ | ✗ | ✓ |
| Hybrid Task Cascade | ✓ | ✓ | ☐ | ✗ | ✓ |
| Libra R-CNN | ✓ | ✓ | ☐ | ✗ | ✓ |
| Guided Anchoring | ✓ | ✓ | ☐ | ✗ | ✓ |
| FCOS | ✓ | ✓ | ☐ | ✗ | ✓ |
| RepPoints | ✓ | ✓ | ☐ | ✗ | ✓ |
| Foveabox | ✓ | ✓ | ☐ | ✗ | ✓ |
| FreeAnchor | ✓ | ✓ | ☐ | ✗ | ✓ |
| NAS-FPN | ✓ | ✓ | ☐ | ✗ | ✓ |
| ATSS | ✓ | ✓ | ☐ | ✗ | ✓ |
主要特征:
1)模块化设计:检测框架分解成不同的组件,通过组合不同的模块可以很容易地构建一个定制的目标检测框架
2)支持多个现成的框架:如Faster RCNN等
3)高效率:所有基本的bbox和mask都支持GPU,相较于Detectron2、SimpleDet等训练速度更快
4)State of the art

mmdetection的模型主要由以下4个部分构成:
①backbone:通常是一个全卷积网络如ResNet用于提取feature map
②neck:连接backbone和head的部分,如FPN
③head:用于特定任务如bbox预测,maskyuce等的模块
④ROI extractor:从feature map提取特征,如ROI Align、RoIPooling等
2.环境安装
①基础配置要求:
Ⅰ Linux或macOS
Ⅱ Python 3.6+
Ⅲ Pytorch 1.3+(旧版仓库支持1.1+,旧版仓库可从此clone)
Ⅳ CUDA9 9.2+
Ⅴ GCC 4.9+
Ⅵ mmcv
②容器建立
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
如果conda activate失败可以先退出bash容器再激活:
source activate
conda deactivate
conda activate open-mmlab
③安装mmdetection
1)装Pytorch:
conda install pytorch torchvision -c pytorch
如果下载慢可以先配置清华的镜像源添加链接描述,然后安装的时候不加-c pytorch
2)clone仓库
git clone https://github.com/open-mmlab/mmdetection.git
3)装mmdetection和必需配置
cd mmdetection
pip install -r requirements/build.txt
pip install "git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI"
pip install -v -e . # or "python setup.py develop"
3.转化自定义的数据集
这里以COCO格式数据为例
1)将数据集标注转化为coco格式
转化代码见此,提取码为297x
2)将生成的放在mmdetection目录下,目录路径如下:

推荐以软连接的方式创建data文件夹:
cd mmdetection
mkdir data
ln -s $COCO_ROOT data
4.修改cfg等配置
1)修改mmdetection/mmdet/datasets/coco.py,将CLASSES内类别修改为自己的类别,如
CLASSES = ('Car', 'Cat')
注意:如果只有一类的话,类别后面需加逗号,如:
CLASSES = ('person',)
2)修改mmdetection/mmdet/core/evaluation/class_names.py中coco_classes类别,如:
def coco_classes():
return [
'Cat', 'Car'
]
3)修改configs/faster_rcnn_r50_fpn_1x.py中
Ⅰ model字典中的num_classes:
num_classes=3,#类别数+1
Ⅱ data字典中的img_scale:
img_scale=(540,960), #输入图像尺寸的最大边与最小边(train、val、test这三处都要修改)
Ⅲ optimizer中的lr:
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
学习率的设定:默认的学习率是在8块GPU,每块GPU训练2张图片时为0.02,根据Linear Scaling Rule,1块GPU,每块GPU训练2张图片时lr=0.025
5.训练数据
1)以faster_rcnn_r50_fpn_1x.py配置为例:
python tools/train.py configs/faster_rcnn_r50_fpn_1x.py --gpus 1 --validate --work_dir work_dirs
可选参数:
–validate:每k个epoch进行评估,默认k为1
–work-dir:保存训练结果的路径
–resume-from:如果中断时可以用此参数继续训练,如–resume-from work_dirs/lastest.pth
2)训练输出如下:
3)训练输出以及设置的一些解释:
①epoch [1][150/20000]:1表示正在跑第几个epoch,20000是表示总共40000/2个训练次数,40000为图片总数,2为每个GPU训练两张图片
②
lr_config = dict(
policy='step',#优化策略
warmup='linear',#初始的学习率增加的策略,linear为线性增加,
warmup_iters=500,#在初始的500次迭代中学习率逐渐增加
warmup_ratio=1.0 / 3,#设置的起始学习率
step=[8, 11])#在第9 第10 和第11个epoch时降低学习率
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)#后面学习率稳定在0.025
③训练后的权重及log文件在之前设置的work_dirs里
checkpoint_config = dict(interval=1)#每一个epoch存储一次模型
6.验证模型泛化能力
1)
python3 tools/test.py configs/faster_rcnn_r50_fpn_1x.py work_dirs/epoch_12.pth --out ./result.pkl
2)测试输出如下:
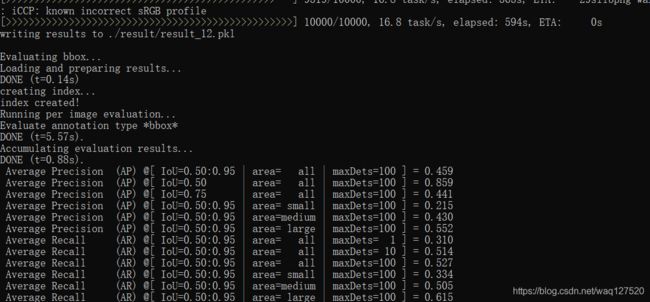
coco数据集格式化的检测评价矩阵定义如下:

7.自定义改进网络模型
1)如果想更换一些新的组件,如自定义backbone到模型中:
①新建backbone文件:mmdet/models/backbones/mobilenet.py
import torch.nn as nn
from ..registry import BACKBONES
@BACKBONES.register_module
class MobileNet(nn.Module):
def __init__(self, arg1, arg2):
pass
def forward(x): # should return a tuple
pass
def init_weights(self, pretrained=None):
pass
②在backbone初始化配置mmdet/models/backbones/init.py中导入模块
from .mobilenet import MobileNet
③更改配置文件
neck=dict(
#type='FPN'
type='PAFPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
2)要编写新的检测管道,需要继承BaseDetector。它定义了以下抽象方法:
extract_feat():给定图像批量形状(n,c,h,w),提取特征图。
forward_train():训练模式的前进方法。
simple_test():无需增强的单一规模测试。
aug_test():使用增强测试(多尺度,翻转)
8.分析训练日志
当我们需要分析训练结果时,能通过如绘制给定日志文件的loss/mAP曲线等来完成
1)装依赖项seaborn
pip install seaborn
2)依据对应需求输入指令
python tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
如分析分类损失时:
python tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
分析分类和回归损失并输出为pdf文件时:
python tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_reg --out losses.pdf
比较同一图中两次运行的bbox mAP时:
python tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
计算平均速度时:
python tools/analyze_logs.py cal_train_time ${CONFIG_FILE} [--include-outliers]
输出例如:
-----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
slowest epoch 11, average time is 1.2024
fastest epoch 1, average time is 1.1909
time std over epochs is 0.0028
average iter time: 1.1959 s/iter
9.评估模型
通过一个适用于flops-counter.pytorch的脚本,计算给定模型的浮点运算次数和参数大小:
python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
输出例如:
==============================
Input shape: (3, 1280, 800)
Flops: 206.66 GMac
Params: 41.13 M
==============================
参考文献:https://blog.csdn.net/gaoyi135/article/details/90613895
https://www.pythonheidong.com/blog/article/53032/