【论文阅读】Recurrent Back-Projection Network for Video Super-Resolution(RBPN)
文章目录
-
- RBPN
- abstract
- introduce
- VSR
- Recurrent Back-Projection Networks
-
- 网络结构
- Conclusion
好久没更新博客了,但是心念念着我这博客,不写感觉对不起自己最近涨的粉,/(ㄒoㄒ)/~~心情复杂。。。。。我最近看了好多文献,正在忙着做毕业设计的事。这是我读大学以来,写论文工作量最大的一次了,才发现数学建模的论文实在是太容易写了,不过也对,这都快毕业了,认真完成给我的大学画上圆满的句号!(捂脸.jpg),虽然我还有研究生要读,读书生涯尚未结束,仍需努力!!!废话说太多了,转入正题。今天要整理的是关于视频超分辨率的一篇文章。
RBPN
RBPN的前身是DBPN,其实RBPN就是专门为了处理视频超分而发的,DBPN是图像超分辨率。所以,我在整理RBPN的同时,顺便也把DBPN整理了。按照以往的套路,就按着文章结构写吧,省事儿~
abstract
文章提出了一种对于处理视频超分问题的新结构:使用循环encoder-decoder模块融合连续帧的时空信息,该结构可将多帧信息与目标帧融合在一起。 与大多数以前通过stack或warp将视频帧合并在一起的工作不同,在这个循环反向投影网络(RBPN) 模型中,是将每个上下文帧视为单独的信息源。 这些源组合在一个迭代细化框架中,该框架受多帧图像超分辨率中的反投影概念的启发。这得益于显式估计相对于目标帧的帧间运动,而不是显式作帧对齐。 所以,本文提出了一个新的视频超分辨率基准,可以进行更大范围的评估并考虑不同运动方式下的视频。
introduce
在传统的VSR方法中,使用CNN做超分的都是采用concatenate图像或者将视频帧送入RNN中,这些帧会与目标帧进行对齐(显式帧对齐),因此得到目标帧的运动矢量。但是,在VSR中,使用这种方法的效果是明显比不采用时间对齐的方法好,但这种方法会导致多张图像被同时处理,增强了训练的难度和计算量;而在RNN中,需要同时处理细微变化和明显变化是比较困难的。针对这样一个问题,作者就提出了循环反投影网络,反投影是图像重建领域的一种传统的方法,其细节我还没查阅,详细可查阅参考文献部分。使用反投影迭代地计算目标帧与其对应的邻帧的残差图,可作为重建的损失函数。多个残差图可以用来表示目标帧与其他帧之间细微的变化以及明显的变化,这弥补了RNN的不足。DBPN(Deep Back-Projection)是针对单帧图像进行超分,他通过多次上下采样的方式来细化生成的高分辨率图像的特征图。而RBPN整合了多帧输入以及DBPN,根据邻帧以及目标帧和邻帧之间的光流来学习残差。
文章的贡献:
- 整合SISR和MISR在一个VSR框架中:可迭代的SISR用于提取代表目标帧细节的特征图,MISR用于提供其他帧的特征图。
- 反投影模块:开发了一个编码器-解码器机制(encoder-decoder),合并通过反投影从SISR和MISR路径中提取的细节。
- 文章附录部分有彩蛋(哈哈哈,这里解决了我找不到训练集的问题)
VSR
基于深度学习的视频超分辨率的视频序列处理,主要分成三类:

a.送入网络前将视频帧concatenate起来,这种方法可看作是SISR的扩展方式直接应用到MISR,代表作有VSR-DUF网络[1];b.将不同数量的帧丢进网络分路,最后输出前concatenate起来,代表作有[2];c.视频帧迭代式地进入RNN,最后输出当前帧的重建结果,代表作有Bi-RNN,LSTM-layer和多对多RNN。
Recurrent Back-Projection Networks
网络结构

RBPN网络分为三部分:初始化特征提取(initial feature extraction)、多投影(multiple projection)和重建(reconstruction)
初始化特征提取 : 分为SISR和MISR两条路径,分别提取目标帧和其他帧(多个)的特征向量。
MISR路径:将第 I t I_t It和 I t − k I_{t-k} It−k帧及其光流 F t − k F_{t-k} Ft−k连接后,进行卷积得到8通道的特征张量 M t − k M_{t-k} Mt−k
SISR路径:第t帧 I t I_t It直接进行卷积得到特征张量 L t L_t Lt

图3:为多投影模块的结构。
多投影: RBPN的多投影部分使用了一个链式的encoder-decoder模块,具体结构如图3和图4
- 通过projection module将第k个M张量与第k-1个L张量进行投影,并输出第k个L张量和第k个高分辨率特征H张量;
- 第k个张量再一次输入到projection module中,然后结合第k+1个M张量,生成L和H
- Encoder:有两条输入路径,分别为SISR和MISR。这两条支路的特征输入到Encoder后,经由上采样得到高分辨率的特征张量 H t − n m H^m_{t-n} Ht−nm和 H t − n − 1 l H^l_{t-n-1} Ht−n−1l,求得残差后与SISR支路的高分特征张量 H t − n − 1 l H^l_{t-n-1} Ht−n−1l相加,得到Encoder的输出,一个高分辨率的特征张量 H t − n H_{t-n} Ht−n
- Decoder:接收Encoder的输出 H t − n H_{t-n} Ht−n,通过残差块(有shortcut的几个卷积层)下采样后,得到低分辨率张量 L t − n L_{t-n} Lt−n
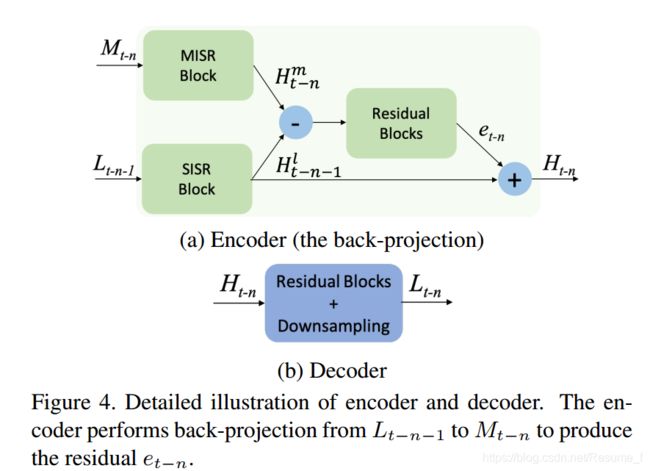
图4:为Encoder和Decoder的结构。encoder生产出一个估计HR特征的隐式状态 H t − n H_{t-n} Ht−n,而decoder接收 H t − n H_{t-n} Ht−n作为输入。
整个过程,使用数学语言进行描述如下:
Encoder: H t − n = N e t E ( L t − n − 1 , M t − n ; θ E ) H_{t-n}=Net_E(L_{t-n-1}, M_{t-n}; \theta_E) Ht−n=NetE(Lt−n−1,Mt−n;θE) (1)
Decoder: L t − n = N e t D ( H t − n ; θ D ) L_{t-n}=Net_D(H_{t-n}; \theta_D) Lt−n=NetD(Ht−n;θD) (2)
这个encoder模块 N e t E Net_E NetE被定义为如下:
SISR 上采样: H t − n − 1 l = N e t s i s r ( L t − n − 1 ; θ s i s r ) H^l_{t-n-1}=Net_{sisr}(L_{t-n-1}; \theta_{sisr}) Ht−n−1l=Netsisr(Lt−n−1;θsisr) (3)
MISR 上采样: H t − n m = N e t m i s r ( M t − n ; θ m i s r ) H^m_{t-n}=Net_{misr}(M_{t-n}; \theta_{misr}) Ht−nm=Netmisr(Mt−n;θmisr) (4)
残差部分: e t − n = N e t r e s ( H t − n − 1 l − H t − n m ; θ r e s ) e_{t-n}=Net_{res}(H^l_{t-n-1}-H^m_{t-n}; \theta_{res}) et−n=Netres(Ht−n−1l−Ht−nm;θres)(5)
输出部分: H t − n = H t − n − 1 l + e t − n H_{t-n}=H^l_{t-n-1}+e_{t-n} Ht−n=Ht−n−1l+et−n(6)
在代码实现部分,上述的 N e t D Net_D NetD, N e t m i s r Net_{misr} Netmisr和 N e t r e s Net_{res} Netres都是ResNet结构, N e t s i s r Net_{sisr} Netsisr是DBPN结构。
重建: 最后,将所有帧的HR特征图连接后送入一个卷积层得到最终的输出。
到这里,RBPN和DBPN的结构都介绍完了,最后放上RBPN网络的每一部分的操作的插图,就可以对RBPN网络中的每个结构的操作都一目了然。

这里,略微简单地描述一下DBPN网络的结构,先上图:

DBPN主要是采用交替式上下投影(Up-projection,Down-projection)的方式来进行残差学习,图像通过上下投影单元最终会输出一个高分或者低分的特征向量。其中上投影单元和下投影单元的结构如上图,具体结构,只能用公式(截图)来表示了:


Conclusion
最后,我简单总结一下,RBPN采用了多路径学习的方式,通过对目标帧的单帧超分和其他帧的多帧融合超分,来细化目标帧的细节信息,同时该网络也嵌入了一种光流算法[在原文参考文献23]。目前超分辨领域存在一种认识就是,使用光流算法做运动估计不太靠谱,不仅增加了网络复杂的,还拖慢了计算,最重要的是运动估计不准确就直接影响整个重建的结果,所以不推荐使用光流算法。总结完整篇文章之后,我最大的泪点是网络结构真的炒鸡炒鸡庞大,我那弱鸡的电脑配置根本跑不起这源码。呜呜呜/(ㄒoㄒ)/~~(哭嘤嘤…),谁能明白我搞懂了这文章后,却不能跑源码的心塞。其实还是我电脑配置问题,太低了,好穷,配不起高配置电脑,只能等存够我的奖学金再来买电脑了。。。
最后附上这文章的地址:
DBPN-https://arxiv.org/abs/1803.02735
RBPN-https://arxiv.org/abs/1903.10128v1
同样,如果文章对你有帮助,那你点个赞,鼓励一下我这个程序媛!本文是原创作品,转载需要注明出处!谢谢啦!完成一篇博文真开心,虽然写的时间有些匆忙,如果哪里写的不对,请指出,我会及时修改的!