Pytorch修改预训练模型的方法汇总
本文包括如何修改预训练模型的示例。常见的有四种不同程度的修改:
1、只修改输入输出的类别数,即某些网络层的参数(常见的是修改通道数)
2、替换整个backbone或预训练模型的某一部分
3、修改网络中间层的结构(最重要,一般是重写部分中间层再整体替换)
4、快速去除预训练模型本身的网络层并添加新的层
正文如下
1. 只修改输入输出的类别数,即某些网络层的参数(常见的是修改通道数)
#1、只修改输入输出的类别数,即某些网络层的参数(常见的是修改通道数)
model = torchvision.models.resnet50(pretrained=True)
# 修改最后线性层的输出通道数
model.fc = nn.Linear(2048,10)
print(model.fc)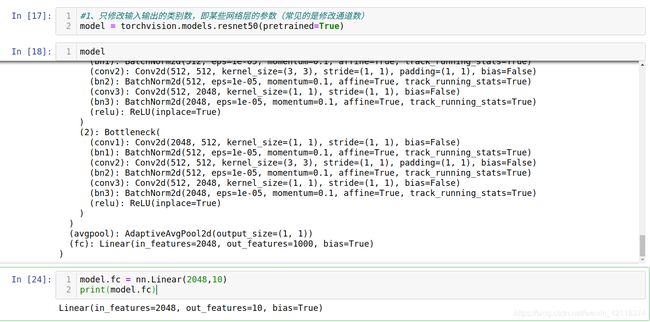
2. 替换整个backbone或预训练模型的某一部分
#2、替换整个backbone或预训练模型的某一部分
#以下是替换骨干网的示例
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 先加载一个预训练模型的特征
# only the features:其实就是不包含最后的classifier的两层
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# 需要知道backbone的输出通道数,这样才能在替换时保证通道数的一致性
backbone.out_channels = 1280
# 设置RPN的anchor生成器,下面的anchor_generator可以在每个空间位置生成5x3的anchors,即5个不同尺寸×3个不同的比例
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 定义roipool模块
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# 将以上模块集成到FasterRCNN中
model = FasterRCNN(backbone,
num_classes=4,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)3. 修改模型网络中间层的结构(最重要,一般是重写部分中间层再整体替换)
#3、修改网络中间层的结构(最重要,一般是重写部分中间层再整体替换)
#以下是在ResNet50的基础上修改的,大部分是复制的源码,但后面新增+修改了一些层
class CNN(nn.Module):
def __init__(self, block, layers, num_classes=9):
self.inplanes = 64
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
#新增一个反卷积层
self.convtranspose1 = nn.ConvTranspose2d(2048, 2048, kernel_size=3, stride=1, padding=1, output_padding=0, groups=1, bias=False, dilation=1)
#新增一个最大池化层
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#去掉原来的fc层,新增一个fclass层
self.fclass = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#新加层的forward
x = x.view(x.size(0), -1)
x = self.convtranspose1(x)
x = self.maxpool2(x)
x = x.view(x.size(0), -1)
x = self.fclass(x)
return x
#加载model
resnet50 = torchvision.models.resnet50(pretrained=True)
cnn = CNN(Bottleneck, [3, 4, 6, 3])
#读取参数
pretrained_dict = resnet50.state_dict()
model_dict = cnn.state_dict()
# 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
cnn.load_state_dict(model_dict)
# print(resnet50)
print(cnn)
4. 快速去除预训练模型本身的网络层并添加新的层
#4、快速去除预训练模型本身的网络层并添加新的层
#先将模型的网络层列表化,每一层对应列表一个元素,bottleneck对应一个序列层
net_structure = list(model.children())
print(net_structure)
#去除最后两层得到新的网络
resnet_modified = nn.Sequential(*net_structure[:-2])
#去除后两层后构建新网络
class Net(nn.Module):
def __init__(self , model):
super(Net, self).__init__()
#取掉model的后两层
self.resnet_layer = nn.Sequential(*list(model.children())[:-2])
self.transion_layer = nn.ConvTranspose2d(2048, 2048, kernel_size=14, stride=3)
self.pool_layer = nn.MaxPool2d(32)
self.Linear_layer = nn.Linear(2048, 8)
def forward(self, x):
x = self.resnet_layer(x)
x = self.transion_layer(x)
x = self.pool_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x