白话空间统计之二十五:空间权重矩阵(四)R语言中的空间权重矩阵(2)
上一篇,讲了R语言中的空间权重矩阵的结构,这一节讲讲R语言里面空间权重矩阵的自定义。
与ArcGIS自定义空间权重矩阵一样,R语言的空间权重矩阵如果纯粹从零开始自定义生成,是非常麻烦的事情,所以我们一般先做一个默认的空间关系对象,然后再进行修改。这种方式,用牛爵爷的话来说,叫做“踩在巨人的肩膀上”(当年,牛爵爷说这句话的时候,绝对不是谦虚,而是说:你们就算是巨人,也得老老实实被我踩在脚下)——

言归正传,下面我们来自定义一个空间权重矩阵,还是用中国,但是我按照中国七大区域划分方法:

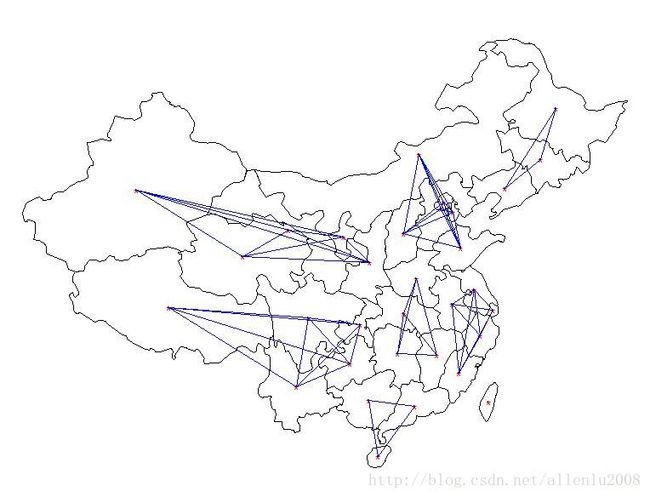
下面我们来用不同空间权重矩阵,来计算一下中国2009年各省gdp的莫兰指数,绘图如下:

首先用默认的共点共边,来计算一下:

莫兰指数为 0.2643,表示 空间正相关, p值为0.004, 拒绝了零假设, z得分为2.65,表现为显著。
然后下面用自定义七大区域的空间权重矩阵来进行计算:

P值为0.22,无法拒绝零假设——
那么结果表示,如果中国按照区域来进行划分,各区域内的GDP(起码2009年)体量 呈现随机均衡的发展情况。即每个区域内,都有很强的的省,也有很弱的省,强弱的分布比较均匀,GDP强省和GDP弱省 出现的概率是一样。
那么我简单修改一下我的空间权重矩阵,进行一下优化组合,比如从华东把安徽移掉,把广东、山东加入到华东区域, 人为的造就一个超级富有的区域:
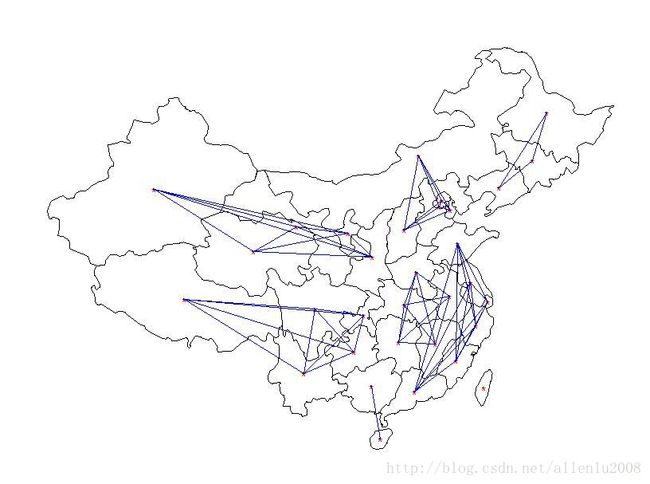
再次进行莫兰指数的计算:
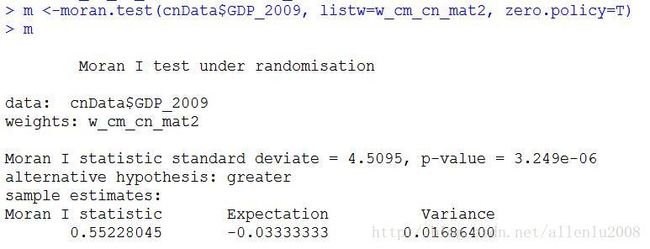
p值小于0.001,z得分大于4,拒绝零假设且非常显著的出现了聚集。
莫兰指数为0.552,表示高度的空间自相关。
这种划分,表示了如果将中国区域划分为沿海发达经济区、中部和西北欠发达区域的话,GDP的表现出现了 高度的聚集(发达地区和发达地区在空间上出现聚集,欠发达和欠发达地区空间聚集)表现 高度的空间自相关性,表示了划分上面的严重不均衡。
最后总结:
1、从上面几个例子可以看出,利用不同的空间关系进行计算,得到的结果是完全不一样的,所以在进行空间分析的时候,需要选定好不同的空间关系——没有最好,只有最合适。
2、R语言对空间权重矩阵的自定义,可以通过修改临近对象集合来实现。R语言是明码标识,易读易写。
下一篇,我们将介绍其他几种空间关系定义方法在R语言里面怎么定义。
(待续未完)。
与ArcGIS自定义空间权重矩阵一样,R语言的空间权重矩阵如果纯粹从零开始自定义生成,是非常麻烦的事情,所以我们一般先做一个默认的空间关系对象,然后再进行修改。这种方式,用牛爵爷的话来说,叫做“踩在巨人的肩膀上”(当年,牛爵爷说这句话的时候,绝对不是谦虚,而是说:你们就算是巨人,也得老老实实被我踩在脚下)——
言归正传,下面我们来自定义一个空间权重矩阵,还是用中国,但是我按照中国七大区域划分方法:
代码如下:
#东北
db <- c("吉林","辽宁","黑龙江")
#华北
hb <-c("内蒙古","北京","天津","河北","山东","山西")
#华中
hz <- c("河南","湖北","湖南","江西")
#华东
hd <- c("安徽","江苏","上海","福建","浙江")
#华南
hn <- c("广东","广西","海南")
#西南
xn <- c("贵州","云南","四川","重庆","西藏")
#西北
xb <- c("陕西","青海","甘肃","宁夏","新疆")
#进行自定义临近关系
w_cm_cn <- w_cn
ccn <-list(db,hb,hz,hd,hn,xn,xb)
for(area in ccn){
for(i in area){
i_id <-which(cnData$FIRST_NAME == as.character(i))
temp<-c()
for (j in area){
j_id <-which(cnData$FIRST_NAME == as.character(j))
if(i_id != j_id){
temp <- c(temp,as.integer(j_id))
}
}
w_cm_cn[[i_id]] <- temp
}
}
#绘制自定义的临近关系
w_cm_cn_mat <- nb2listw(w_cm_cn, style="W", zero.policy=TRUE)
plot(cnData)
points(map_crd,col='red',pch='*')
plot(w_cm_cn_mat,coords=map_crd, cex=0.1, col="blue", add=T)
下面我们来用不同空间权重矩阵,来计算一下中国2009年各省gdp的莫兰指数,绘图如下:
mycolors <- colorRampPalette(c("darkgreen", "yellow", "orangered"))(32)
spplot(cnData, zcol="GDP_2009", col.regions=mycolors, main="中国2009年各省GDP")首先用默认的共点共边,来计算一下:
莫兰指数为 0.2643,表示 空间正相关, p值为0.004, 拒绝了零假设, z得分为2.65,表现为显著。
然后下面用自定义七大区域的空间权重矩阵来进行计算:
P值为0.22,无法拒绝零假设——
那么结果表示,如果中国按照区域来进行划分,各区域内的GDP(起码2009年)体量 呈现随机均衡的发展情况。即每个区域内,都有很强的的省,也有很弱的省,强弱的分布比较均匀,GDP强省和GDP弱省 出现的概率是一样。
那么我简单修改一下我的空间权重矩阵,进行一下优化组合,比如从华东把安徽移掉,把广东、山东加入到华东区域, 人为的造就一个超级富有的区域:
#############################################
# 自定义七大区域划分:制造东部沿海发达区域 #
#############################################
#东北
db <- c("吉林","辽宁","黑龙江")
#华北
hb <-c("内蒙古","北京","天津","河北","山西")
#华中
hz <- c("河南","湖北","湖南","江西","安徽")
#华东(人为制造华东为东部沿海发达区域)
hd <- c("江苏","上海","福建","浙江","山东","广东")
#华南
hn <- c("广西","海南")
#西南
xn <- c("贵州","云南","四川","重庆","西藏")
#西北
xb <- c("陕西","青海","甘肃","宁夏","新疆")
再次进行莫兰指数的计算:
p值小于0.001,z得分大于4,拒绝零假设且非常显著的出现了聚集。
莫兰指数为0.552,表示高度的空间自相关。
这种划分,表示了如果将中国区域划分为沿海发达经济区、中部和西北欠发达区域的话,GDP的表现出现了 高度的聚集(发达地区和发达地区在空间上出现聚集,欠发达和欠发达地区空间聚集)表现 高度的空间自相关性,表示了划分上面的严重不均衡。
最后总结:
1、从上面几个例子可以看出,利用不同的空间关系进行计算,得到的结果是完全不一样的,所以在进行空间分析的时候,需要选定好不同的空间关系——没有最好,只有最合适。
2、R语言对空间权重矩阵的自定义,可以通过修改临近对象集合来实现。R语言是明码标识,易读易写。
下一篇,我们将介绍其他几种空间关系定义方法在R语言里面怎么定义。
(待续未完)。