关于零拷贝的一些理解
关于零拷贝的一些理解
零拷贝
"零拷贝"中的"拷贝"是操作系统在I/O操作中,将数据从一个内存区域复制到另外一个内存区域. 而"零"并不是指0次复制, 更多的是指在用户态和内核态之前的复制是0次.
CPU COPY
通过计算机的组成原理我们知道, 内存的读写操作是需要CPU的协调数据总线,地址总线和控制总线来完成的
因此在"拷贝"发生的时候,往往需要CPU暂停现有的处理逻辑,来协助内存的读写.这种我们称为CPU COPY
cpu copy不但占用了CPU资源,还占用了总线的带宽.
DMA COPY
DMA(DIRECT MEMORY ACCESS)是现代计算机的重要功能. 它的一个重要 的特点就是, 当需要与外设进行数据交换时, CPU只需要初始化这个动作便可以继续执行其他指令,剩下的数据传输的动作完全由DMA来完成
可以看到DMA COPY是可以避免大量的CPU中断的
上下文切换
本文中的上下文切换时指由用户态切换到内核态, 以及由内核态切换到用户态
存在多次拷贝的原因
1.操作系统为了保护系统不被应用程序有意或无意地破坏,为操作系统设置了用户态和内核态两种状态.用户态想要获取系统资源(例如访问硬盘), 必须通过系统调用进入到内核态, 由内核态获取到系统资源,再切换回用户态返回应用程序.
2.出于"readahead cache"和异步写入等等性能优化的需要, 操作系统在内核态中也增加了一个"内核缓冲区"(kernel buffer). 读取数据时并不是直接把数据读取到应用程序的buffer, 而先读取到kernel buffer, 再由kernel buffer复制到应用程序的buffer. 因此,数据在被应用程序使用之前,可能需要被多次拷贝
都有哪些不必要的拷贝
再回答这个问题之前, 我们先来看一个应用场景
回想现实世界的所有系统中, 不管是web应用服务器, ftp服务器,数据库服务器, 静态文件服务器等等, 所有涉及到数据传输的场景, 无非就一种:
从硬盘上读取文件数据, 发送到网络上去.
这个场景我们简化为一个模型:
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
为了方便描述,上面这两行代码, 我们给它起个名字: read-send模型
操作系统在实现这个read-send模型时,需要有以下步骤:
- 应用程序开始读文件的操作
- 应用程序发起系统调用, 从用户态切换到内核态(第一次上下文切换)
- 内核态中把数据从硬盘文件读取到内核中间缓冲区(kernel buf)
- 数据从内核中间缓冲区(kernel buf)复制到(用户态)应用程序缓冲区(app buf),从内核态切换回到用户态(第二次上下文切换)
- 应用程序开始发送数据到网络上
- 应用程序发起系统调用,从用户态切换到内核态(第三次上下文切换)
- 内核中把数据从应用程序(app buf)的缓冲区复制到socket的缓冲区(socket)
- 内核中再把数据从socket的缓冲区(socket buf)发送的网卡的缓冲区(NIC buf)上
- 从内核态切换回到用户态(第四次上下文切换)
如下图表示:
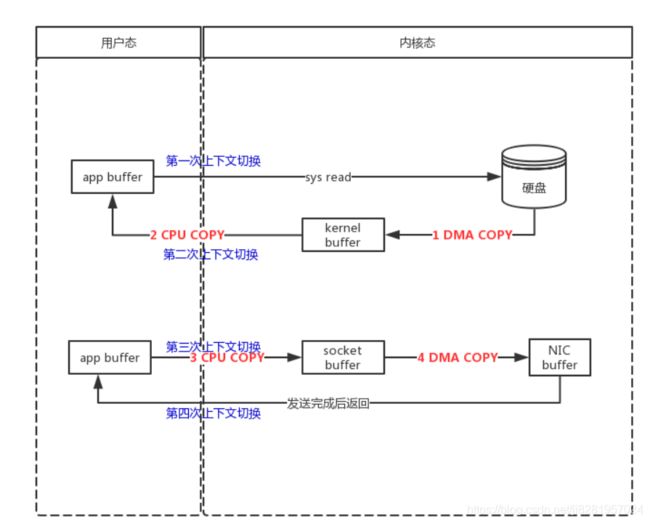
由上图可以很清晰地看到, 一次read-send涉及到了四次拷贝:
10. 硬盘拷贝到内核缓冲区(DMA COPY)
11. 内核缓冲区拷贝到应用程序缓冲区(CPU COPY)
12. 应用程序缓冲区拷贝到socket缓冲区(CPU COPY)
13. socket buf拷贝到网卡的buf(DMA COPY)
其中涉及到2次cpu中断, 还有4次的上下文切换
很明显,第2次和第3次的的copy只是把数据复制到app buffer又原封不动的复制回来, 为此带来了两次的cpu copy和两次上下文切换, 是完全没有必要的
linux的零拷贝技术就是为了优化掉这两次不必要的拷贝
sendFile
linux内核2.1开始引入一个叫sendFile系统调用,这个系统调用可以在内核态内把数据从内核缓冲区直接复制到套接字(SOCKET)缓冲区内, 从而可以减少上下文的切换和不必要数据的复制
这个系统调用其实就是一个高级I/O函数, 函数签名如下:
#include
ssize_t senfile(int out_fd,int in_fd,off_t* offset,size_t count);
1. out_fd是写出的文件描述符,而且必须是一个socket
2. in_fd是读取内容的文件描述符,必须是一个真实的文件, 不能是管道或socket
3. offset是开始读的位置
4. count是将要读取的字节数
有了sendFile这个系统调用后, 我们read-send模型就可以简化为:
- 应用程序开始读文件的操作
- 应用程序发起系统调用, 从用户态切换到内核态(第一次上下文切换)
- 内核态中把数据从硬盘文件读取到内核中间缓冲区
- 通过sendFile,在内核态中把数据从内核缓冲区复制到socket的缓冲区
- 内核中再把数据从socket的缓冲区发送的网卡的buf上
- 从内核态切换到用户态(第二次上下文切换)
如下图所示:
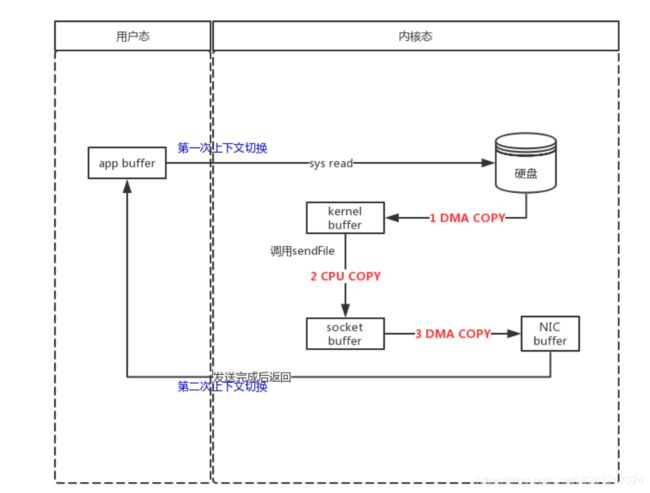
涉及到数据拷贝变成:
11. 硬盘拷贝到内核缓冲区(DMA COPY)
12. 内核缓冲区拷贝到socket缓冲区(CPU COPY)
13. socket缓冲区拷贝到网卡的buf(DMA COPY)
可以看到,一次read-send模型中, 利用sendFile系统调用后, 可以将4次数据拷贝减少到3次, 4次上下文切换减少到2次, 2次CPU中断减少到1次
相对传统I/O, 这种零拷贝技术通过减少两次上下文切换, 1次cpu copy, 可以将I/O性能提高50%以上(网络数据, 未亲测)
开始的术语中说到, 所谓的零拷贝的"零", 是指用户态和内核态之间的拷贝次数为0, 从这个定义上来说, 现在的这个零拷贝技术已经是真正的"零"了
然而, 对性能追求极致的伟大的科学家和工程师们并不满足于此. 精益求精的他们对中间第2次的cpu copy依旧耿耿于怀, 想尽千方百计要去掉这一次没有必要的数据拷贝和CPU中断
支持scatter-gather特性的sendFile
在内核2.4以后的版本中, linux内核对socket缓冲区描述符做了优化. 通过这次优化, sendFile系统调用可以在只复制kernel buffer的少量元信息的基础上, 把数据直接从kernel buffer 复制到网卡的buffer中去.从而避免了从"内核缓冲区"拷贝到"socket缓冲区"的这一次拷贝.
这个优化后的sendFile, 我们称之为支持scatter-gather特性的sendFile
在支持scatter-gather特性的sendFile的支撑下, 我们的read-send模型可以优化为:
- 应用程序开始读文件的操作
- 应用程序发起系统调用, 从用户态进入到内核态(第一次上下文切换)
- 内核态中把数据从硬盘文件读取到内核中间缓冲区
- 内核态中把数据在内核缓冲区的位置(offset)和数据大小(size)两个信息追加(append)到socket的缓冲区中去
- 网卡的buf上根据socekt缓冲区的offset和size从内核缓冲区中直接拷贝数据
- 从内核态返回到用户态(第二次上下文切换)
这个过程如下图所示:

最后数据拷贝变成只有两次DMA COPY:
- 硬盘拷贝到内核缓冲区(DMA COPY)
- 内核缓冲区拷贝到网卡的buf(DMA COPY)
完美
mmap和sendFile
MMAP(内存映射文件), 是指将文件映射到进程的地址空间去, 实现硬盘上的物理地址跟进程空间的虚拟地址的一一对应关系.
MMAP是另外一个用于实现零拷贝的系统调用.跟sendFile不一样的地方是, 它是利用共享内存空间的方式, 避免app buf和kernel buf之间的数据拷贝(两个buf共享同一段内存)
mmap相对于sendFile的好处:
多个进程访问同一个文件时, 可以节省大量内存.
由于数据在内核中直接发送到网络上, 用户态中的应用程序无法再次操作数据.
mmap相对于sendFile的缺点:
当内存映射一个文件,然后调用write,而另一个进程截断同一个文件,可能被总线错误信号SIGBUS中断, 这个信号的默认行为是kill掉进程和dump core.这个是一般服务器不能接受的
连续顺序访问小文件时,不如sendFile的readahead cahce高效
netty的真正零拷贝
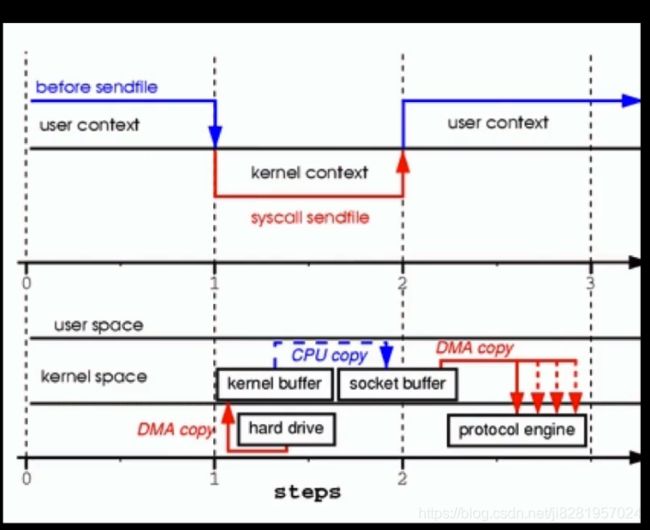
用户将磁盘上的文件读取到kernel buffer中拷贝一次。而socket buffer 不会进行拷贝,只是把文件描述符放到socket buffer中。protocol engine(协议引擎)会根据socket buffer中的文件地址会取到文件。将文件发送到服务器端
文件描述符:有两方面1.文件的对应的文件地址。2.文件的大小
参考 : https://www.cnblogs.com/lhh-north/p/11031821.html