整理了一下最近对协同过滤推荐算法中的皮尔森相似度计算,顺带学习了下R语言的简单使用,也复习了概率统计知识。
一、概率论和统计学概念复习
1)期望值(Expected Value)
因为这里每个数都是等概率的,所以就当做是数组或向量中所有元素的平均数吧。可以使用R语言中函数mean()。
2)方差(Variance)
方差分为population variance总体方差和sample variance样本方差,区别是总体方差除以N,样本方差除以N-1。
数理统计中常用样本方差,R语言的var()函数计算的也是样本方差。具体原因是样本方差是无偏的(Unbiased),想刨根问底可以Google一下。
3)标准差(Standard Variance)
很简单,标准差就是方差的平方根。R语言中函数为sd()。
4)协方差(Covariance)
也分成总体协方差和样本协方差,区别同上。R语言中函数为cov()。注意向量中有空元素(NA)时,例如稀疏矩阵中的一行,则要cov(x,y, use='complete')。
方差也可以看做是协方差的特例,也就是:var(x)=cov(x,x)。
这里只列举了计算公式,看着有些头晕,具体还是看下面例子吧,一看就懂了。
二、相似度计算在协同过滤推荐算法中的地位
在协同过滤推荐算法中,不管是基于用户(User-based)还是基于物品(Item-based),都要通过计算用户或物品间的相似度,得到离线模型(训练学习过程)。
之后再利用排序和加权算法得到最终的推荐物品Top-N列表。不同相似度算法的选择对最终推荐结果会产生很大的影响。
1)余弦相似度(Cosine-based Similiarity)
2)相关性相似度(Correlation-based Similiarity)
这种相似度计算使用的算法就是皮尔森。
3)修正余弦相似度(Adjusted Cosine-based Similiarity)
三、R语言入门简介
Windows下的R语言安装包地址为: http://cran.r-project.org/bin/windows/base/
下载exe后直接安装后,运行交互控制台就可以使用了。
常用的函数都可以从网上中查找到: http://jiaoyan.org/r/?page_id=4100
要习惯的一点是,R语言的表达方式,例如在控制台输入:
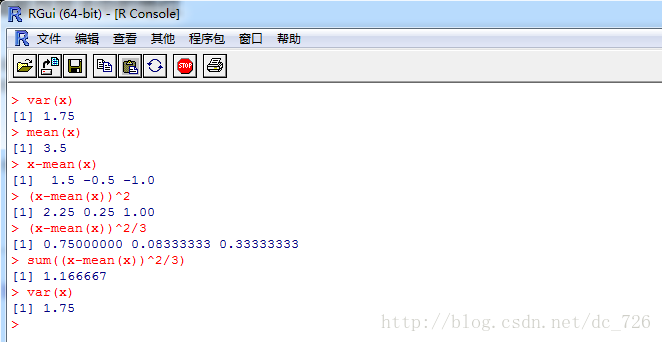
> x<-c(1:10)
> x-mean(x)
[1] -4.5 -3.5 -2.5 -1.5 -0.5 0.5 1.5 2.5 3.5 4.5
[1] -4.5 -3.5 -2.5 -1.5 -0.5 0.5 1.5 2.5 3.5 4.5
x-mean(x)的含义是都向量x中每个元素都减去x的平均数mean(x),可以说这种表达方式高度抽象化,表现力很强。
之后我们可以用其他函数对计算结果进行聚合:
> sum(x-mean(x))
[1] 0
四、皮尔森相似度(Pearson Similiarity)计算举例
下面以另一篇文章中的用户-物品关系为例,说明一下皮尔森相似度的计算过程。
皮尔森相似度的原始计算公式为:  ,不继续展开化简。
,不继续展开化简。
1)定义用户数组(向量)
user1<-c(5.0, 3.0, 2.5)
user5<-c(4.0, 3.0, 2.0)
2)计算方差
var(user1)=sum((user1-mean(user1))^2)/(3-1)=1.75
var(user2)=sum((user5-mean(user5))^2)/(3-1)=1
3)计算标准差
sd(user1)=sqrt(var(user1))=1.322876
sd(user5)=sqrt(var(user5))=1
4)计算协方差
cov(user1, user5)
=sum((user1-mean(user1))*(user5-mean(user5)))/(3-1)
=1.25
5)计算相似度
cor(user1, user5)
=cov(user1, user5) / (sd(user1)*(sd(user5)))
=0.9449112
五、数学特性和存在问题
以下1)和2)整理自维基百科:
1)代数特性
皮尔逊相关系数的变化范围为-1到1。 系数的值为1意味着X 和 Y可以很好的由直线方程来描述,所有的数据点都很好的落在一条 直线上,且 Y 随着 X 的增加而增加。
系数的值为−1意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。系数的值为0意味着两个变量之间没有线性关系。
因两个变量的位置和尺度的变化并不会引起该系数的改变,即它该变化的不变量 (由符号确定)。也就是说,我们如果把X移动到a + bX和把Y移动到c + dY,其中a、b、c和d是常数,
并不会改变两个变量的相关系数(该结论在总体和样本皮尔逊相关系数中都成立)。我们发现更一般的线性变换则会改变相关系数。
2)几何学含义
对于没有中心化的数据, 相关系数与两条可能的回归线y=gx(x) 和 x=gy(y) 夹角的余弦值一致。
对于中心化过的数据 (也就是说, 数据移动一个样本平均值以使其均值为0), 相关系数也可以被视作由两个随机变量 向量 夹角theta 的余弦值(见下方)。
对于中心化过的数据 (也就是说, 数据移动一个样本平均值以使其均值为0), 相关系数也可以被视作由两个随机变量 向量 夹角theta 的余弦值(见下方)。

3)存在问题
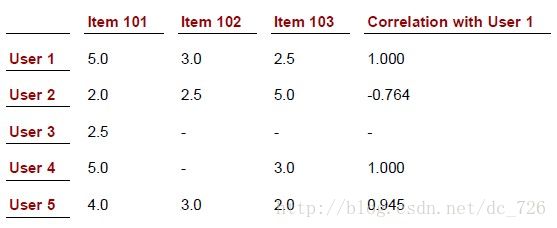
这也就是为什么会导致User1和User4更为相似的原因了,尽管User4只对Item101和103评分,但是这两个评分形成的直线与User1形成的直线趋势更为接近。
同时另一个问题是,如果一些几何变换不会影响相关系数,则评分的高低也被忽略掉了,只是分数的趋势会影响。当然这对于矩阵中都是0和1的用户-物品购买矩阵没有什么影响。