CornerNet代码学习之pytorch多线程
Cornernet代码之pytorch多线程学习
- 源码剖析
- main()
- train()
- 页锁定内存
- 守护线程
- init_parallel_jobs()、pin_memory()
- 信号量
- 附录-源码内容
源码剖析
这代码太长了,真他娘的不想看。为了多线程,还是老老实实从main()读起。
main()
在main()里面,其实只需要看
training_dbs = [datasets[dataset](config["db"], split=train_split, sys_config=system_config) for _ in range(workers)]
validation_db = datasets[dataset](config["db"], split=val_split, sys_config=system_config)
train(training_dbs, validation_db, system_config, model, args)
在这里,datasets是一个字典{"COCO": COCO},datasets[dataset]实际上是COCO类,里面是一些数据集的准备操作。因此training_dbs和validation_db是两个COCO类对象。
train()
在train()中,有关训练集和验证集的操作相似,因此只对训练集进行分析。有关训练集操作的代码整理如下:
training_queue = Queue(system_config.prefetch_size)# 该队列存放原始训练数据
pinned_training_queue = queue.Queue(system_config.prefetch_size)# 该队列存放存在页锁定内存中的训练数据
# 初始化len(dbs)个Process,每个Process读取原始训练数据并将其放入training_queue
training_tasks = init_parallel_jobs(system_config, training_dbs, training_queue, data_sampling_func, True)
# 初始化一个threading,将原始训练数据放入页锁定内存并将其送进pinned_training_queue
training_pin_semaphore = threading.Semaphore()# 信号量,value=1
training_pin_semaphore.acquire()# 信号量value-1
training_pin_args = (training_queue, pinned_training_queue, training_pin_semaphore)
training_pin_thread = threading.Thread(target=pin_memory, args=training_pin_args)# 初始化threading
training_pin_thread.daemon = True# 主线程结束后,该线程结束
training_pin_thread.start()
for iteration in ...max_iteration...:
training = pinned_training_queue.get(block=True)# 从pinned_training_queue中获取一个batch的训练数据
training_pin_semaphore.release()# 信号量value+1,线程退出
terminate_tasks(training_tasks)# 进程终止
代码中的注释在后面几乎都会提到并说明。
为了便于文章的阅读,先提前剧透如下:
training_queue存放的是原始训练数据,pinned_training_qeueu存放的是页锁定内存中的数据。
- 数据先被读取并送入
training_queue,该过程由len(dbs)个Process执行; - 接着,从
training_queue中读取的数据被放入页锁定内存中,并送进pinned_training_queue。对于训练集而言,该过程由一个子线程执行;验证集由另一个子线程执行; - 从
pinned_training_queue中读取的数据被送入模型中以供训练。这个过程在主进程中进行。
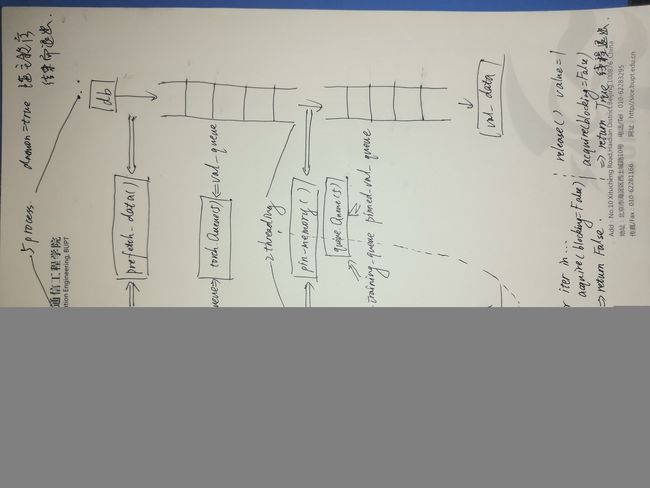
由于数据的准备和数据被送入模型进行训练是在不同的进程中同时进行的,因此每个batch的训练不需要先等待该batch数据的准备(占CPU),直接从满满的队列中取出准备好的数据进行训练(占GPU),使得GPU的利用时间占总时间的比例大大增加,提高GPU的利用率(volatile gpu-util)。
值得注意的是,以上并没有提到数据准备的子进程个数。理论上:
- 如果一个batch数据的准备时间<一个batch数据的训练时间,那么数据的训练不再需要等待数据的准备,GPU利用率已达较为理想的状态;
- 但若一个batch数据的读取时间>一个batch数据的训练时间,仅提供一个子进程来准备数据是不够的。此时,多个子进程可以提高数据的准备速度,使数据的训练不再需要等待数据的准备。
如果不想继续看的话,到这里已经基本OK了。后面是有关代码具体细节的解释。
关于两个队列中数据的详细处理过程见下节。
在这里要介绍一下在main()中出现的:
- 页锁定内存(pinned_memory)
- 守护线程(daemon)
此外:
- 信号量(threading.Semaphore())在下一节中再细说。
页锁定内存
在CUDA架构中,主机端的内存有两种:可分页内存和页锁定内存。在页锁定内存中,数据只能保存在主机内存中,不能保存在磁盘的虚拟内存中,但数据的读取速度较快;而可分页内存则相反,它能利用虚拟内存,但数据的读取速度较慢。
守护线程
daemon = True时,线程随着主程序的结束而结束;daemon = False时,主线程会等待线程执行完毕后再结束。
init_parallel_jobs()、pin_memory()
前面提到了两个队列,一个存放的是原始训练数据,另一个存放的是页锁定内存中的数据。
- init_parallel_jobs()
原始数据的读取在init_parallel_jobs()中,现摘取重要部分:
tasks = [Process(target=prefetch_data, args=(system_config, db, queue, fn, data_aug)) for db in dbs]
for task in tasks:
task.daemon = True
task.start()
其中,task.daemon = True和之前所介绍的守护线程功能相似;此外,代码中还提到了prefetch_data方法,其核心语句为:
data, ind = sample_data(system_config, db, ind, data_aug=data_aug)
这里的db也就是前面提到的COCO类的其中一个对象,data则是读取到的数据。在cornetnet.py中可以找到其格式:
{
"xs": [images],
"ys": [tl_heatmaps, br_heatmaps, tag_masks, tl_regrs, br_regrs, tl_tags, br_tags]
}
其中images是一个batch的图,由cv2.imread()方法读取。
总之,init_parallel_jobs()初始化了len(dbs)个Process,每个Process读取原始训练数据并将其放入training_queue。
- pin_memory()
将数据放进页锁定内存的代码在pin_memory()中,代码相对简单,不全部解释。但在代码中有这样一句:
while True:
(取data_queue的队尾数据,将数据放入琐页内存,并送入pinned_data_queue)
if sema.acquire(blocking=False):
return
注意sema.acquire(blocking=False)这句话,其中的sema就是training_pin_semaphore = threading.Semaphore(),即信号量,其介绍如下。
信号量
Semaphore部分源码如下:
def __init__(self, value=1):
if value < 0:
raise ValueError("semaphore initial value must be >= 0")
self._cond = Condition(Lock())
self._value = value
def acquire(self, blocking=True, timeout=None):
if not blocking and timeout is not None:
raise ValueError("can't specify timeout for non-blocking acquire")
rc = False
endtime = None
with self._cond:
while self._value == 0:
if not blocking:
break
if timeout is not None:
if endtime is None:
endtime = _time() + timeout
else:
timeout = endtime - _time()
if timeout <= 0:
break
self._cond.wait(timeout)
else:
self._value -= 1
rc = True
return rc
def release(self):
with self._cond:
self._value += 1
self._cond.notify()
为了便于分析信号量在这里的作用,我们先将程序中有关信号量的代码总结一下:
- 在
main()中,先初始化一个信号量training_pin_semaphore = threading.Semaphore(),然后training_pin_semaphore.acquire(); - 每将一个batch的数据送入页锁定内存,都会执行
sema.acquire(blocking=False),并判断其返回值(True/False); - 数据处理完毕后,在
main()中,有training_pin_semaphore.release()。
根据以上步骤,结合源码可分析如下:
- 初始化信号量时,value=1;acquire()后value自减一,即value=0;
- 对第一个batch数据处理时,value=0,blocking=False,因此
sema.acquire(blocking=False)返回False,线程继续循环,处理下一个batch数据。 training_pin_semaphore.release()使value自加一,即value=1,此时sema.acquire(blocking=False)返回True,执行break语句,线程循环结束。
从源码中也不难总结出信号量的机制:
- release()使value自加一;
- 当value>0时,acquire()使value自减一;
- 当value=0时,若blocking=False,则acquire()返回False;
- 当value=0时,若blocking=True,且不设置timeout,线程被锁,直到下一个release()的到来时释放;
- 当value=0时,若blocking=True,且设置timeout,线程最多锁timeout时间。在此期间,如果到来一个release()使value自加一,线程在timeout时间后被解锁,返回True;如果release()在该线程被锁的timeout时间内一直不来,则线程在timeout时间后同样被解锁,但返回False。
总之,pin_memory()从training_queue中读取一个batch的原始数据,将其放入琐页后送入pinned_training_queue。
附录-源码内容
先把train.py内容贴上,以供参照,可直接略过:
#!/usr/bin/env python
import os
import json
import torch
import numpy as np
import queue
import pprint
import random
import argparse
import importlib
import threading
import traceback
import torch.distributed as dist
import torch.multiprocessing as mp
from tqdm import tqdm
from torch.multiprocessing import Process, Queue, Pool
from core.dbs import datasets
from core.utils import stdout_to_tqdm
from core.config import SystemConfig
from core.sample import data_sampling_func
from core.nnet.py_factory import NetworkFactory
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
def parse_args():
parser = argparse.ArgumentParser(description="Training Script")
parser.add_argument("cfg_file", help="config file", type=str)
parser.add_argument("--iter", dest="start_iter",
help="train at iteration i",
default=0, type=int)
parser.add_argument("--workers", default=4, type=int)
parser.add_argument("--initialize", action="store_true")
parser.add_argument("--distributed", action="store_true")
parser.add_argument("--world-size", default=-1, type=int,
help="number of nodes of distributed training")
parser.add_argument("--rank", default=0, type=int,
help="node rank for distributed training")
parser.add_argument("--dist-url", default=None, type=str,
help="url used to set up distributed training")
parser.add_argument("--dist-backend", default="nccl", type=str)
args = parser.parse_args()
return args
def prefetch_data(system_config, db, queue, sample_data, data_aug):
ind = 0
print("start prefetching data...")
np.random.seed(os.getpid())
while True:
try:
data, ind = sample_data(system_config, db, ind, data_aug=data_aug)
queue.put(data)
except Exception as e:
traceback.print_exc()
raise e
def _pin_memory(ts):
if type(ts) is list:
return [t.pin_memory() for t in ts]
return ts.pin_memory()
def pin_memory(data_queue, pinned_data_queue, sema):
while True:
data = data_queue.get()
data["xs"] = [_pin_memory(x) for x in data["xs"]]
data["ys"] = [_pin_memory(y) for y in data["ys"]]
pinned_data_queue.put(data)
if sema.acquire(blocking=False):
return
def init_parallel_jobs(system_config, dbs, queue, fn, data_aug):
tasks = [Process(target=prefetch_data, args=(system_config, db, queue, fn, data_aug)) for db in dbs]
for task in tasks:
task.daemon = True
task.start()
return tasks
def terminate_tasks(tasks):
for task in tasks:
task.terminate()
def train(training_dbs, validation_db, system_config, model, args):
# reading arguments from command
start_iter = args.start_iter
distributed = args.distributed
world_size = args.world_size
initialize = args.initialize
gpu = args.gpu
rank = args.rank
# reading arguments from json file
batch_size = system_config.batch_size
learning_rate = system_config.learning_rate
max_iteration = system_config.max_iter
pretrained_model = system_config.pretrain
stepsize = system_config.stepsize
snapshot = system_config.snapshot
val_iter = system_config.val_iter
display = system_config.display
decay_rate = system_config.decay_rate
stepsize = system_config.stepsize
print("Process {}: building model...".format(rank))
nnet = NetworkFactory(system_config, model, distributed=distributed, gpu=gpu)
if initialize:
nnet.save_params(0)
exit(0)
# queues storing data for training
training_queue = Queue(system_config.prefetch_size)
validation_queue = Queue(5)
# queues storing pinned data for training
pinned_training_queue = queue.Queue(system_config.prefetch_size)
pinned_validation_queue = queue.Queue(5)
# allocating resources for parallel reading
training_tasks = init_parallel_jobs(system_config, training_dbs, training_queue, data_sampling_func, True)
if val_iter:
validation_tasks = init_parallel_jobs(system_config, [validation_db], validation_queue, data_sampling_func, False)
training_pin_semaphore = threading.Semaphore()
validation_pin_semaphore = threading.Semaphore()
training_pin_semaphore.acquire()
validation_pin_semaphore.acquire()
training_pin_args = (training_queue, pinned_training_queue, training_pin_semaphore)
training_pin_thread = threading.Thread(target=pin_memory, args=training_pin_args)
training_pin_thread.daemon = True
training_pin_thread.start()
validation_pin_args = (validation_queue, pinned_validation_queue, validation_pin_semaphore)
validation_pin_thread = threading.Thread(target=pin_memory, args=validation_pin_args)
validation_pin_thread.daemon = True
validation_pin_thread.start()
if pretrained_model is not None:
if not os.path.exists(pretrained_model):
raise ValueError("pretrained model does not exist")
print("Process {}: loading from pretrained model".format(rank))
nnet.load_pretrained_params(pretrained_model)
if start_iter:
nnet.load_params(start_iter)
learning_rate /= (decay_rate ** (start_iter // stepsize))
nnet.set_lr(learning_rate)
print("Process {}: training starts from iteration {} with learning_rate {}".format(rank, start_iter + 1, learning_rate))
else:
nnet.set_lr(learning_rate)
if rank == 0:
print("training start...")
nnet.cuda()
nnet.train_mode()
with stdout_to_tqdm() as save_stdout:
for iteration in tqdm(range(start_iter + 1, max_iteration + 1), file=save_stdout, ncols=80):
training = pinned_training_queue.get(block=True)
training_loss = nnet.train(**training)
if display and iteration % display == 0:
print("Process {}: training loss at iteration {}: {}".format(rank, iteration, training_loss.item()))
del training_loss
if val_iter and validation_db.db_inds.size and iteration % val_iter == 0:
nnet.eval_mode()
validation = pinned_validation_queue.get(block=True)
validation_loss = nnet.validate(**validation)
print("Process {}: validation loss at iteration {}: {}".format(rank, iteration, validation_loss.item()))
nnet.train_mode()
if iteration % snapshot == 0 and rank == 0:
nnet.save_params(iteration)
if iteration % stepsize == 0:
learning_rate /= decay_rate
nnet.set_lr(learning_rate)
# sending signal to kill the thread
training_pin_semaphore.release()
validation_pin_semaphore.release()
# terminating data fetching processes
terminate_tasks(training_tasks)
terminate_tasks(validation_tasks)
def main(gpu, ngpus_per_node, args):
args.gpu = gpu
if args.distributed:
args.rank = args.rank * ngpus_per_node + gpu
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
rank = args.rank
cfg_file = os.path.join("./configs", args.cfg_file + ".json")
with open(cfg_file, "r") as f:
config = json.load(f)
config["system"]["snapshot_name"] = args.cfg_file
system_config = SystemConfig().update_config(config["system"])
model_file = "core.models.{}".format(args.cfg_file)
model_file = importlib.import_module(model_file)
model = model_file.model()
train_split = system_config.train_split
val_split = system_config.val_split
print("Process {}: loading all datasets...".format(rank))
dataset = system_config.dataset
workers = args.workers
print("Process {}: using {} workers".format(rank, workers))
training_dbs = [datasets[dataset](config["db"], split=train_split, sys_config=system_config) for _ in range(workers)]
validation_db = datasets[dataset](config["db"], split=val_split, sys_config=system_config)
if rank == 0:
print("system config...")
pprint.pprint(system_config.full)
print("db config...")
pprint.pprint(training_dbs[0].configs)
print("len of db: {}".format(len(training_dbs[0].db_inds)))
print("distributed: {}".format(args.distributed))
train(training_dbs, validation_db, system_config, model, args)
if __name__ == "__main__":
args = parse_args()
distributed = args.distributed
world_size = args.world_size
if distributed and world_size < 0:
raise ValueError("world size must be greater than 0 in distributed training")
ngpus_per_node = torch.cuda.device_count()
if distributed:
args.world_size = ngpus_per_node * args.world_size
mp.spawn(main, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
else:
main(None, ngpus_per_node, args)