手把手教你学python第二十二讲(爬虫之正则表达式二进阶实战)
这一讲我们将要放弃字符串的复杂用法,要用简单的正则表达式配合bs4模块来写代码,下面会看到这会使代码大大简化。首先来解决如何去匹配一个ip地址的问题。先来说一下正则表达式遗留的一些小问题,第一个重复字符*,?和+的用法:*表示前一个字符匹配0次或多次,(因为解释器其实是cpython,c语言里int类型有大小限制,匹配的字符最多是20亿次,我相信是不会超过这个限制的)。+是匹配前一个字符1次或者多次,?是匹配前一个字符0次或者1次。更多符号可以参考http://bbs.fishc.com/thread-57691-1-1.html
需要指出的是正则表达式默认的匹配模式是贪婪模式,什么意思呢?就是尽可能地多匹配,上面地代码里,用*的时候,尽量匹配更多的a,+和?以及其它的语句都是如此,但是还有一种是懒惰模式,格式如下,注意问号本身是贪婪的,但是在原来表达式可以正常运作的情况下再加一个?就是懒惰了的。
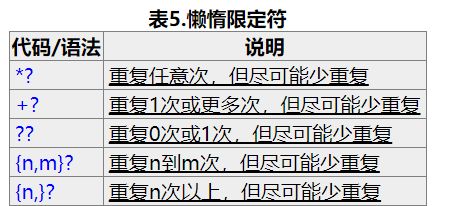

但是这种懒惰模式也是有规定的,如果不是以?结尾,仍然还是贪婪模式。

上面箭头指的三行没有结果是因为多打了空格。{m,n}m没有给出则默认是0,n默认是20亿。
下面就来给出如何匹配ip的正则表达式并且返回,

上一讲里讲过的search.group和findall都能返回,但是如果你要获得多个,那只能用findall

第一种不是很严谨,但是我觉得其实也可以用,ip地址这种格式的东西毕竟不多,当然第二种更严谨。这里匹配ip地址的表达式用了|符号,这是或的意思。第一种是会匹配到256-999这样的,第二和第三种使用了或,ip地址每一个数可能在200-249,250-255之间,这是前两个或,最后的[1]?\d?\d是表示的剩下的0-199,也许你还会注意到上面两个在最外面都加了(),这个是必须的,因为在正则表达式里面()是代表的分组的。

我们暂时没有用到去给组命名,都是交给自动门命名了。findall返回的列表里的元素都是元组,元组的第一个元素是我们需要的ip。那么ip就好办了。还有一点需要重点提醒,几个或一定要用小括号括起来,不然的话就会出现

这种情况就是因为或没有加括号而导致逻辑并不是你原来的逻辑了,这里为什么直接返回123?因为后面有一个或是1?\d?\d,他是和前面的{3}次的是或关系,而后面满足了条件。也许你会说,一般的匹配模式不是贪婪模式吗?但是如果你没加或的话逻辑就变成了(2[0-4]\d|25[0-5]|[1]?\d\d?\.){3}2[0-4]\d或25[0-5]或1?\d?\d也就是这种写法默认第一个或条件的第四个数必须是
200-249了,上图最后一行改了ip结果和这里的解释是相符的。当然上图还复习了一下或的短路逻辑。代理ip我们已经获取了,还有什么呢?端口号和类型对吧,我们先复习一下端口号和类型的位置在哪。
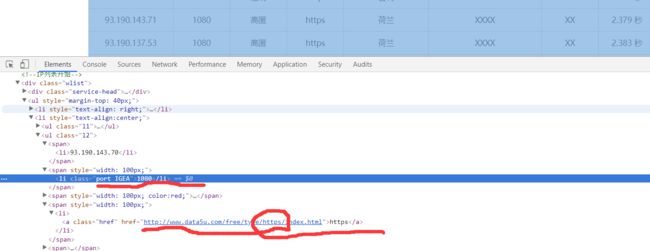
端口号和ip的类型我们也可以用正则表达式来写。整个程序就是这样的。

结果就是这样的,如果你的基础足够扎实,那么是可以看懂的,我就不再多说了。结果如下
这个IP就可以为我们所用了,当然还要和typ配合使用。我这是爬取的代理ip很少,所以花费时间并不是很长,如果爬取得代理ip数量很多得话,我们需要用BeatifulSoup来降低计算机的搜索工作。怎么降低呢?

观察到有效的内容的class 属性都是等于l2,那么其他的内容计算机就可以不必搜索了,这就降低了计算机的搜索量。我们就按照类的属性来搜索。
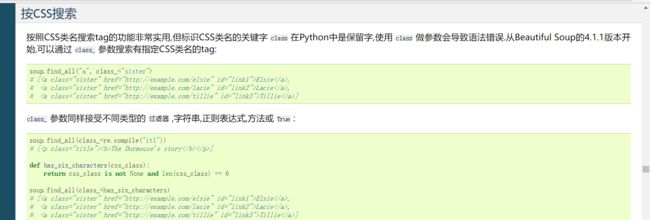
里面有一个正则表达式的函数,compile的用法如下


下面改进一下程序吧。
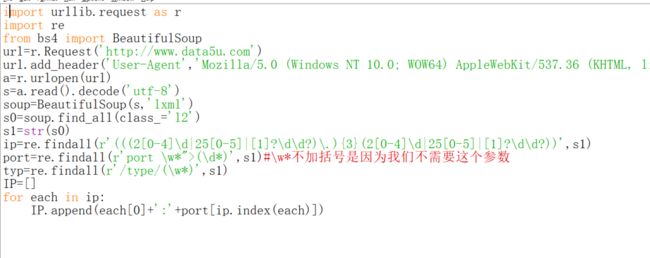
为什么要s1=str(s0)呢?这是因为s0是一个列表,而不是字符串或者二进制类型。

如果没有str那一句。就会报错,因为也是类型的问题。
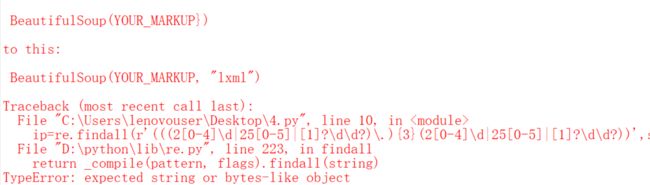
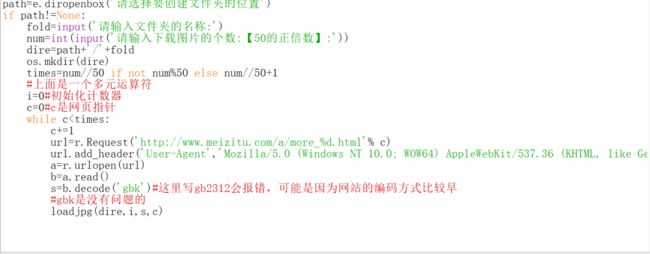
代理ip搞定了,那么下面就来让爬去小姐姐的图片的代码更简洁吧。首先来复习一下踩点的过程。
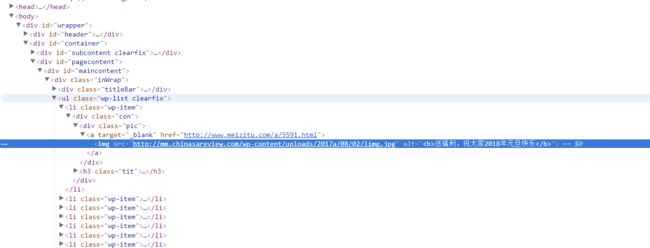
class的属性都是wp-item,利用这一点来减少计算机的搜索量,虽然不一定需要,更进一步的其实我们发现这些图片的网址都在img这个标头里面,可以进一步减少搜索量。由于这个网站可能并没有设置访问频率的限制,就不用爬虫了。还有一个问题就是怎么写一个url的正则表达式呢?
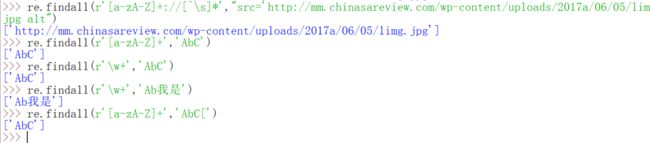
我们来解释一下这个正则表达式先。[a-zA-Z]就是所有的字母,也许你还记得\w好像也有类似的功能,但是\w还可以表示汉字和下划线,所以还是用或者更稳一点。后面有两个没有见过的^和\s,^本身的意思是匹配字符的开始,与之相反的是$是匹配字符的结束。但是这里充当的是反义,还有一点上面的pattern正则表达式里没有小括号的时候,findall就会把匹配到的整体作为分组返回。

\s是匹配任意的空白符(注意大小写)。下面来实际演示一下。

看到了也可以写为\S。但是这样写会有很多问题,我们不妨直接利用属性的值,因为网址正好是src的值,这样做会简单很多。
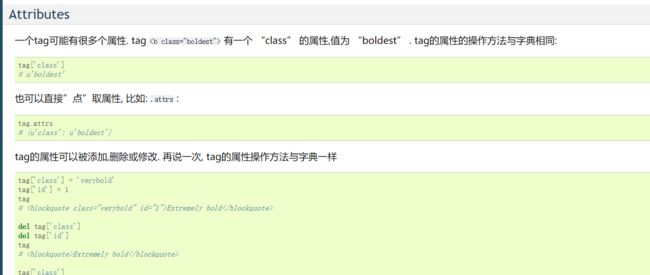

亲测是可行的。到这里应该就可以体会到正则表达式和bs4包的简洁之处了吧。下面来处理以前遗留的练习题先。还记得那个爬百度百科的练习吗,现在都能做了。

首先要说明的是,链接都会在href属性的值里,

href与前面的src属性是不同的,参考了https://blog.csdn.net/annsheshira23/article/details/51133709
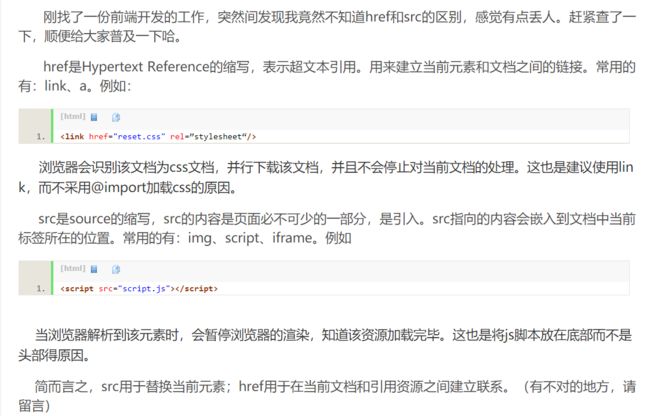
src是必须有的,因为你只要放一张图片,图片必定是有来源的,你在HTML代码里就得体现,而href可以没有,但是有了会更方便用户浏览,当用户想看大图或者点开另一个链接的时候,就很很方便。查看蓝色字体,也就是链接,就会发现一个href。(我的百度百科可能和你们不一样,那只是因为我用了脚本而已)

点一张图片会出现大图其实也是因为有href

而这张图片之所以能出现在这里是因为有src。有些图片是没有href属性的,所以你点它也没什么反应的。
那么目标就很明确了 ,首先要找出带有href属性的tag,那个bs4的学习网页上一讲都已经给出来了
然后在筛选出有view的就可以了。由于我自己写过,其实就只有下面这一个。和上面的输出不一样对吧,也很正常,上面那张图片很老了。

写代码来实现一下。

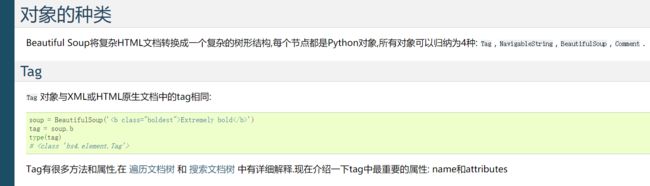
下面就来理解一下这段程序,前面修改user-agent的就不多说了。后面用BeautifulSoup4里的find_all前面也已经用过了。按类的属性其实前面也用过了,只是好像没有拿出来说,这些内容都在以前给过的https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/index.html里

需要注意的是后面的re.compile('view')为什么要用一个正则表达式呢?直接用'view'可不可以呢?


就职这是不可以的,因为href='view'就表示href的属性的值就是view,而如果你跑到前面去看的话就会发现,href的属性里只是含有'view'而不是说就是'view',而re.compile('view')就表示其中含有'view'而不是说全部都是'view',为了更好理解,看一个例子吧。

也就是说href=re.compile('view')相当于扩大了搜索范围,href属性的值里含有view的tag都会被返回,而href='view'就是说href的值必须是view才会被返回,说了这么多,希望你们可以理解这两者的区别。如果上面的程序改为find_all('view')就会什么都不会返回,因为没有href的值是'view'。

看下一个点,字符串的join函数应该不是盲点,如果你前面的基础都看了。each['href']和字典的用法是一样的,那还有什么地方没有见过呢?each.text是没有见过的。
什么值才是字符串呢?不在<>里的都是字符串,或者说在.><里的,但是还有一种特别的注释
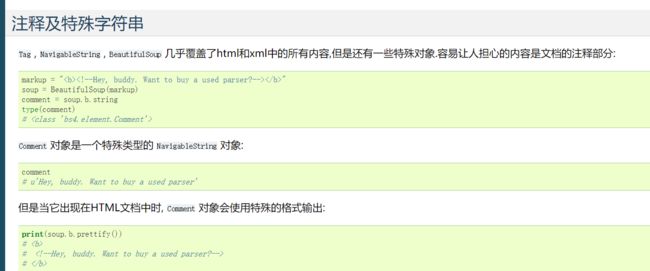
也可以用string来获取一个tag的字符串,学到这里你可能已经有感觉了才是一个tag结束的标志。下面的代码展示了string和text的类似之处

不过马上我们就会看到其实它们的差别还是很大的,如果仅仅是string,那么返回的仅仅是第一个><里的内容,我们看到是没有的,所以each.string是nonetype,目前我见过的tag只会有0个或者1个字符串,所以用text更好,text会选择有的那一个输出,没有就输出none,当然我们还有each.strings,不过它是一个生成器,我们可以用next()来获取生成器里面的内容。

有的人可能会对编码有疑问。

这个题的代码已经解释清楚了,下一道题。

首先拿到题要思考,如何实现搜索指定关键字呢?那就需要我们对百度百科的页面研究下一下了。

输入2b按进入词条以后。
我们看到最上面有两个事件,分别点开看一看。
点开第一个

点开第二个

猜想可能有两种方式来访问。第一种直接输入https://baike.baidu.com/item/猪八戒,回车

发现至少在浏览器里是可行的。第二种https://baike.baidu.com/search/word?word=猪八戒
也可得到上面的结果。那么就先按第一种来,因为简单嘛。审查一下副标题的元素。
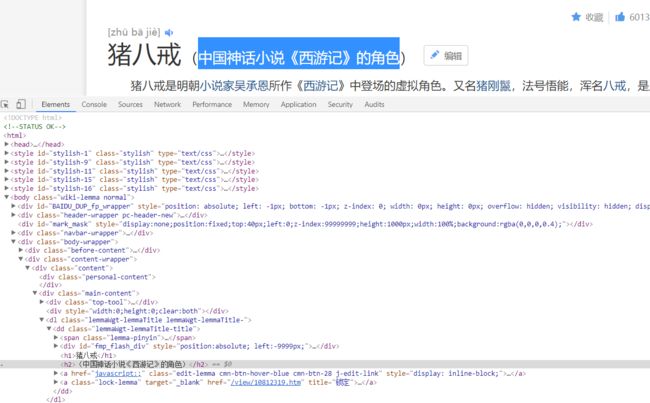
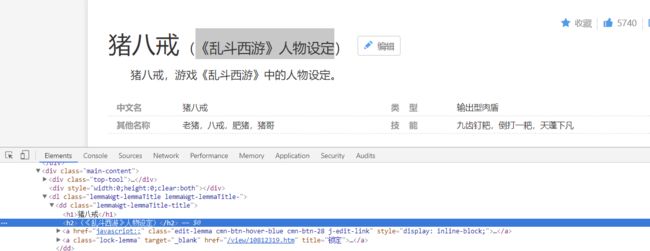
看来副标题的位置相对还是比较固定的,可能按照h2这个tag就可以得到副标题,如果不能,看代码运行出来的结果在作修改。那么我们还得看看多义词是怎么存放的。对上面的几个链接检查元素。
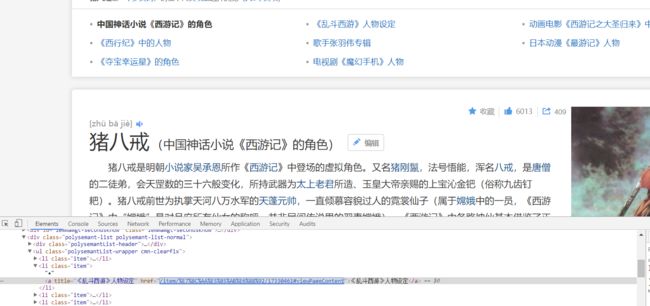
几个多义存放的地方class属性的值应该都是item,并且a里面的title的值是我们需要的。

我们不需要都写,因为副标题和上面的链接的内容是一样的,所以我们二选一来编程就行,我选的是利用a里面的title。大概摸清楚位置之后就可以开始写了,如果位置不足以定位你想要的信息,后面再改就行。
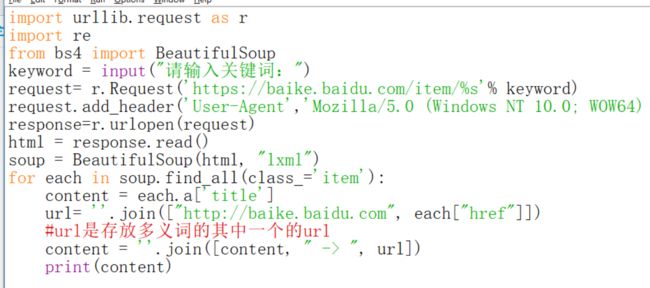
运行的时候会出现错误。没关系,我们要看懂错误内容就可以。说是ascii码不能对字符进行过编码,这也很好理解,因为ascii码无法编码汉字,怎么办呢?到那个文件里把ascii改为utf-8,
utf-8和ascii码是兼容的,但utf-8是可以编码汉字的。
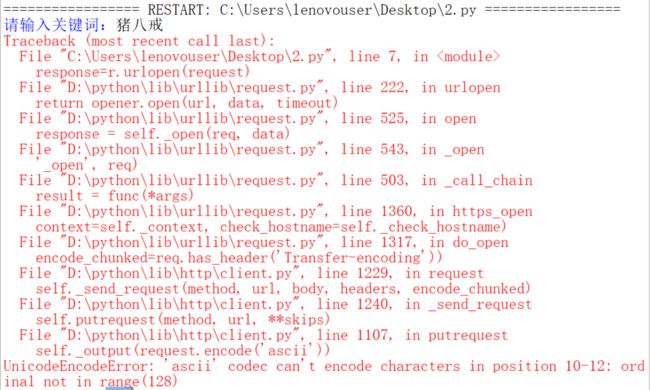
进入最下面错误的那个py,到1107行。怎么到1107行呢?按alt+g或者点edit里面有一个go to line,输入1107,点ok

然后把ascii改为utf-8。记得要保存。

然后来运行我们的程序。哎,还是有错啊。我们得就看看each的内容了。发现了什么,是不是没有a啊,只有span。

原来我们当前浏览的这个页面的副标题不是在a这个tag的title里。这点我们小改一下即可,如果你想用第二种方法,那你就必须要打开很多网页,因为一个网页里只有一个h2,你要打开所有的多义词链接才可以,太麻烦,不如来改进这一点。

改进一下我们的程序。

完工了。

没想到孙悟空还挺多的。

那么还有下一道题,就是优化一下上个程序而已。
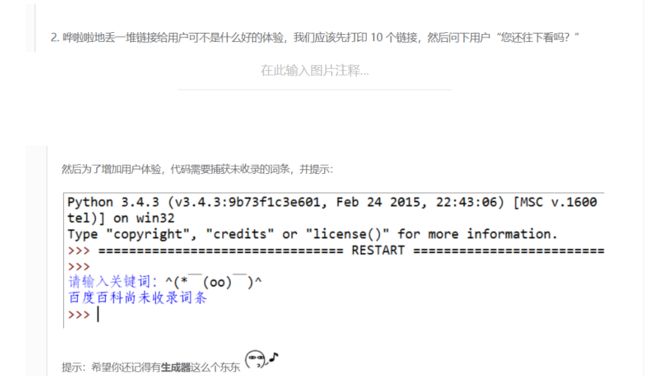
那么我们先看看如果搜索百度百科没有收录的内容会在哪里报错。enmmm,并没有报错,而是什么都没有返回,如果你打soup,会得到下面的结果。
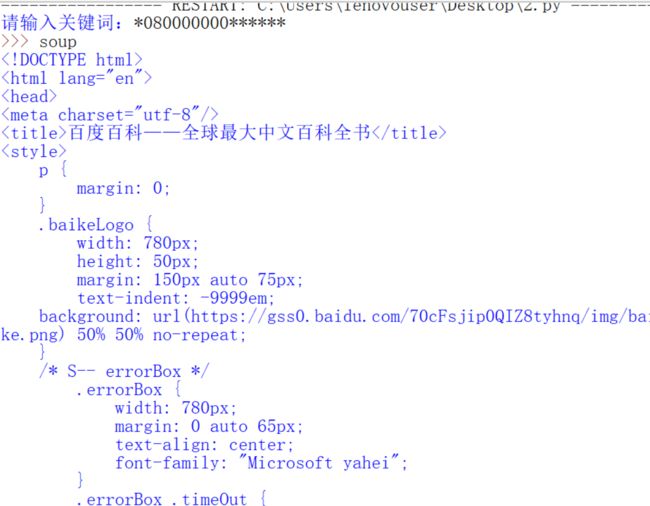

如何改进呢?其实会发现这个页面是没有item的,其一我们可以find试试,
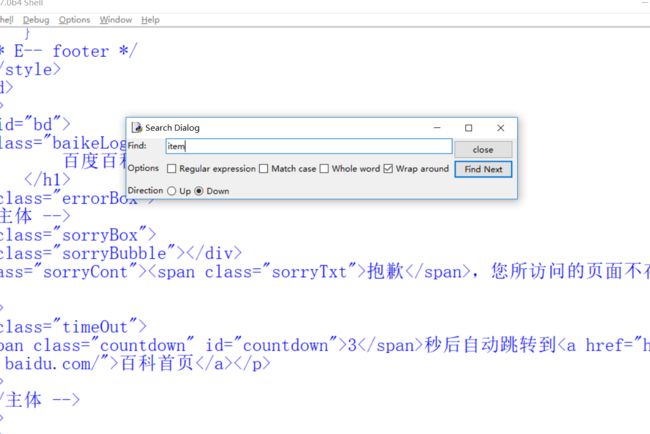
或者直接看。

那么可以加一个判断条件就可以解决第二个问题,第一个要求先放出来10条的要求用生成器确实很好写,虽然不用生成器也可以完成的,就当是复习一下生成器了。
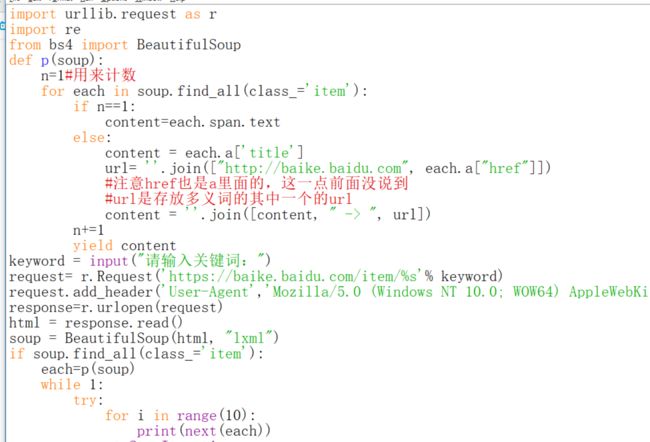
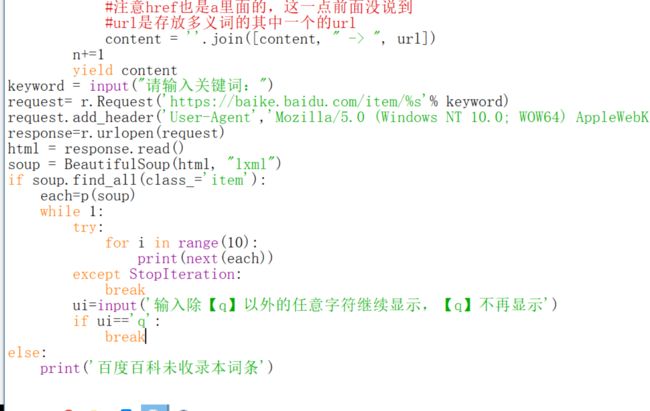



亲测是可行的。这里面的try和except是不可少的,可能有的人已经忘了,我们看看没有的后果。
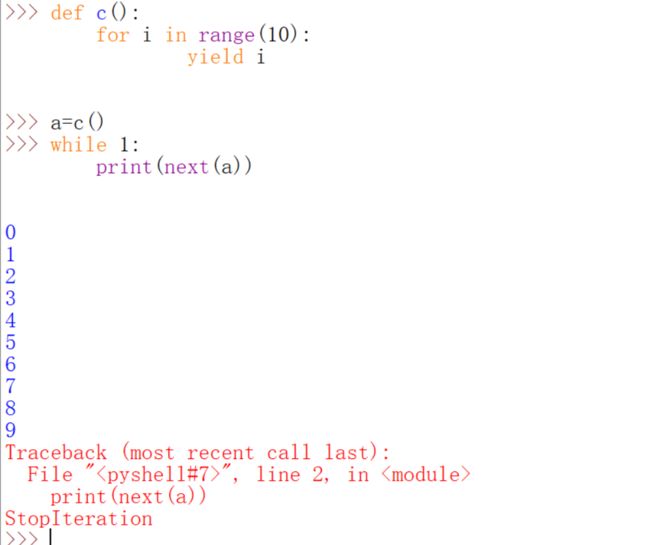
不用生成器可不可以呢?也是可以的。用容器类型就可以:
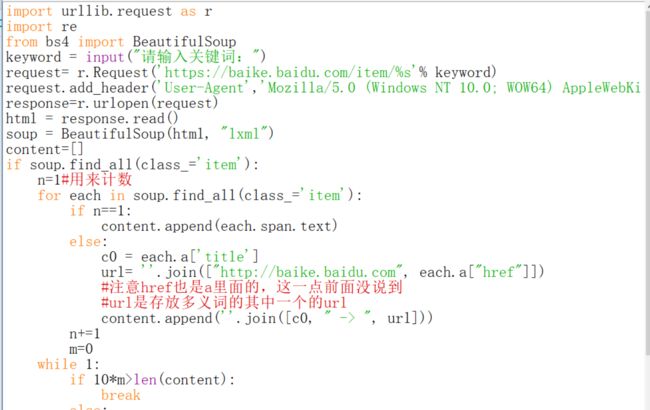


多给几种方法就是要告诉你们脑袋要灵活,知识是活的,解决一个问题的办法不止一个。
最后一道练习,还有一个登陆豆瓣网的对吧。我们就来搞定这个吧。首先老样子,踩点作业。
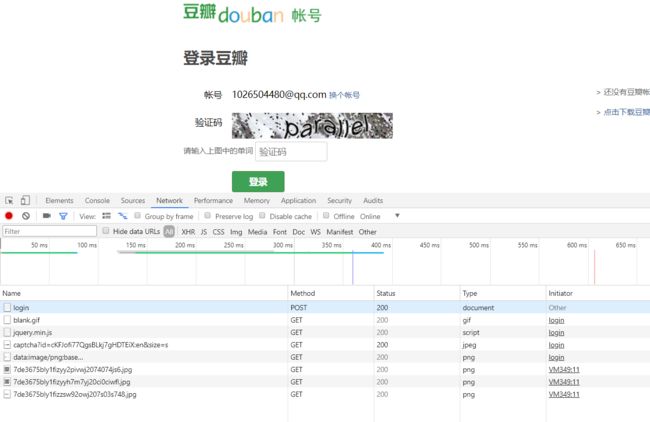
豆瓣前三次登陆是不要验证码的,但是我今天已经登录次数超过三次了,后面可能会用代理ip来试试,有可能不要验证码的情况。首先我们点进去login。Request URL是我们登陆的网址。


还记得以前爬有道翻译的时候吗。

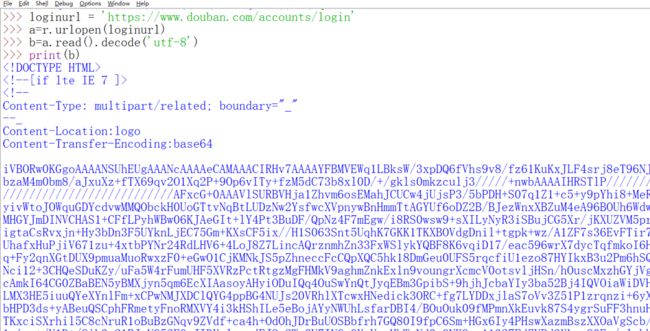
这个From data就是在Request的data参数里要填写的内容,并且还有转化为json格式。我们先来看看验证码的地址在哪里。

验证码地址有了。我们先来看如果登陆成功了会怎样,首先网页会变。


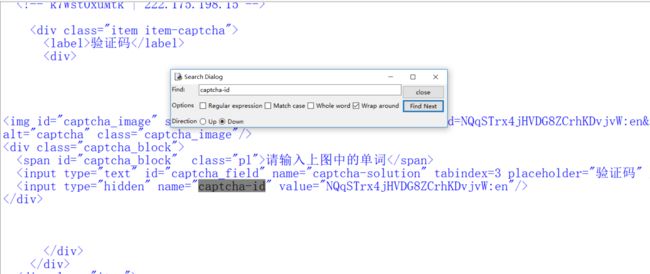
看得出来captcha solution就是填验证码的地方。眼尖的人可能会发现captcha-id变了,虽然不确定它是否会影响到我们的登陆,但是我们还是看看这东西在哪,既然和验证码有关,就应该在验证码地址的附近,很快就可以发现。如果你不知道怎么找,怎么办?

其实很简单的在IDLE里查找就行了。
看了这些好像已经可以做了呢,那就来试试。
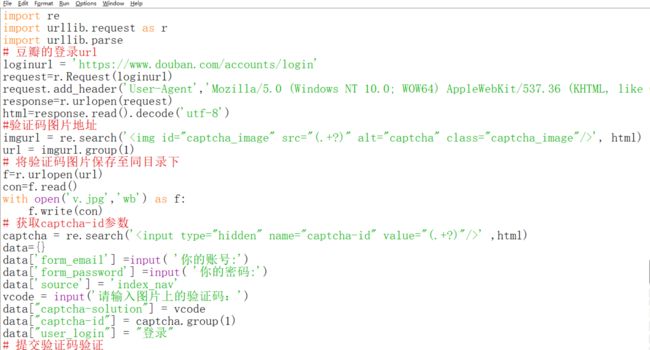

然后结果呢?

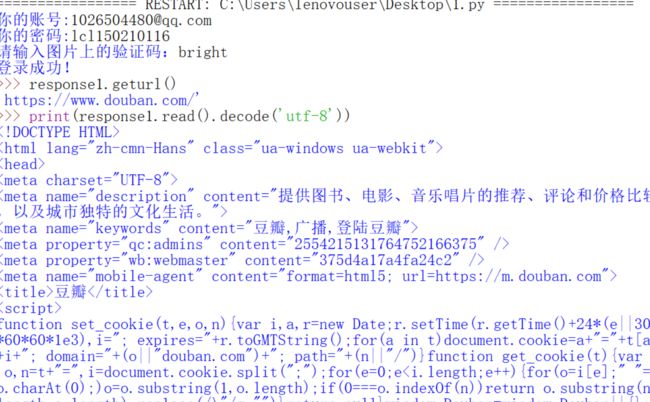
和用网页登陆的比较一下。
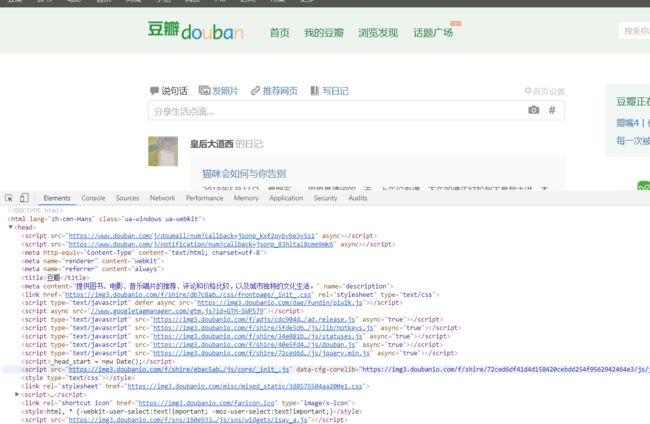
好像有点不一样。这次我们故意不填验证码呢?
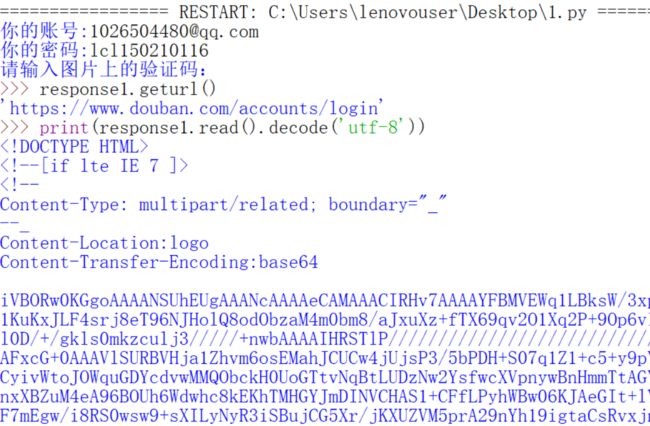
是可以看出来差别的。那么下面用代理ip来试一下,前面说过前三次是不需要填验证码的。

注意这里的代理一定要用https类型的,因为豆瓣是https的,前面讲过这个类型是必须匹配的,不然相当于是没有用代理,上一讲说过这个问题的,应该有印象的。

就出现了
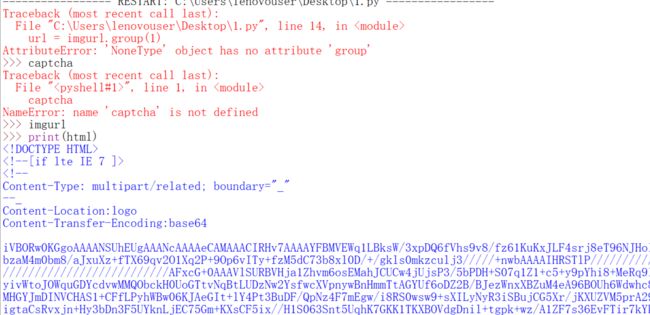
imgurl为什么是Nonetype呢?我们把html打印出来看看。搜索captcha_image

你会发现是没有的,那么为了让前三次登陆也可以用这个代码(由于今天我已经超过了三次,就用代理ip来试),需要改动。主要是判断下imgurl是不是空的。



看到是不需要验证码就可以登陆成功的。这一讲就先到这里了。如果喜欢的,清点一波关注。我有个小目标,希望能有250粉丝,也许有生之年看不到了233.