lambda表达式与函数式编程(待完善)
参考文档
http://www.cnblogs.com/CarpenterLee/p/6729368.html
第二篇关于lambda 与 匿名内部类的反编译对比很好;
性能对比中,有关JIT预热部分做的也很好;
stream操作简述

Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记,只有结束操作才会触发实际计算。
中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;有状态的要求顺序性,如果更改流水线顺序会影响结果;无状态不会。
结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。
多种stream操作实例
1.reduce用法
reduce操作可以实现从一组元素中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。reduce()的方法定义有三种重写形式:
Optionalreduce(BinaryOperator accumulator) T reduce(T identity, BinaryOperatoraccumulator) U reduce(U identity, BiFunction
虽然函数定义越来越长,但语义不曾改变,多的参数只是为了指明初始值(参数identity),或者是指定并行执行时多个部分结果的合并方式(参数combiner)。reduce()最常用的场景就是从一堆值中生成一个值。用这么复杂的函数去求一个最大或最小值,你是不是觉得设计者有病。其实不然,因为“大”和“小”或者“求和"有时会有不同的语义。
需求:从一组单词中找出最长的单词。这里“大”的含义就是“长”。
// 找出最长的单词
Stream stream = Stream.of("I", "love", "you", "too");
Optional longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
//Optional longest = stream.max((s1, s2) -> s1.length()-s2.length());
System.out.println(longest.get());
List stringList = Lists.newArrayList("1 ", " 2", "3 ", "4 ");
String stringOptional = stringList.stream()
.reduce("0",
(s1, s2) -> s1 + s2,
(a, b) -> a + b);
上述代码会选出最长的单词love,其中Optional是(一个)值的容器,使用它可以避免null值的麻烦。当然可以使用Stream.max(Comparator comparator)方法来达到同等效果,但reduce()自有其存在的理由。
=====


需求:求出一组单词的长度之和。这是个“求和”操作,操作对象输入类型是String,而结果类型是Integer。
// 求单词长度之和
Stream stream = Stream.of("I", "love", "you", "too");
Integer lengthSum = stream.reduce(0, // 初始值 // (1)
(sum, str) -> sum+str.length(), // 累加器 // (2)
(a, b) -> a+b); // 部分和拼接器,并行执行时才会用到 // (3)
// int lengthSum = stream.mapToInt(str -> str.length()).sum();
System.out.println(lengthSum); 上述代码标号(2)处将i. 字符串映射成长度,ii. 并和当前累加和相加。这显然是两步操作,使用reduce()函数将这两步合二为一,更有助于提升性能。如果想要使用map()和sum()组合来达到上述目的,也是可以的。
reduce()擅长的是生成一个值,如果想要从Stream生成一个集合或者Map等复杂的对象该怎么办呢?终极武器collect()横空出世!
2.collect
DutyInfoPo dutyInfoPo1 = DutyInfoPo.builder().dateType("a").dateCode("1").build();
DutyInfoPo dutyInfoPo2 = DutyInfoPo.builder().dateType("a").dateCode("2").build();
DutyInfoPo dutyInfoPo0 = DutyInfoPo.builder().dateType("a").dateCode("0").build();
DutyInfoPo dutyInfoPo3 = DutyInfoPo.builder().dateType("b").dateCode("3").build();
DutyInfoPo dutyInfoPo4 = DutyInfoPo.builder().dateType("b").dateCode("4").build();
DutyInfoPo dutyInfoPo5 = DutyInfoPo.builder().dateType("b").dateCode("5").build();
List dutyInfoPoList = Lists.newArrayList(dutyInfoPo1, dutyInfoPo2, dutyInfoPo3, dutyInfoPo4, dutyInfoPo0, dutyInfoPo5);
Map map = dutyInfoPoList.stream()
.collect(Collectors.groupingBy(
DutyInfoPo::getDateType,
Collectors.mapping(
DutyInfoPo::getDateCode,
Collectors.collectingAndThen(
Collectors.toList(),
dateCode -> Joiner.on("+").join(dateCode)
)
)
)
);
println(map);
*****参考文档 http://www.cnblogs.com/CarpenterLee/p/6550212.html
实现方式简述--迭代
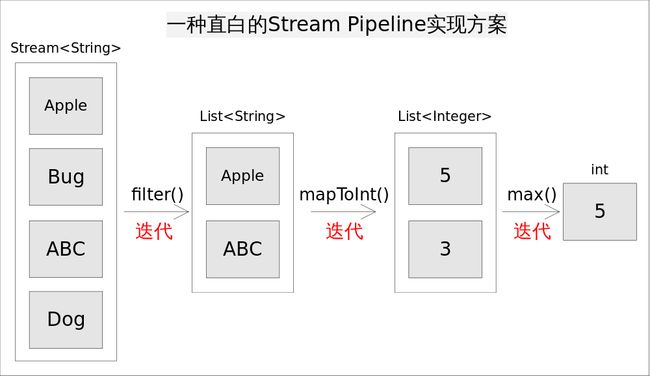
仍然考虑上述求最长字符串的程序,stream是一种直白的流水线实现方式是为每一次函数调用都执一次迭代,并将处理中间结果放到某种数据结构中(比如数组,容器等)。具体说来,就是调用filter()方法后立即执行,选出所有以A开头的字符串并放到一个列表list1中,之后让list1传递给mapToInt()方法并立即执行,生成的结果放到list2中,最后遍历list2找出最大的数字作为最终结果。程序的执行流程如如所示:
这样做实现起来非常简单直观,但有两个明显的弊端:
- 迭代次数多。迭代次数跟函数调用的次数相等。
- 频繁产生中间结果。每次函数调用都产生一次中间结果,存储开销无法接受。
这些弊端使得效率底下,根本无法接受。如果不使用Stream API我们都知道上述代码该如何在一次迭代中完成,大致是如下形式:
int longest = 0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以A开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
}
}
采用这种方式我们不但减少了迭代次数,也避免了存储中间结果,显然这就是流水线,因为我们把三个操作放在了一次迭代当中。只要我们事先知道用户意图,总是能够采用上述方式实现跟Stream API等价的功能,但问题是Stream类库的设计者并不知道用户的意图是什么。如何在无法假设用户行为的前提下实现流水线,是类库的设计者要考虑的问题。
stream流水线的实现方式 -- 原理
我们大致能够想到,应该采用某种方式记录用户每一步的操作,当用户调用结束操作时将之前记录的操作叠加到一起在一次迭代中全部执行掉。沿着这个思路,有几个问题需要解决:
- 用户的操作如何记录?
- 操作如何叠加?
- 叠加之后的操作如何执行?
- 执行后的结果(如果有)在哪里?
注意这里使用的是“操作(operation)”一词,指的是“Stream中间操作”的操作,很多Stream操作会需要一个回调函数(Lambda表达式),因此一个完整的操作是<数据来源,操作,回调函数>构成的三元组。Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的PipelineHelper来代表Stage,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。跟Stream相关类和接口的继承关系图示。
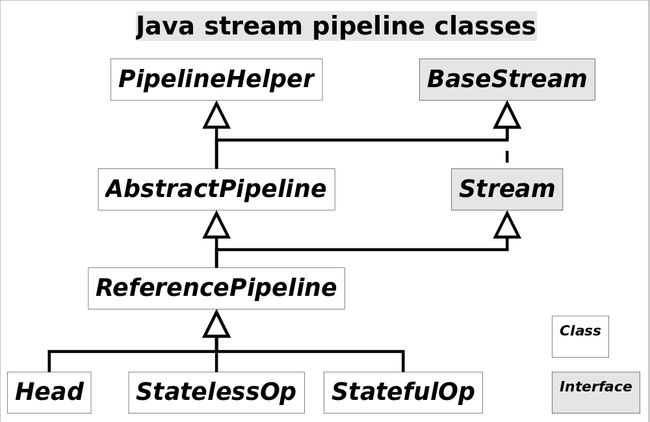
还有IntPipeline, LongPipeline, DoublePipeline没在图中画出,这三个类专门为三种基本类型(不是包装类型)而定制的,跟ReferencePipeline是并列关系。图中Head用于表示第一个Stage,即调用调用诸如Collection.stream()方法产生的Stage,很显然这个Stage里不包含任何操作;StatelessOp和StatefulOp分别表示无状态和有状态的Stage,对应于无状态和有状态的中间操作。
Stream流水线组织结构示意图如下:
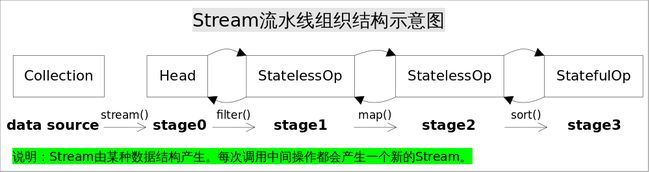
图中通过Collection.stream()方法得到Head也就是stage0,紧接着调用一系列的中间操作,不断产生新的Stream。这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作。这就是Stream记录操作的方式。
===
// Stream.map(),调用该方法将产生一个新的Stream
public final Stream map(Function mapper) {
...
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override /*opWripSink()方法返回由回调函数包装而成Sink*/
Sink opWrapSink(int flags, Sink downstream) {
return new Sink.ChainedReference(downstream) {
@Override
public void accept(P_OUT u) {
R r = mapper.apply(u);// 1. 使用当前Sink包装的回调函数mapper处理u
downstream.accept(r);// 2. 将处理结果传递给流水线下游的Sink
}
};
}
};
} 这里XX.apply是当前stream操作的应用;
accpet()是后续的应用,采用downstream为下一个操作;
// 按照部门对员工分布组,并只保留员工的名字
Map> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.mapping(Employee::getName,// 下游收集器
Collectors.toList())));// 更下游的收集器
// 使用下游收集器统计每个部门的人数
Map totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.counting()));// 下游收集器
结果收集 -- 终结状态操作
回到流水线执行结果的问题上来,需要返回结果的流水线结果存在哪里呢?这要分不同的情况讨论,下表给出了各种有返回结果的Stream结束操作。
| 返回类型 | 对应的结束操作 |
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 归约结果 | reduce() collect() |
| 数组 | toArray() |
-
对于表中返回boolean或者Optional的操作(Optional是存放 一个 值的容器,使用它可以避免null值的麻烦)的操作,由于值返回一个值,只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
List stringList = Lists.newArrayList("1 ", " 2", "3 ", "4 ");
Optional stringOptional = stringList.stream()
.map(String::trim)
.filter("1"::equals)
// .forEach(System.out::println)
.findFirst();
if(stringOptional.isPresent()){
String string = stringOptional.get();
}
-
对于归约操作,最终结果放在用户调用时指定的容器中(容器类型通过收集器指定)。collect(), reduce(), max(), min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用reduce()方法实现的。
-
对于返回是数组的情况,毫无疑问的结果会放在数组当中。这么说当然是对的,但在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。关于Node的具体结构,我们会在下一节探究Stream如何并行执行时给出详细说明。
性能对比
上述三个实验的结果可以总结如下:
- 对于简单(基本类型)操作,比如最简单的遍历,Stream串行API性能明显差于显示迭代,但并行的Stream API能够发挥多核特性。
- 对于复杂操作,Stream串行API性能可以和手动实现的效果匹敌,在并行执行时Stream API效果远超手动实现。parallelStream() / parallel()
所以,如果出于性能考虑,1. 对于简单操作推荐使用外部迭代手动实现,2. 对于复杂操作,推荐使用Stream API, 3. 在多核情况下,推荐使用并行Stream API来发挥多核优势,4.单核情况下不建议使用并行Stream API。
如果出于代码简洁性考虑,使用Stream API能够写出更短的代码。即使是从性能方面说,尽可能的使用Stream API也另外一个优势,那就是只要Java Stream类库做了升级优化,代码不用做任何修改就能享受到升级带来的好处。
参考文档 https://www.cnblogs.com/CarpenterLee/p/6675568.html
代码仓库地址 https://github.com/CarpenterLee/JavaLambdaInternals/tree/master/perf/StreamBenchmark/src/lee
本文详细介绍了Stream流水线的组织方式和执行过程,学习本文将有助于理解原理并写出正确的Stream代码,同时打消你对Stream API效率方面的顾虑。如你所见,Stream API实现如此巧妙,即使我们使用外部迭代手动编写等价代码,也未必更加高效。