matlab svmtrain和svmclassify函数使用示例
监督式学习(Supervised Learning)常用算法包括:线性回归(Linear Regression)、逻辑回归(Logistic Regression)、神经网络(Neural Network)以及支持向量机(Support Vector Machine,SVM)等。支持向量机与逻辑回归算法类似,都是解决二分类或多分类问题,但是SVM在非线性回归预测方面具有更优秀的分类效果,所以SVM又被称为最大间距分类器。
本文不对支持向量机的原理进行详细解释,直接运用matlab自带的工具箱函数svmtrain、svmclassify解决实际的二分类问题。
导入数据:
clear; close all; clc;
%% ================ load fisheriris.mat ================
load fisheriris.mat1、对于线性分类问题,我们选取线性核函数,原始数据包括训练数据和测试数据两部分。
data = meas(51:end,3:4); % column 3,column 4作为特征值
group = species(51:end); % 类别
idx = randperm(size(data,1));
N = length(idx);
% SVM train
T = floor(N*0.9); % 90组数据作为训练数据
xdata = data(idx(1:T),:);
xgroup = group(idx(1:T));
svmStr = svmtrain(xdata,xgroup,'Showplot',true);训练过程得到结构体svmStr,对测试数据进行预测
% SVM predict
P = floor(N*0.1); % 10组预测数据
ydata = data(idx(T+1:end),:);
ygroup = group(idx(T+1:end));
pgroup = svmclassify(svmStr,ydata,'Showplot',true); % svm预测
hold on;
plot(ydata(:,1),ydata(:,2),'bs','Markersize',12);
accuracy1 = sum(strcmp(pgroup,ygroup))/P*100; % 预测准确性
hold off;程序运行结果如下:

图中,方块*号表示测试数据的预测结果,accuracy1结果为90%(上下浮动)。
2、对于非线性分类问题,我们选取高斯核函数RBF,原始数据包括训练数据和测试数据两部分。
训练过程前,导入原始数据:
data = meas(51:end,1:2); % column 1,column 2作为特征值
group = species(51:end); % 类别
idx = randperm(size(data,1));
N = length(idx);
% SVM train
T = floor(N*0.9); % 90组数据作为训练数据
xdata = data(idx(1:T),:);
xgroup = group(idx(1:T));对于高斯核函数,有两个参数对SVM的分类效果有着重要的影响:一个是sigma;另一个是C。
首先讨论sigma的影响,sigma反映了RBF函数从最大值点向周围函数值下降的速度,sigma越大,下降速度越慢,对应RBF函数越平缓;sigma越小,下降速度越快,对应RBF函数越陡峭。对于不同的sigma,程序代码:
% different sigma
figure;
sigma = 0.5;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','rbf_sigma',...
sigma,'showplot',true);
title('sigma = 0.5');
figure;
sigma = 1;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','rbf_sigma',...
sigma,'showplot',true);
title('sigma = 1');
figure;
sigma = 3;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','rbf_sigma',...
sigma,'showplot',true);
title('sigma = 3');分类平面分别如下:



从图中可以看出,sigma越小,分类曲线越复杂,事实也确实如此。因为sigma越小,RBF函数越陡峭,下降速度越大,预测过程容易发生过拟合问题,使分类模型对训练数据过分拟合,而对测试数据预测效果不佳。
然后讨论C的影响,程序代码如下:
% different C
figure;
C = 1;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','boxconstraint',...
C,'showplot',true);
title('C = 0.1');
figure;
C = 8;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','boxconstraint',...
C,'showplot',true);
title('C = 1');
figure;
C = 64;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','boxconstraint',...
C,'showplot',true);
title('C = 10');分类平面如下:


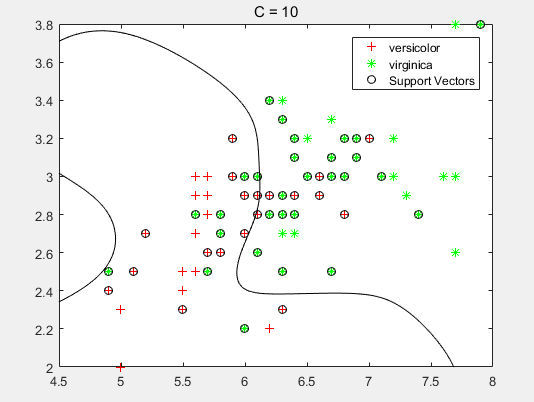
从图中可以发现,C越大,分类曲线越复杂,也就是说越容易发生过拟合,因为C对应逻辑回归的lambda的倒数。
若令sigma=1,C=1,则对测试数据的预测程序:
% SVM predict
P = floor(N*0.1); % 10组预测数据
ydata = data(idx(T+1:end),:);
ygroup = group(idx(T+1:end));
% sigma = 1,C = 1,default
figure;
svmStr = svmtrain(xdata,xgroup,'kernel_function','rbf','showplot',true);
pgroup = svmclassify(svmStr,ydata,'Showplot',true); % svm预测
hold on;
plot(ydata(:,1),ydata(:,2),'bs','Markersize',12);
accuracy2 = sum(strcmp(pgroup,ygroup))/P*100; % 预测准确性
hold off;
程序运行结果如下:

图中,方块*号表示测试数据的预测结果,accuracy2结果为70%(上下浮动)。
分类效果不佳因为两个特征量的选择,可以选择更合适的特征量。