GPU云服务器+tensorboard
流程如下:
python test.py(完整代码在附录,数据集会由代码自动下载,不用担心)
运行后会自动生成model文件夹
#--------------------------------------------------
tensorboard --logdir=./model
得到:
http://ubuntu19:6007/
#--------------------------------------------------
内网穿透来模仿云端服务器的环境:
./ngrok http 6007
这里的端口要与tensorboard给的端口一致。
#--------------------------------------------------
浏览器打开
http://5ec1c84d.ngrok.io/(这个链接来自上方ngrok给的链接)
即可.
最后结果如下:
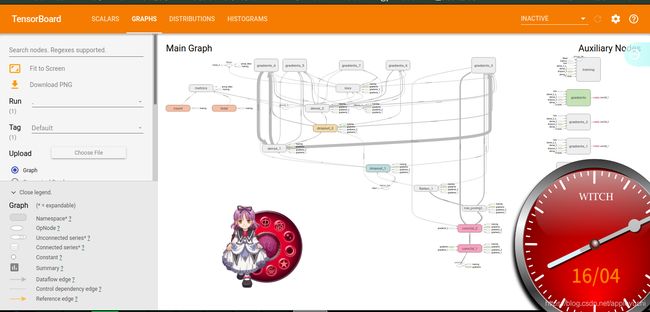
#--------------------------------------------------------------------------------------------------
补充说下像深脑链的GPU服务器是不行的,因为它除了提供连接用的端口以外,
没有其他端口供tensorboard显示使用,因此是无法在浏览器远程访问tensorboard的。
#---------------------------------------------------------附录---------------------------------------------------------------------------------------
test.py
import numpy as np
from keras.models import Sequential # 采用贯序模型
from keras.layers import Input, Dense, Dropout, Activation,Conv2D,MaxPool2D,Flatten
from keras.optimizers import SGD
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.callbacks import TensorBoard
def create_model():
model = Sequential()
model.add(Conv2D(32, (5,5), activation='relu', input_shape=[28, 28, 1])) #第一卷积层
model.add(Conv2D(64, (5,5), activation='relu')) #第二卷积层
model.add(MaxPool2D(pool_size=(2,2))) #池化层
model.add(Flatten()) #平铺层
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
#sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer="adam",metrics=['acc'])
return model
def train_model(model,x_train,y_train,batch_size=128,epochs=10):
#构造一个tensorboard类的对象
#tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1, write_graph=True, write_images=True,update_freq="epoch")
tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1,write_grads=True)
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2, validation_split=0.2,callbacks=[tbCallBack])
return history,model
if __name__=="__main__":
(x_train,y_train),(x_test,y_test) = mnist.load_data() #mnist的数据我自己已经下载好了的
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test))
x_train=np.expand_dims(x_train,axis=3)
x_test=np.expand_dims(x_test,axis=3)
y_train=to_categorical(y_train,num_classes=10)
y_test=to_categorical(y_test,num_classes=10)
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test))
model=create_model()
model=compile_model(model)
history,model=train_model(model,x_train,y_train)
符号意义列表
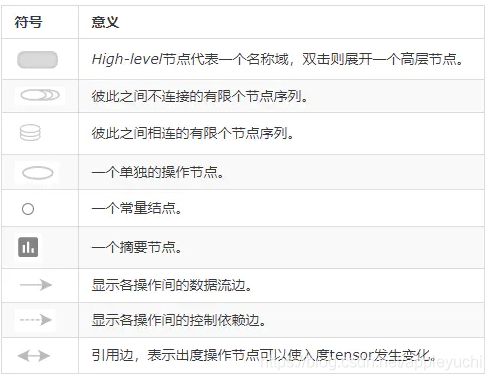
注意事项:
出现显存占满、而GPU利用率为0的情况,经查阅官方文档得知“在GPU上,tf.Variable操作只支持实数型(float16 float32 double)的参数。不支持整数型参数”
通过allow_soft_placement参数自动将无法把GPU上的操作放回CPU上