NLP任务之情感分类
文章目录
- 背景
- 流程
-
- 第一步:统计单词数分布(数据可视化)
- 第二步:预处理
- 第三步:定义模型
- 第四步:训练
- 第五步:测试
- 参考
背景
使用pytorch框架下的CNN、RNN,并使用词向量,完成情感分类。使用的语料集如下:


链接
提取码:5uvl
流程
第一步:统计单词数分布(数据可视化)
from collections import Counter
import matplotlib.pyplot as plt
len_lst = []
with open(r"train_positive.txt",'r',encoding = "utf-8 ") as F:
text = F.read()
text_splited1 = text.split("\n")
for sentence in text_splited1:
len_lst.append(len(sentence.split()))
with open(r"train_negative.txt",'r',encoding = "utf-8 ") as F:
text = F.read()
text_splited1 = text.split("\n")
for sentence in text_splited1:
len_lst.append(len(sentence.split()))
len_dict = dict(Counter(len_lst).most_common())
y = [0 for i in range(8)]
x = [i for i in range(1,9)]
# <10
for key in len_dict:
if key < 100:
y[0] += len_dict[key]
elif 100 <= key < 200:
y[1] += len_dict[key]
elif 200 <= key < 300:
y[2] += len_dict[key]
elif 300 <= key < 400:
y[3] += len_dict[key]
elif 400 <= key < 500:
y[4] += len_dict[key]
elif 500 <= key < 600:
y[5] += len_dict[key]
elif 600 <= key < 700:
y[6] += len_dict[key]
elif key >= 700:
y[7] += len_dict[key]
lenth = len(y)
for idx in range(lenth):
y[idx] /= sum(len_dict.values())
print(sum(y))
plt.bar(x, y, facecolor="blue", edgecolor="white")
for x1, y1 in zip(x,y):
plt.text(x1, y1, '%.3f' % y1, ha="center", va="bottom", fontsize=7)
new_xticks = [r"<100",r"100-200",r"200-300",r"300-400",r"400-500",r"500-600",r"600-700",r">=700"]
plt.xticks(x,new_xticks)
plt.show()
读取train的所有样本,统计单词数分布,以便确定max_len,得到的统计图如下:
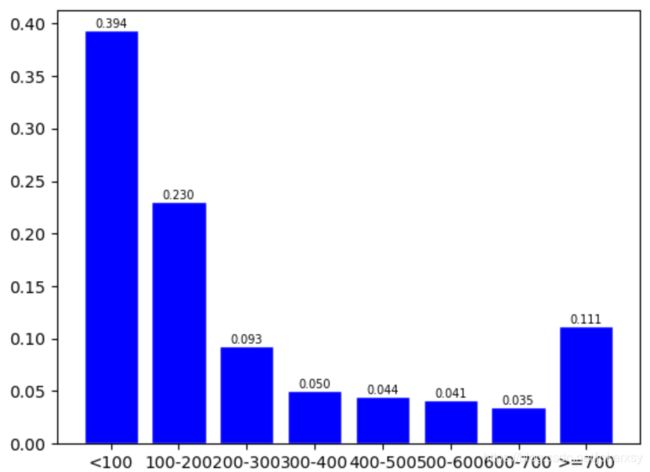
由图可知:89%的句子长度小于700。
第二步:预处理
- 使用gensim库加载word2vec预训练模型,其中的glove_file是glove词向量的本地路径、out_path是glove转为word2vec后的输出路径、model_path是预训练词向量模型生成以后的保存路径,我的分别是:“glove.6B.100d.txt”,r"glove2word2vec.txt",“word2vec_model”。
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
def get_word2vec_model(glove_file,out_path,model_path):
if os.path.exists(model_path):
print("has already existed!")
pass
glove2word2vec(glove_file,out_path)
model = KeyedVectors.load_word2vec_format(out_path)
model.save(model_path)
print("ready!")
get_word2vec_model(r"glove.6B.100d.txt",r"glove2word2vec.txt","word2vec_model")
- 读取数据
def load_training_data(path):
with open(path, "r", encoding="utf-8") as F:
lines = F.readlines()
x = [line.strip("\n").split(" ") for line in lines]
lenth = len(x)
if "negative" in path:
y = [0] * lenth
else:
y = [1] * lenth
return x,y
train_pos_x,train_pos_y = load_training_data(r"train_positive.txt")
train_neg_x, train_neg_y = load_training_data(r"train_negative.txt")
test_pos_x, test_pos_y = load_training_data(r"test_positive.txt")
test_neg_x, test_neg_y = load_training_data(r"test_negative.txt")
- 初始化自定义的预处理类,建立embedding矩阵,并处理所有数据
class Preprocess():
def __init__(self,sen_len, w2v_path="../model/word2vec_model"):
self.w2v_path = w2v_path # 之前生成的word2vec模型的路径
self.sen_len = sen_len # max_len
self.idx2word = []
self.word2idx = {
}
self.embedding_matrix = []
# 读模型
def get_w2v_model(self):
self.embedding = KeyedVectors.load(self.w2v_path)
self.embedding_dim = self.embedding.vector_size
# 增加pad或unk
def add_embedding(self, word):
vector = torch.empty(1,self.embedding_dim)
torch.nn.init.uniform_(vector)
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix = torch.cat([self.embedding_matrix,vector],dim = 0)
# 构造embedding
def make_embedding(self, load=True):
# if os.path.exists(r"../data/embedding_matrix.npy"):
# self.embedding_matrix = torch.from_numpy(np.load(r"../data/embedding_matrix.npy"))
# return self.embedding_matrix
print("loading word2vec_model")
if load:
self.get_w2v_model()
for i,word in enumerate(self.embedding.wv.vocab):
# print("get words{}".format(i))
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix.append(self.embedding[word])
print("")
self.embedding_matrix = torch.tensor(self.embedding_matrix)
self.add_embedding("" )
self.add_embedding("" )
print("total words{}".format(len(self.embedding_matrix)))
return self.embedding_matrix
# 根据word2vec和sen_len来padding
def pad_sequence(self, sentence):
if len(sentence) > self.sen_len:
sentence = sentence[:self.sen_len]
else:
pad_len = self.sen_len - len(sentence)
for _ in range(pad_len):
sentence.append(self.word2idx["" ])
assert len(sentence) == self.sen_len
return sentence
# word 2 index
def sentence_word2idx(self,sentences):
# 把句子裡面的字轉成相對應的index
sentence_list = []
for i, sen in enumerate(sentences):
# print('sentence count #{}'.format(i+1), end='\r')
sentence_idx = []
for word in sen:
if (word in self.word2idx.keys()):
sentence_idx.append(self.word2idx[word])
else:
sentence_idx.append(self.word2idx["" ])
# 將每個句子變成一樣的長度
sentence_idx = self.pad_sequence(sentence_idx)
sentence_list.append(sentence_idx)
print("totel sentences{}".format(len(sentence_list)))
return torch.LongTensor(sentence_list)
def labels_to_tensor(self, y):
# 把labels轉成tensor
y = [int(label) for label in y]
return torch.LongTensor(y)
X,Y = train_pos_x+train_neg_x+test_pos_x+test_neg_x,train_pos_y+train_neg_y+test_pos_y+test_neg_y
preprocess = Preprocess(sen_len,w2v_path="word2vec_model")
embedding_weight = preprocess.make_embedding()
X = preprocess.sentence_word2idx(X)
Y = preprocess.labels_to_tensor(Y)
- 分割训练集、验证集和测试集
IDX = np.arange(0,len(X))
import random
random.shuffle(IDX)
train_idx = IDX[:7000]
valid_idx = IDX[7000:8000]
test_idx = IDX[8000:]
train_x,train_y,valid_x,valid_y,test_x,test_y = X[train_idx],Y[train_idx],X[valid_idx],Y[valid_idx],X[test_idx],Y[test_idx]
- 封装成dataloader
from torch.utils.data import TensorDataset,DataLoader
train_loader = DataLoader(TensorDataset(train_x,train_y),shuffle=True,batch_size=bs)
valid_loader = DataLoader(TensorDataset(valid_x, valid_y), shuffle=True, batch_size=bs)
第三步:定义模型
class LstmNet(torch.nn.Module):
def __init__(self,embedding_weight,hidden_dim,num_layers,dropout=0.5,fix_embedding = True):
super(LstmNet,self).__init__()
self.embedding = torch.nn.Embedding(embedding_weight.size(0),embedding_weight.size(1))
requires_grad = True if fix_embedding == False else False
self.embedding.weight = torch.nn.Parameter(embedding_weight,requires_grad = requires_grad)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.dropout = dropout
self.embedding_dim = embedding_weight.size(1)
self.lstm = torch.nn.LSTM(self.embedding_dim,hidden_dim,num_layers=num_layers,batch_first=True)
self.classify = torch.nn.Sequential(
torch.nn.Dropout(dropout),
torch.nn.Softsign(),
torch.nn.Linear(hidden_dim,1),
torch.nn.Sigmoid()
)
def forward(self,inputs):
inputs = self.embedding(inputs)
x,_ = self.lstm(inputs,None)
x = x[:,-1,:]
x = self.classify(x)
return x
model = LstmNet(embedding_weight,hidden_dim=100,num_layers=1,dropout=0.5,fix_embedding=True)
第四步:训练
def train(epochs,bs,lr,train_loader,valid_loader,model,model_path = r"bestLSTM.model"):
total = sum(para.numel() for para in model.parameters())
trainable = sum(para.numel() for para in model.parameters() if para.requires_grad)
t_batch = len(train_loader)
v_batch = len(valid_loader)
best_acc = 0
loss_fn = torch.nn.BCELoss()
optim = torch.optim.Adam(model.parameters(),lr = lr)
# optim = torch.optim.SGD(model.parameters(),lr=lr,momentum=.9)
print("total parameters{} , trainable{}".format(total,trainable))
model.train()
model.dropout = 0.5
for epoch in range(epochs):
flag = 0
if flag == 1:
break
total_loss = 0
total_acc = 0
for i,(xb,yb) in enumerate(train_loader):
# torch.nn.utils.clip_grad_norm(model.parameters(),max_norm=,norm_type=2)
yb = yb.to(dtype = torch.float)
outputs = model(xb)
outputs = outputs.squeeze()
loss = loss_fn(outputs,yb)
optim.zero_grad()
loss.backward()
optim.step()
correct = evaluation(outputs, yb) # 計算此時模型的training accuracy
total_acc += (correct / bs)
total_loss += loss.item()
if (i+1) % 20 == 0:
print('[ Epoch{}: {}/{} ] Loss:{:.3f} acc:{:.3f} '.format(epoch+1, i+1, t_batch, loss.item(), correct/bs*100), end='\n')
print('\nTrain | Loss:{:.5f} Acc: {:.3f}'.format(total_loss / t_batch, total_acc / t_batch * 100))
total_loss,total_acc = 0,0
model.dropout = 0.0
for i,(xb,yb) in enumerate(valid_loader):
yb = yb.to(dtype=torch.float)
model.eval()
outputs = model(xb)
outputs = outputs.squeeze()
loss = loss_fn(outputs,yb)
correct = evaluation(outputs,yb)
total_acc += correct/bs
total_loss += loss.item()
if total_acc > best_acc:
# 如果validation的結果優於之前所有的結果,就把當下的模型存下來以備之後做預測時使用
best_acc = total_acc
# torch.save(model, "{}/val_acc_{:.3f}.model".format(model_dir,total_acc/v_batch*100))
if os.path.exists(model_path):
os.remove(model_path)
torch.save(model, model_path)
print('saving model with acc {:.3f}'.format(total_acc / v_batch * 100))
if (total_acc / v_batch * 100) >= 75.0:
flag = 1
break
model.train()
model.dropout = 0.5
train(epochs=epochs,bs=bs,lr = lr,train_loader = train_loader,valid_loader=valid_loader,model=model)
结果如下:
total parameters40081202 , trainable81002
[ Epoch1: 20/219 ] Loss:0.672 acc:65.625
[ Epoch1: 40/219 ] Loss:0.692 acc:50.000
[ Epoch1: 60/219 ] Loss:0.678 acc:62.500
[ Epoch1: 80/219 ] Loss:0.699 acc:40.625
[ Epoch1: 100/219 ] Loss:0.702 acc:53.125
[ Epoch1: 120/219 ] Loss:0.674 acc:65.625
[ Epoch1: 140/219 ] Loss:0.680 acc:56.250
[ Epoch1: 160/219 ] Loss:0.716 acc:37.500
[ Epoch1: 180/219 ] Loss:0.681 acc:56.250
[ Epoch1: 200/219 ] Loss:0.691 acc:56.250
第五步:测试
test_loader = DataLoader(TensorDataset(test_x,test_y),shuffle=True,batch_size=bs)
model = torch.load("bestLSTM.model")
test(test_loader=test_loader,model=model,bs=bs)
参考
pytorch常见层的官方文档说明
pytorch常见层介绍
pytorch 一般训练过程
官方给出的一个文本分类(情感分类)例子,使用的是词袋模型
一个textcnn进行文本分类的例子
pytorch加载词向量