Flink未来-将与 Pulsar集成提供大规模的弹性数据处理
问题导读
1.什么是Pulsar?
2.Pulsar都有哪些概念?
3.Pulsar有什么特点?
4.Flink未来如何与Pulsar整合?
Apache Flink和Apache Pulsar的开源数据技术框架可以以不同的方式集成,以提供大规模的弹性数据处理。 在这篇文章中,我将简要介绍Pulsar及其与其他消息传递系统的差异化元素,并描述Pulsar和Flink可以协同工作的方式,为大规模弹性数据处理提供无缝的开发人员体验。
Pulsar简介
Apache Pulsar是一个开源的分布式pub-sub消息系统,由Apache Software Foundation管理。 Pulsar是一种用于服务器到服务器消息传递的多租户,高性能解决方案,包括多个功能,例如Pulsar实例中对多个集群的本地支持,跨集群的消息的无缝geo-replication,非常低的发布和端到端 - 延迟,超过一百万个主题的无缝可扩展性,以及由Apache BookKeeper等提供的持久消息存储保证消息传递。现在让我们讨论Pulsar和其它pub-sub消息传递框架之间的主要区别:
第一个差异化因素源于这样一个事实:虽然Pulsar提供了灵活的pub-sub消息传递系统,但它也有持久的日志存储支持 - 因此在一个框架下结合了消息传递和存储。由于采用了分层架构,Pulsar提供即时故障恢复,独立可扩展性和无平衡的集群扩展。
Pulsar的架构遵循与其他pub-sub系统类似的模式,因为框架在主题中被组织为主要数据实体,生产者向主体发送数据,消费者从主题(topic)接收数据,如下图所示。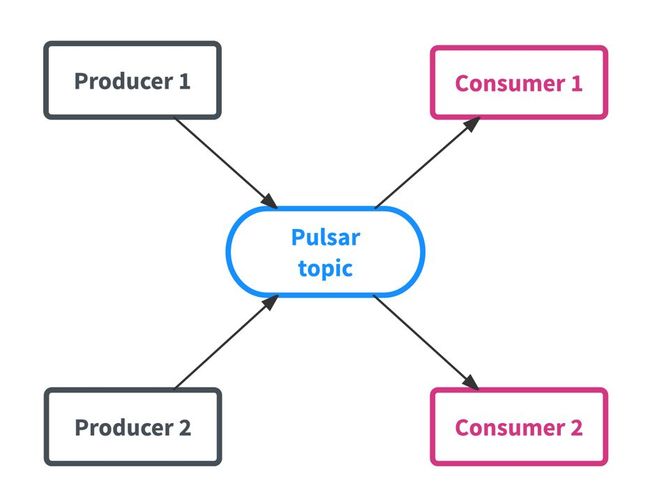
Topic是Pulsar的核心概念,表示一个“channel”,Producer可以写入数据,Consumer从中消费数据(Kafka、RocketMQ都是这样)。
Topic名称的URL类似如下的结构:
{persistent|non-persistent}://tenant/namespace/topic
persistent|non-persistent表示数据是否持久化(Pulsar支持消息持久化和非持久化两种模式)
Tenant为租户
Namespace一般聚合一系列相关的Topic,一个租户下可以有多个Namespace
Pulsar的第二个区别是该框架是从一开始就考虑多租户而构建的。 这意味着每个Pulsar主题都有一个分层的管理结构,使得资源的分配以及团队之间的资源管理和协调变得高效和容易。 借助Pulsar的多租户结构,数据平台维护人员可以在没有摩擦的情况下加入新团队,因为Pulsar在属性(租户),命名空间或主题级别提供资源隔离,同时数据可以在集群中共享以便于协作和 协调。
下图中Property即为租户,每个租户下可以有多个Namespace,每个Namespace下有多个Topic。
Namespace是Pulsar中的操作单元,包括Topic是配置在Namespace级别的,包括多地域复制,消息过期策略等都是配置在Namespace上的。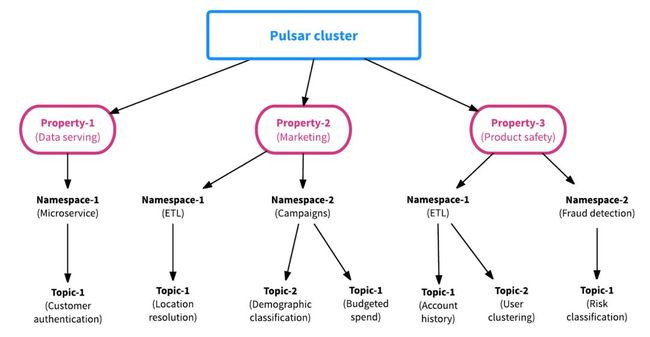
最后,Pulsar灵活的消息传递框架统一了流式和排队数据消费模型,并提供了更大的灵活性。 如下图所示,Pulsar保存主题中的数据,而多个团队可以根据其工作负载和数据消耗模式独立使用数据。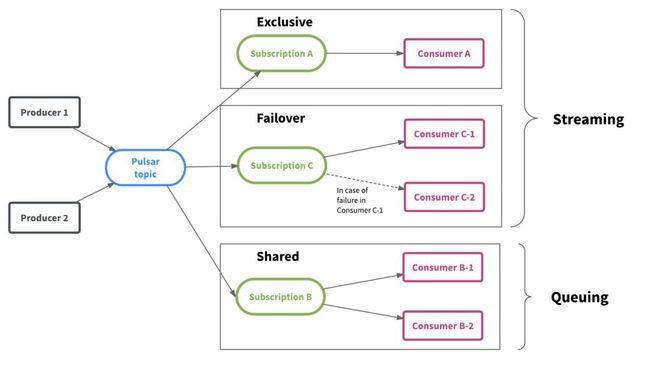
Pulsar提供了灵活的消息模型,支持三种订阅类型:
Exclusive subscription:排他的,只能有一个Consumer,接收一个Topic所有的消息
Shared subscription:共享的,可以同时存在多个Consumer,每个Consumer处理Topic中一部消息(Shared模型是不保证消息顺序的,Consumer数量可以超过分区的数量)
Failover subscription:Failover模式,同一时刻只有一个有效的Consumer,其余的Consumer作为备用节点,在Master Consumer不可用后进行替代(看起来适用于数据量小,且解决单点故障的场景)
Pulsar对数据的看法:分段数据流
Apache Flink是一个流优先计算框架,它将批处理视为流的特殊情况。 Flink对数据流的看法区分了有界和无界数据流之间的批处理和流处理,假设对于批处理工作负载,数据流是有限的,具有开始和结束。
对于数据层,Apache Pulsar与Apache Flink的观点相似。 该框架还使用流作为所有数据的统一视图,而其分层体系结构允许传统的pub-sub消息传递用于流式工作负载和连续数据处理或分段流的使用以及批量和静态工作负载的有界数据流。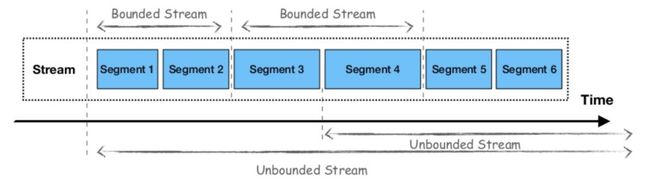
使用Pulsar,一旦生产者向主题(topic)发送数据,它就会根据数据流量进行分区,然后在这些分区下进一步细分 - 使用Apache Bookkeeper作为分段存储 - 以允许并行数据处理,如下图所示。 这允许在一个框架中组合传统的pub-sub消息传递和分布式并行计算。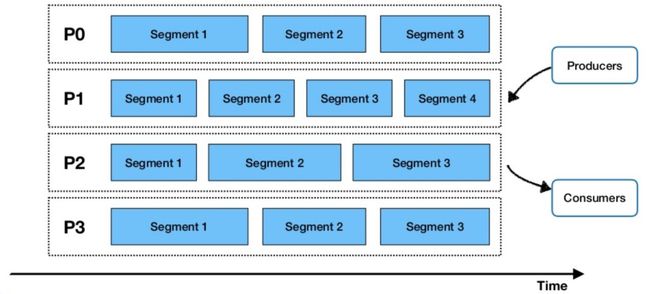
当Flink + Pulsar整合
Apache Flink和Apache Pulsar已经以多种方式集成。在接下来的部分中,我将介绍框架之间的一些潜在的未来集成,并分享可以一起使用框架的现有方法的示例。
未来整合
Pulsar可以以不同的方式与Apache Flink集成。一些潜在的集成包括使用流式连接器为流式工作负载提供支持,并使用批量源连接器支持批量工作负载。 Pulsar还提供对schema 的本地支持,可以与Flink集成并提供对数据的结构化访问,例如使用Flink SQL作为在Pulsar中查询数据的方式。最后,集成这些技术的另一种方法可能包括使用Pulsar作为Flink的状态后端。由于Pulsar具有分层架构(Streams和Segmented Streams,由Apache Bookkeeper提供支持),因此将Pulsar用作存储层并存储Flink状态变得很自然。
从体系结构的角度来看,我们可以想象两个框架之间的集成,它使用Apache Pulsar作为统一的数据层视图,Apache Flink作为统一的计算和数据处理框架和API。
现有集成
两个框架之间的集成正在进行中,开发人员已经可以通过多种方式将Pulsar与Flink结合使用。例如,Pulsar可用作Flink DataStream应用程序中的流媒体源和流式接收器。开发人员可以将Pulsar中的数据提取到Flink作业中,该作业可以计算和处理实时数据,然后将数据作为流式接收器发送回Pulsar主题。这样的例子如下所示:
[Scala] 纯文本查看 复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// create and configure Pulsar consumer
PulsarSourceBuilder
=
PulsarSourceBuilder
.builder(
new
SimpleStringSchema())
.serviceUrl(serviceUrl)
.topic(inputTopic)
.subscriptionName(subscription);
SourceFunction
=
builder.build();
// ingest DataStream with Pulsar consumer
DataStream
=
env.addSource(src);
// perform computation on DataStream (here a simple WordCount)
DataStream
=
words
.flatMap((FlatMapFunction
collector.collect(
new
WordWithCount(word,
1
));
})
.returns(WordWithCount.
class
)
.keyBy(
"word"
)
.timeWindow(Time.seconds(
5
))
.reduce((ReduceFunction
1
, c
2
) ->
new
WordWithCount(c
1
.word, c
1
.count + c
2
.count));
// emit result via Pulsar producer
wc.addSink(
new
FlinkPulsarProducer<>(
serviceUrl,
outputTopic,
new
AuthenticationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes(UTF
_
8
),
wordWithCount -> wordWithCount.word)
);
|
开发人员可以利用的两个框架之间的另一个集成包括将Pulsar用作Flink SQL或Table API查询的流式源和流式表接收器,如下例所示:
[Scala] 纯文本查看 复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// obtain a DataStream with words
DataStream
=
...
// register DataStream as Table "words" with two attributes ("word", "ts").
// "ts" is an event-time timestamp.
tableEnvironment.registerDataStream(
"words"
, words,
"word, ts.rowtime"
);
// create a TableSink that produces to Pulsar
TableSink sink
=
new
PulsarJsonTableSink(
serviceUrl,
outputTopic,
new
AuthenticationDisabled(),
ROUTING
_
KEY);
// register Pulsar TableSink as table "wc"
tableEnvironment.registerTableSink(
"wc"
,
sink.configure(
new
String[]{
"word"
,
"cnt"
},
new
TypeInformation[]{Types.STRING, Types.LONG}));
// count words per 5 seconds and write result to table "wc"
tableEnvironment.sqlUpdate(
"INSERT INTO wc "
+
"SELECT word, COUNT(*) AS cnt "
+
"FROM words "
+
"GROUP BY word, TUMBLE(ts, INTERVAL '5' SECOND)"
);
|
最后,Flink将批量工作负载与Pulsar集成为批处理接收器,其中所有结果在Apache Flink完成静态数据集中的计算后被推送到Pulsar。 这样的例子如下所示:
[Scala] 纯文本查看 复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
|
// obtain DataSet from arbitrary computation
DataSet
=
...
// create PulsarOutputFormat instance
OutputFormat pulsarOutputFormat
=
new
PulsarOutputFormat(
serviceUrl,
topic,
new
AuthenticationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes());
// write DataSet to Pulsar
wc.output(pulsarOutputFormat);
|
结论
Pulsar和Flink都对应用程序的数据和计算级别如何以批量作为特殊情况流“流式传输”方式分享了类似的观点。 通过Pulsar的Segmented Streams方法和Flink在一个框架下统一批处理和流处理工作负载的步骤,有许多方法将这两种技术集成在一起,以提供大规模的弹性数据处理。
每天进步一点点,欢迎关注公众号
↑ 翘首以盼等你关注
----------------------------END----------------------------
1.about云知识星球介绍:根据大家的需求,分享经典资源,经验,面试简历,知识总结等。
2.加好友,附上“领书”或则“领取100本大数据、人工智能、区块链资料”;

本公众号精彩文章推荐:
【1】Flink1.8新版发布:都有哪些改变
【2】我面试了我的前领导,他连做我的下属都不配
【3】技术太多学不过来?教你如何越学越带劲
【4】IT大咖工作十年总结的面试真经
【5】小白与大神存在哪些差距
【6】腾讯大数据面试及参考答案
【7】kafka学习线路指导入门:包括理论、部署、实战知识汇总整理
【8】技术走向管理一些深度思考