Spark on Yarn
承接上一篇文档《Spark案例练习-打包提交》
将spark应用运行在yarn集群上
官网地址:http://spark.apache.org/docs/2.0.2/running-on-yarn.html
1. 在spark-env.sh中配置HADOOP_CONF_DIR 或者 YARN_CONF_DIR

HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.7.3/etc/hadoop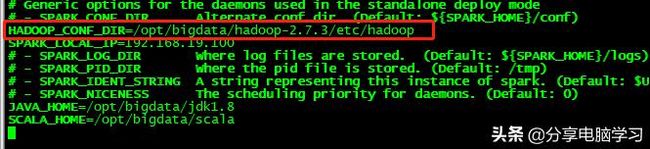
2. 启动hdfs和yarn
./sbin/start-yarn.sh 
3. 测试运行
浏览器访问master:8088
在8088端口下(yarn的UI下)查看下面语句的效果:
默认部署模式是client
执行命令
./bin/spark-submit \
--class 全包.类名 \
--master yarn \
jar包位置这里遇到了一个错误
ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state FINISHED!查了一下是因为内存分配不够导致的yarn强行关闭
往yarn-site.xml中加入
yarn.nodemanager.vmem-check-enabled
false
重启hadoop即可解决

在8088端口下(yarn的UI下)查看下面语句的效果:
运行代码
用cluster模式运行
./bin/spark-submit \
--class 全包.类名\
--master yarn \
--deploy-mode cluster \jar包位置

![]()
集群部署的时候如果不成功,将logpvuv.jar放在hadoop-2.7.3/share/hadoop/common/lib或者/hadoop-2.7.3/share/hadoop/yarn/lib下面(我成功了,所以没有做这一步)
4. 在standalone集群运行spark应用的时候,指定一些资源(内存、CPU)
client模式执行的命令:
./bin/spark-submit \
--class 全包.LogPVAndUVCount \
--master spark://master:7070 \
/opt/modules/jar/logpvuv.jar
1、--driver-memory 指定driver的内存,client模式一般不指定,cluster部署模式的话,如果你在代码中调用rdd.collect,并且rdd的数据量很大的话,那么可以指定一下该参数
2、--executor-memory 指定每个executor的内存,Default: 1G
3、--total-executor-cores 指定所有的executor总共需要的core
4、--executor-cores 每个executor需要的core的数量
命令:
./bin/spark-submit \
--class 全包.LogPVAndUVCount \
--master spark://master:7070 \
--total-executor-cores 3 \
--executor-cores 1 \
--executor-memory 512m \
/opt/modules/jar/logpvuv.jar

对应我们得到配置,这里要注意一下资源分配的问题
total-executor-cores*executor-memory不可以大于分配给spark的内存
如果大于会出警告,程序会一直暂停

注意:
每个executor的内存不可以超过单个Worker节点上所有可使用的内存
单个executor的core数也不可以超过单个Worker节点上所有可使用的core数
部署模式是cluster模式时,查看UI界面的变化(对比client模式):
./bin/spark-submit \
--class 全包.LogPVAndUVCount \
--master spark://master:6066 \
--deploy-mode cluster \
--driver-cores 2 \
/opt/modules/jar/logpvuv.jar
对比可以发现,cluster会根据你所给定的core数自动分配内存
我配置的内存是2g,所以每个core所分配到的内存是1024MB(1G)
还有几个参数:
在yarn集群的时候
--num-executors 指定executor的数量
--executor-cores 指定每个executor的core的数量
例如:
假设spark应用RDD有50分区
--num-executors 10
--executor-cores 5
二、Spark on yarn Job History服务配置
1.前提:yarn-site.xml中开启日志聚集功能
yarn.log-aggregation-enable
true
yarn.log.server.url
http://master:19888/jobhistory/logs

2. 配置并且启动spark的job history server
./sbin/start-history-server.sh
查看HistoryServer这个进程
对应的UI界面:http://master:18080/



3. 启动yarn的job history server
先进入hadoop的安装目录
执行
./sbin/mr-jobhistory-daemon.sh start historyserver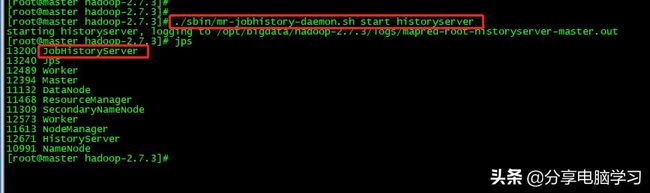
查看JobHistoryServer进程
对应的UI界面:
http://master:19888/jobhistory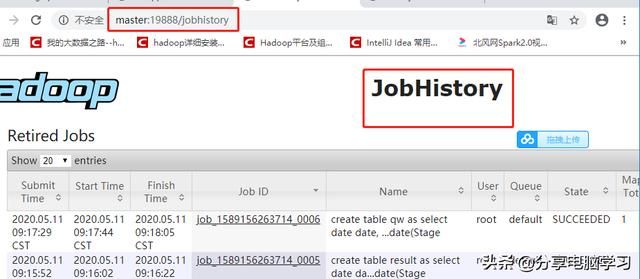
4.修改spark应用的配置文件spark-default.conf
spark.yarn.historyServer.address http://master:18080

5.测试一个spark on yarn(前面的例子执行查看下就好)
./bin/spark-submit \
--class 全包.类名\
--master yarn \
jar包位置
![]()

三、如果要加载配置
参数:--properties-file xxxx.properties(文件名)
xxxx.properties里面的内容示例:
spark.yarn.historyServer.address(空格)http://master:18080
注意:这个配置文件中的属性必须是以spark开头
配置文件的写法 spark.* xxxx属性值,属性名称与属性值中间用一个空格隔开
关注公众号:分享电脑学习
回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新)
云盘目录说明:
tools目录是安装包
res 目录是每一个课件对应的代码和资源等
doc 目录是一些第三方的文档工具