【CTR预估】DSIN模型
最近看了一篇文章‘Deep Session Interest Network for Click-Through Rate Prediction’, 这篇是阿里发表在IJCAI2019的文章。
文章地址:https://arxiv.org/abs/1905.06482
作者还开源了代码:https://github.com/hhh920406/DSIN
淘宝最近也公开了一个rank模型,和这个有一点点像,也可以看看,模型要比这个要简单点:https://mp.weixin.qq.com/s/1y8jTqCcI7HkMA3qXtqdIg
模型是用于CTR预估的,整个模型在传统的DNN模型基础上,加上了tranformer结构和Bi-LSTM来分别捕捉session内和session间的内在联系,最后通过attention机制对目标item和由两个结构生成的session内顺序信息和session之间顺序信息加权输出,和用户画像embedding,以及item画像embedding一起concate起来,送入MLP里做分类。整体给我的感觉是思路很棒,但是感觉这个预估模型有点重,像我这种小公司的线上服务rt还不一定能用起来......
Based model
文章先大概介绍了一下使用DNN来构造ctr预估模型的一个基本框架。
1.embedding。这个是必须的,一般稀疏类别特征,不出意外都可以用embedding来操作。这个一方面可以降低输入的维度,还可以将特征映射到高纬空间学习出不同特征值之间的距离,而不是像onehot一样,每个特征值都一样。当然还有好多优点,比如方便后续计算,使用;方便将不同域的特征映射到同一空间进行比较等等,优点多多。
2.MLP。基本上将稀疏类别特征embedding化后,和稠密特征一起concate起来就可以直接送入神经网络,进行训练,这样就可以组成一个基本的DNN网络,用于分类,回归等。
DSIN模型

如上图所示是模型的整体结构,左侧的User Field 和Item Field就是上面说的稀疏类别特征的embedding和稠密特征的组合,这里按user和item做了区分。文章的核心工作在右边这块。
从下到上
Session Divsion Layer
这块的工作是将用户的历史行为划分成不同session,将历史行为的items以三十分钟为界,划分成不同的session。并且为了保持维度的一致,每个session的长度是一致的,多了的截断,少了的按0填充。session的个数也保持一致。

Q就是一个session,b表示session的行为。
Session Interest Extractor Layer
这一步的目的就是去捕获session list中每个session内部的行为关系。将session作为输入,送入tranformer结构。
session在送入tranformer之前使用了一个操作Bias Encoding.
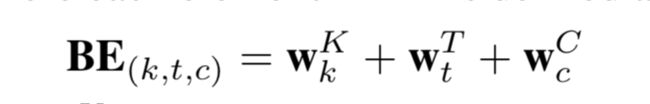
用了三个矩阵分别对session本身,session中的每个位置,每个位置处id的embedding的每个维度都加上了一个偏置项。源码如下:

然后将偏置项加入到输入的session list中


这一步应该算是对原始tranformer中position encoding的优化,利用偏置项来区分不同位置session,不同位置的item,以及不同位置的embedding值。
接着把经过Bias Encoding处理的输入session list传入tranformer结构里:

tranformer输出的结果被再次输入一个前向网络里面做了一层映射
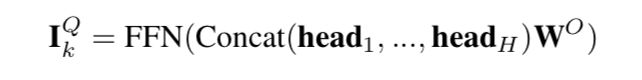
然后再用average pooling把每个session的维度进行压缩:
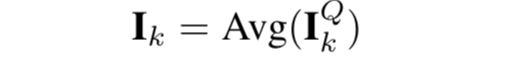
到这为止,或得到了每个session的一个内在表示,就是图里面的:

Session Interest Interacting Layer
文章为了捕获不同session之间的顺序关系,使用了Bi-LSTM。Bi-LSTM是双向的,可以同时捕获上下文关系。
因此经过Bi-LSTM编码的输入,每个维度的输出向量其实都包含了输入数据同一位置的前后信息。这步获得的数据是图中的:

到这为止,模型已经同时捕获到了session内部和session之间的顺序关系。如果想简单一点,直接把这两者的输出结果和图中左侧的画像特征concate起来也可以。不过文章作者在concate前对两者的输出做了一层attention,用来判断sesison信息和目标item之间的相关性。
Session Interest Activating Layer

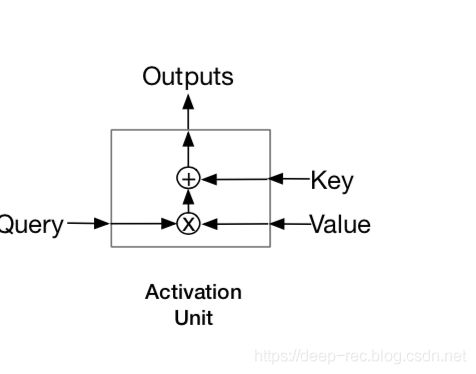
attention的query就是公式中的X,就是目标item的embedding。item的embedding是item画像特征所有embedding一起concate起来获得的。value和key就是前面获得两个输出I和H。
最后把以上这些向量都组合起来送入DNN中进行训练。
文章总的来说,思路清晰,之前看过一些文章基本只会去考虑session内部的关系,很少有考虑session之间的关系,还把NLP中的tranformer模型用到了ctr预估。