【译文】RangeNet++: Fast and Accurate LiDAR Semantic Segmentation
RangeNet++:快速准确的激光雷达语义分割
2019机器人顶会IROS
作者:Andres Milioto
SuMa++这篇SLAM文章看视频效果很不错,而且有开源的Qt代码,向大神学习(不过早早从slam弃坑了…)
摘要
自动驾驶汽车的感知通常是通过一系列不同的传感方式来实现的。考虑到大量公开可用的标记RGB数据,以及基于图像识别的高质量深度学习算法的出现,高级语义感知任务将首先由高分辨率摄像机解决。因此,其他可能对这项任务有用的传感器模式常常被忽略。在这篇论文中,我们将目前仅针对激光雷达的语义分割技术向前推进,以便为车辆提供另一个独立的语义信息来源。该方法能够准确地对激光雷达点云进行全语义分割。我们利用距离图像作为中间表示,并结合利用旋转激光雷达传感器模型的卷积神经网络(CNN)。为了获得准确的结果,我们提出了一种新的后处理算法来处理这种中间表示产生的问题,如离散化误差和模糊的CNN输出。我们实现并彻底评估了我们的方法,包括与当前技术状态的几次比较。我们的实验表明,我们的方法优于最先进的方法,同时也能在一个嵌入式GPU上运行。
代码:https://github.com/PRBonn/lidar-bonnetal
1 介绍
语义场景理解是自动机器人在动态真实环境下工作的关键构件之一。为了实现所需的场景理解,机器人通常配备多个传感器,以便利用每种模式的优势。结合多种互补的传感模式,可以补充单个传感器的缺点,如相机、激光扫描仪或雷达。这在自动驾驶的环境中尤为重要,在这种情况下,一种模式的失败可能会造成致命的或显著的金钱损失,如果它没有被另一个冗余传感器适当弥补。
语义场景理解的一个重要任务是语义分割。语义分割为输入模式中的每个数据点分配一个类标签,即,在相机中为像素,或在激光雷达中为三维点。在这篇论文中,我们明确地解决了旋转三维LiDARs的语义分割问题,例如常用的Velodyne。不幸的是,目前最先进的激光雷达数据语义分割方法,要么没有足够的表征能力来处理这项任务,要么在移动GPU上以帧速率运行太昂贵。这使得它们不适合辅助支持自动驾驶汽车的任务,解决这些问题是这项工作的目标。我们的方法推断图像的每个像素的完整的语义分割使用任何CNN作为骨干。这产生了一个有效的方法,但会导致离散化或模糊CNN输出的问题。我们通过对原始点的语义重构有效地解决了这些问题,而不需要丢弃原始点云中的任何点,无论基于图像的CNN使用的分辨率如何。这个后处理步骤也是在线运行的,它对图像表示进行操作,并针对效率进行调整。我们可以在恒定的时间内计算每个点的最近邻,并利用基于gpu的计算。这使得我们能够准确地推断出激光雷达点云的完整语义分割,并且比传感器的帧速率更快。由于这种方法可以在任何基于范围图像的CNN主干上运行,所以我们称之为RangeNet++。示例如图1所示。
总之,我们提出了三个关键的主张:我们的方法能够
(1)准确地执行纯激光雷达点云的语义分割,显著地超越了目前的技术水平,
(2)推断完整的原始点云的语义标签,避免丢弃点,而不管CNN使用的离散化程度如何,
(3)在嵌入式计算机上以Velodyne的帧率工作,这很容易在机器人或车辆中实现。
2 文献综述
近年来,随着深度学习技术的出现,以及越来越多的大规模数据集的出现,例如CamVid[2]、Cityscapes[4]或Mapillary[12],利用图像进行自动驾驶的语义分割取得了巨大的进展。这使得生成具有数百万参数的复杂深度神经网络体系结构能够获得高质量的结果。突出的例子是Deeplab V3[3]和PSPNet[23]。
尽管它们的结果令人印象深刻,但这些架构的计算量太大,无法在自驾系统上实时运行,而自驾系统必须利用语义线索进行导航。这催生了更有效的方法,如Bonnet[11]、ENet[13]、ERFNet[17]和Mobilenets V2[18],它们利用收益递减定律,在运行时、参数数量和准确性之间进行最佳权衡。然而,这些是为图像而不是为激光雷达扫描而设计的。
到目前为止,将这些结果转换成激光雷达数据受到两个因素的阻碍:
(i)在自动驾驶中缺乏用于语义分割任务的公开可用的大规模数据集;
(ii)运行大多数激光雷达语义分割模型很昂贵。
为了解决数据缺乏的问题,Wu等人使用KITTI数据集[7]提供的边界框[21]、[22]。他们还利用游戏引擎仿真生成逼真的扫描。我们发布了第一个大规模的数据集,具有完整的语义分割LiDAR扫描[1]——SemanticKITTI官网,其中对KITTI测程数据集[7]的所有扫描都进行了密集注释,即,超过43000次扫描,超过3:50亿个注释点。在没有数据观察障碍的情况下,本文研究了目前最先进的算法中哪些可以应用于自主驾驶环境下的点云。
利用其他上下文[5]、[8]的大型数据集,最近开发了几种用于三维语义分割的基于深度学习的方法,如PointNet[14]、PointNet++ [15], TangentConvolutions [20], SPLATNet [19],SuperPointGraph[10],和SqueezeSeg[21],[22]。
直接处理点云数据的问题之一是缺乏适当的顺序,这使得学习顺序不变的特征提取器非常具有挑战性。Qi等人使用未排序的原始点云作为输入,并应用对称运算符来处理这个排序问题。为此,PointNet[14]使用最大池来组合特征并生成置换不变的特征提取器。然而,这是PointNet的一个限制因素,导致它失去捕获特征之间的空间关系的能力。这限制了它对复杂场景的适用性。PointNet++[15]通过使用多层的特征提取方法解决了这个问题。通过利用本地附近的个别点,PointNet++捕获小范围的特征,然后在层次上应用这个概念来捕获全局特征。(和卷积网络类似)
Tatarchencko等人的TangentConvolutions[20]采用了一种不同的方法来处理非结构化的点云。他们提出了将CNNs直接应用于表面的切线卷积,这只有在从同一表面上采样相邻点时才能实现。在这种情况下,作者可以将一个切线卷积转化为一个平面卷积,应用于曲面在每一点的投影。然而,在旋转激光雷达和点云产生的与距离相关的稀疏性的情况下,这一假设就被推翻了。
Su等人通过在高维稀疏格子中投射点,以不同的方式处理SPLATNet中的表征问题。然而,这种方法在计算和内存消耗方面都不能很好地扩展。为了缓解这一问题,双边卷积[9]允许他们将这些算子专门应用于格子的占位扇区。
Landrieu等人通过绘制SuperPoint图,以类似于PointNets的方式总结了局部关系。这是通过创建所谓的SuperPoint来实现的,这些超点在局部上是一致的,几何上齐次的的点嵌入到PointNet。他们创建了一个SuperPoint图,这是原始点云的一个扩展版本,并训练一个图卷积网络来编码全局关系。
在旋转激光雷达分割分割的情况下,每次扫描的点数为10的五次方。这一比例阻止了上述所有方法的实时运行,限制了它们在自动驾驶中的适用性。与此相反,我们提出了一个系统,提供准确的语义分割结果,同时仍然以传感器的帧速率运行。
作为在线处理领域的领军人物,Wu等人开发的SqueezeSeg和SqueezeSegV2[21]、[22]也使用了点云的球面投影来支持2D卷积的使用。在此基础上,提出了一种轻量级的全卷积语义分割方法,并结合条件随机域(CRF)对分割结果进行平滑处理。最后一步是对距离图像中的点进行非离散化处理,使其回归到三维世界。两者都能比传感器速度快,即10hz,我们用它们作为我们方法的基础。
为了在此框架中提供完整的语义分割,需要解决几个限制。首先,投影需要扩展到包括完整的激光雷达扫描,因为SqueezeSeg框架只使用扫描的前90度,其中的原始KITTI数据集的障碍物标签是由边界框bbox注释的。其次,SqueezeNet主干不够描述性,无法推断我们的数据集[1]提供的19个语义类。第三,我们用高效的、基于gpu的最近邻搜索代替在图像域中运行的CRF,它直接作用于完整的、无序的点云。最后一步支持检索云中的所有点的标签,即使它们没有直接在范围图像中表示,与使用的分辨率无关。
提出了一种新的基于投影的方法,该方法允许使用平面卷积,克服了其缺点。我们的方法准确地细分整个激光雷达扫描的帧率达到或超过传感器(约10 Hz),使用范围和2d图像CNN作为一个代理,并适当处理将结果重新投影到3D点云后需要处理的离散化错误。
3 实现方法
我们的方法的目标是实现准确和快速的点云语义分割,以使自主机器能够及时做出决策。为了实现这种分割,我们提出了一个基于投影的二维CNN处理输入点云,并利用每个激光扫描的距离图像表示来进行语义推理。我们在下面的术语范围图像中使用点云的球面投影,但是每个像素对应一个水平和垂直方向,可以存储的范围值不止一个。投影之后是对整个点云的快速、基于GPU、k-近邻(KNN)的搜索,这允许我们恢复整个输入云的语义标签。这在使用小分辨率范围的图像时尤其重要,因为投影会导致信息丢失。
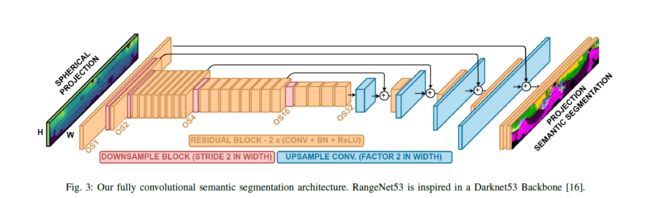
因此,我们的方法分为四个步骤,如图2所示。这四个步骤详细讨论以下部分:
(A)一个输入点云转换为一系列range image表示
(B) 2d全卷积的语义分割
(C)从2d到3d语义迁移恢复点从原始点云回复所有点,不管使用的range image离散化
(D)基于高效range image的3D后处理,使用快速、基于gpu的knn搜索操作所有点,将点云从不需要的离散化和推断工件中清除。

A. 距离图像点云的代理表示
几个激光雷达传感器,如Velodyne传感器,以距离成像的方式表示原始输入数据。每一列表示一个激光测距仪阵列在某一时刻测量的距离,每一行表示每一个激光测距仪的不同转弯位置,这些激光测距仪以恒定速率显示为红色。然而,在高速行驶的车辆中,这种旋转发生的速度还不够快,不足以忽略这种旋转所产生的倾斜“滚动快门”行为。为了获得每个扫描环境的更几何一致性的表示,我们必须考虑车辆的运动,从而得到一个点云,它不再包含每个像素的范围测量值,而是包含其他一些像素的多个测量值。为了获得完整的激光雷达点云的准确的语义分割,我们的第一步是将每个去斜点云转换为范围表示。为此,我们对每个点Pi = (x,y,z)进行转换,通过一个映射R3->R2到球面坐标系,最终到图像坐标系,公式定义为:
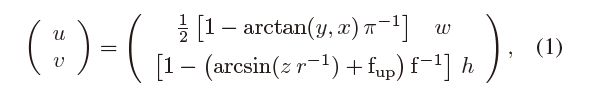
等式左边是图像坐标系,右边的h和w分别是期望距离图象表示的高度和宽度
Pi = {
x,y,z};
f = f_up + f_down; // 传感器的垂直俯视图
r = ||Pi||2; // 每个点的距离
这个过程产生一个(u,v)元组,包含每个Pi点的图像坐标,我们使用它来生成我们的代理表示。利用这些索引,我们**提取出每一个pi的距离r,它的x, y, z坐标,以及它的remission,我们把它们存储在图像中,创建一个 [5hw] 的张量。**由于扫描的去偏,将每个点分配到其对应的(u,v)按降序排列,以确保在图像中呈现的所有点都在传感器当前的视野中。我们进一步保存这个列表(u,v)成对地收集和清理产生的点云的语义,如我们在第III-C节和第III-D节中所述。
B. 全卷积语义分割
为了获得点云的这个范围图像表示的语义分割,我们使用了二维语义分割CNN,它更适合这种特殊的输入类型和形式因素。与Wu等人的[21]类似,我们使用了一种沙漏形的编码-解码器架构,如图3所示。这些类型的深沙漏形分割网络的特征是有一个带有显著下采样的编码器,它允许更高抽象的深层内核对上下文信息进行编码,同时运行速度比非下采样的副本更快。在我们的例子中,这个降采样是32(见图3),随后是一个解码器模块,它将卷积骨干编码器提取的特征代码向上采样到原始的图像分辨率,并在这些结果中添加卷积层。同时,每次上采样后我们还添加跳过之间的连接不同级别的编码器的输出步幅(OS),和他们相应的译码器输出步幅特征体积,以黑色箭头为例,恢复一些高频边缘将采样过程中丢失的信息。在这种编码-解码行为之后,体系结构的最后一层执行一组[11]卷积。这会生成一个输出卷[nh*w]的模型,其中n是数据中的类数。推理过程的最后一层是在unbounded模块上的softmax函数:

这给出了距离图像中每个像素的概率分布,其中模块c是类c对应的切片的无界输出。在训练期间,该网络使用随机梯度下降和加权交叉熵损失L进行端到端的优化:
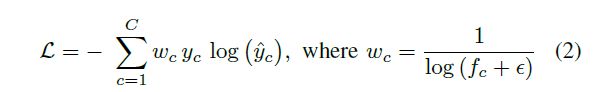
根据c类的频率fc的倒数对其进行惩罚。处理不平衡的数据,就像语义分割中的大多数数据集的情况一样,例如,类别-道路表示的数据集中的点的数量明显大于类别-行人。为了为我们的编码器骨干提取丰富的功能,我们取消了我们的RangeNet架构,通过修改Darknet[16]骨干架构的方式,使其可用于我们的方法。这个主干在设计时考虑了一般的图像分类和对象检测任务,非常具有描述性,在这些任务的几个基准测试中实现了最先进的性能。然而,它被设计用于处理平方长宽比RGB图像。对主干的第一个必要的调整是允许第一个通道拍摄5个通道的图像。由于我们处理的传感器有64个垂直放置的激光测距仪阵列,每次扫描产生130 000个点,因此我们得到的距离图像w ≈ 2048像素。为了在垂直方向上保留信息,我们只在水平方向上执行下采样。这意味着在编码器中,OS为32意味着w减少了32倍,但是在垂直方向h, 64像素仍然保持不变。为了评估我们的后处理恢复原始点云信息的效果,在我们的实验评估中,我们分析了输入大小[64 2048]、[64 1024]和[64 512],它们分别在编码器端产生大小[64 64]、[64 32]和[64 16]的特征量。
C. 从距离图像中重建点云
将距离图像表示映射到点云的通常做法是使用距离信息、像素坐标和传感器固有校准来实现映射:R2->R3。然而,由于我们最初是从点云生成范围图像,如第III-A节所述,这可能意味着从原始表示中删除大量点。这在使用较小的图像以更快地推断CNN时尤为重要。例如。 将130000个点投影到[64 512]范围图像上的扫描将仅表示32768点,并在每个像素的视锥中采样最接近的点。 因此,为了推断语义云表示中的所有原始点,我们使用所有的(u,v)对初始渲染过程中获得的所有pi进行配对,并将范围图像与对应于每个点的图像坐标进行索引。 在进行下一个后处理步骤之前,可以在GPU中以极快的速度执行此操作,从而以无损方式为整个输入扫描中存在的每个点生成语义标签。
D. 高效点云后处理
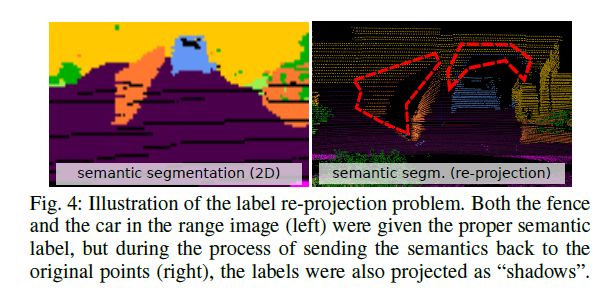
不幸的是,激光雷达扫描的快速语义分割通过二维语义分割的范围图像并非没有缺点。沙漏状的CNNs在推理过程中会产生模糊输出,这也是RGB和RGBD语义分割的一个问题。一些方法,例如[21]在2D分割后,对图像域中的预测使用条件随机场,以消除输出标签的这种“渗漏”。利用每个像素的softmax概率作为CRF的一元势,惩罚相邻点之间的信号跳跃和欧氏距离。即使这对2D有所帮助,也不会在重新投影到三维空间后解决问题,因为标签一旦被投影到原点云,存储在同一个范围图像像素内两个或两个以上的点将得到相同的语义标签。这种效应如图4所示,其中,推断出的点云标签由于CNN蒙版的模糊和所述的离散化,在背景中的物体中呈现阴影。此外,如果我们希望使用更小范围的图像表示来推断语义,这个问题就会变得更加严重,从而导致在不同类的对象中产生类似阴影的语义信息。
为了解决这个问题,我们提出了一种快速的、支持gpu的、k近邻(kNN)的搜索方法,它直接在输入点云中操作。这使我们能够对语义点云中的每一个点,在3D中最接近它的k个扫描点进行一致投票。由于在kNN搜索中很常见,我们还为搜索设置了一个阈值,我们称之为cut-off,它设置了一个被认为是近邻的点的最大允许距离(设置阈值)。排序k个最近点的距离度量可以是范围内的绝对差值,也可以是欧氏距离。尽管如此,我们也试图用减刑作为惩罚的条件,这在我们的经验中没有帮助。从现在开始,我们将考虑绝对距离差作为距离的用法来解释这个算法,但是欧几里得距离也是类似的,尽管计算起来比较慢。

该算法需要设置四个不同的超参数:
(i)S是搜索窗口的大小;
(ii)k是最近邻的数量;
(iii)截止值是k的最大允许范围差;
(iv)高斯逆数。
通过在我们的训练数据的验证集中通过数据驱动的搜索以经验方式计算超参数的值,并且在实验部分中进行简要分析。