ElasticSearch使用(附源码)
ElasticSearch使用(附源码)
简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
安装
1、官网下载:https://www.elastic.co/cn/downloads/elasticsearch#
2、解压,运行命令
tar -xvf elasticsearch-7.4.1-linux-x86_64.tar.gz
3、进入elasticSearch目录,运行命令:
bin/elasticsearch
4、配置外部访问
修改elasticsearch.yml文件的ip和端口
vi elasticsearch-7.3.2/config/elasticsearch.yml
network.host: 0.0.0.0
http.port: 9200
4、在浏览器输入即可访问:
http://localhost:9200
5、推荐使用kibana管理es的索引
ElasticSearch增删改查操作
增删改查是数据库的基础操作方法。ES 虽然不是数据库,但是很多场合下,都被人们当做一个文档型 NoSQL 数据库在使用,原因自然是因为在接口和分布式架构层面的相似性。
虽然在 Elastic Stack 场景下,数据的写入和查询,分别由 Logstash 和 Kibana 代劳,作为测试、调研和排错时的基本功,还是需要了解一下 ES 的增删改查用法的。
以下写法都是在kibana开发工具下的命令,kibana安装请参照:
https://www.elastic.co/cn/downloads/kibana
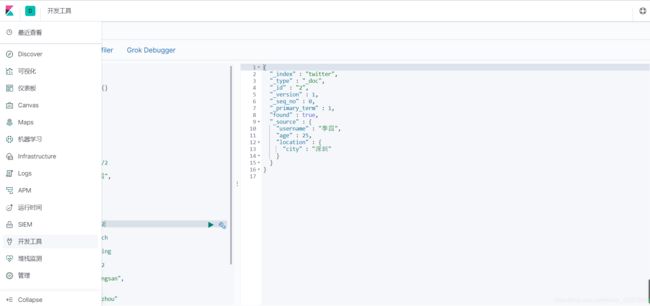
新增索引
POST twitter/_doc/2
{
"username":"李四",
"age":25,
"location":{
"city":"深圳"
}
}
命令返回响应结果为:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
文档获取
GET twitter/_doc/2
命令返回响应结果为:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"username" : "李四",
"age" : 25,
"location" : {
"city" : "深圳"
}
}
}
文档更新
PUT twitter/_doc/2
{
"username":"zhangsan",
"age":24,
"location":{
"city":"guangzhou"
}
}
命令返回响应结果为:
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
文档删除
DELETE twitter
命令返回响应结果为:
{
"acknowledged" : true
}
高亮文档获取
GET twitter/_search
{
"size": 200,
"query": {
"match_phrase": {
"username": "李四"
}
},
"highlight": {
"fields": {
"username": {
}
}
}
}
命令返回响应结果为:
{
"took" : 50,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.36464313,
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.36464313,
"_source" : {
"username" : "李四",
"age" : 25,
"location" : {
"city" : "深圳"
}
},
"highlight" : {
"username" : [
"李四"
]
}
},
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.36464313,
"_source" : {
"username" : "李四",
"age" : 25,
"location" : {
"city" : "深圳"
}
},
"highlight" : {
"username" : [
"李四"
]
}
}
]
}
}
ElasticSearch java api使用
最新ES的提供了2种Java客户端,分别为低级REST客户端、高级REST客户端。
官网推荐使用高级Rest客户端,其他的客户端慢慢的都会被高级Rest客户端取代。
参照es官网文档:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-document-delete.html
ES Rest高级客户端的创建
private static void ini() {
client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.16.137", 9200, "http")));
}
索引操作
索引即我们的新增操作,ES提供了三种形式的索引,分别为通过Json字符串、Map集合、XContentBuilder实现索引操作。
private static void save() {
ini();
//Json字符串作为数据源
IndexRequest request = new IndexRequest("posts");
request.id("1");
String jsonString = "{" +
"\"name\":\"生命的诞生\"," +
"\"type\":\"科学\"," +
"\"price\":\"170\"" +
"}";
request.source(jsonString, XContentType.JSON);
try {
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println("--------------------创建索引---------------------");
System.out.println(indexResponse.status());
client.close();
} catch (IOException e) {
e.printStackTrace();
}
查询数据
private static void get() {
ini();
GetRequest getRequest = new GetRequest(
"posts",
"1");
try {
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println("--------------------获取文档---------------------");
System.out.println(getResponse.getSource());
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
判断数据是否存在
private static void exists() {
ini();
GetRequest getRequest = new GetRequest(
"posts",
"1");
try {
//禁用获取 _source字段
getRequest.fetchSourceContext(new FetchSourceContext(false));
//禁用获取存储字段。
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println("--------------------判断文档是否存在-------------");
System.out.println(exists);
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
更新数据
private static void update() {
ini();
UpdateRequest updateRequest = new UpdateRequest(
"posts",
"1");
String jsonString = "{" +
"\"name\":\"进化论\"," +
"\"type\":\"进化\"," +
"\"price\":\"900\"" +
"}";
updateRequest.doc(jsonString, XContentType.JSON);
try {
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("--------------------更新文档---------------------");
System.out.println(updateResponse.status());
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
删除数据
private static void delete() {
ini();
DeleteRequest deleteRequest = new DeleteRequest(
"posts",
"1");
deleteRequest.timeout(TimeValue.timeValueMinutes(10));
deleteRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
try {
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println("--------------------删除文档---------------------");
System.out.println(deleteResponse.status());
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
高亮查询数据
es 支持3种高亮显示
Unified highlighteredit:
The unified highlighter使用Lucene Unified Highlighter。 这个突出显示器将文本分成句子,并使用BM25算法对单个句子进行评分,就好像它们是语料库中的文档一样。 它还支持准确的短语和多项(模糊,前缀,正则表达式)突出显示。 这是默认的highlighter。
Plain highlighteredit:
The plain highlighter使用标准的Lucene荧光笔。 它试图在词语重要性和短语查询中的任何单词定位标准方面反映查询匹配逻辑。
注意点:
The plain highlighter最适合在单个字段中突出显示简单查询匹配。 为了准确反映查询逻辑,它会创建一个微小的内存索引,并通过Lucene的查询执行计划程序重新运行原始查询条件,以访问当前文档的低级匹配信息。 对于需要突出显示的每个字段和每个文档都会重复此操作。 如果要在复杂查询的大量文档中突出显示很多字段,我们建议在发布或term_vector字段上使用Unified highlighter。
Fast vector highlighteredit:
The fvh highlighte使用 the Lucene Fast Vector highlighter。 此高亮显示器可用于在映射中将term_vector设置为with_positions_offsets的字段。
The fvh highlighte:
可以使用boundary_scanner进行自定义。
需要将term_vector设置为with_positions_offsets,这会增加索引的大小
可以将来自多个字段的匹配组合成一个结果。 见matching_fields
可以为不同位置的匹配分配不同的权重,允许在突出显示提升词组匹配的提升查询时,将词组匹配等术语排序在术语匹配之上
注意:
The fvh highlighte不支持跨度查询。 如果您需要支持跨度查询,请尝试使用其他highlighter,例如the unified highlighter。
参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-highlighting
kibana操作
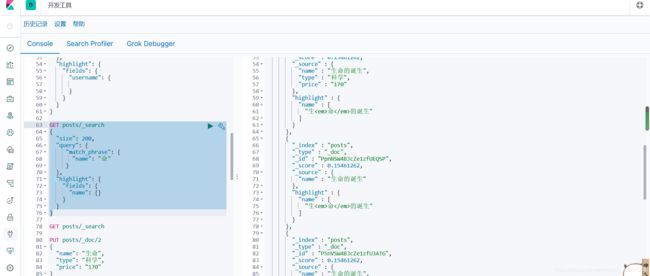
GET posts/_search
{
"size": 200,
"query": {
"match_phrase": {
"name": "命"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
private static void highLightSearch() {
ini();
SearchRequest searchRequest = new SearchRequest(
"posts");
//查询高亮
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
HighlightBuilder highlightBuilder = new HighlightBuilder();
//对name字段进行高亮显示
HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("name");
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
searchSourceBuilder.highlighter(highlightBuilder);
//查询出来所有包含name字段且name字段包含 生命的诞生值 的文档 模糊查询
searchSourceBuilder.query(QueryBuilders.matchQuery("name", "命"));
//将请求体加入到请求中
searchRequest.source(searchSourceBuilder);
try {
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("--------------------搜索高亮文档---------------------");
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits.getHits()) {
Map highlightFields = hit.getHighlightFields();
HighlightField highlight = highlightFields.get("name");
if (highlight != null) {
Text[] fragments = highlight.fragments();
String fragmentString = fragments[0].string();
System.out.println(fragmentString);
}
}
System.out.println(Arrays.toString(searchResponse.getHits().getHits()));
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
源码
码云:https://gitee.com/lhblearn/EsDemo