计算机组成与设计(2)-----指令_2
思维导图
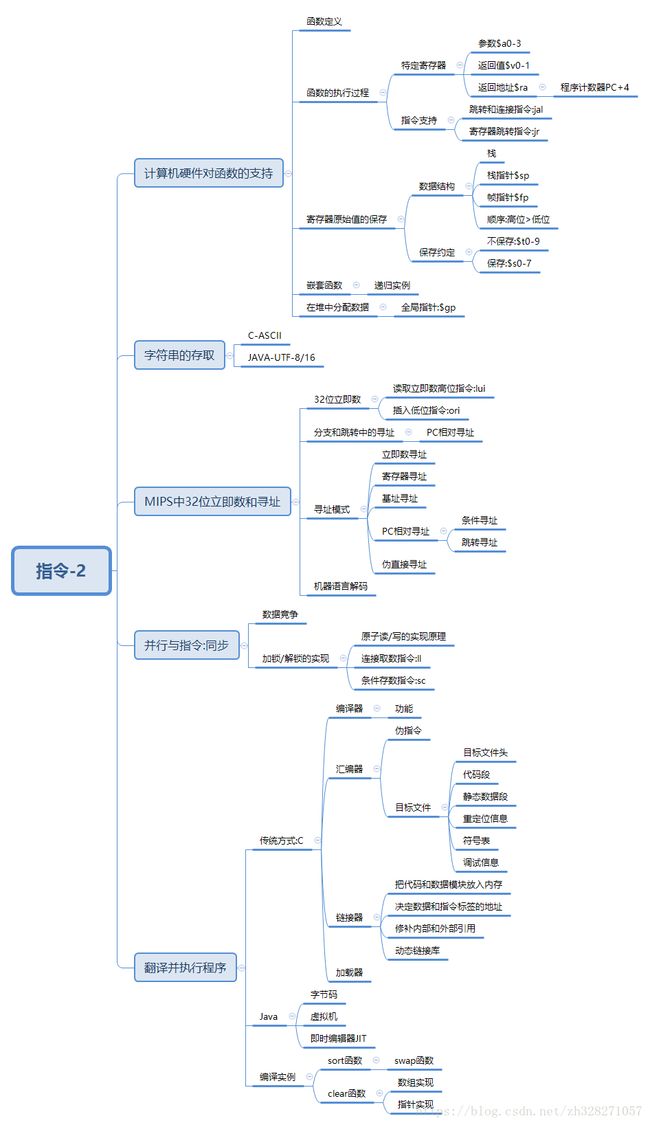
一.计算机硬件对函数的支持
函数是通过指定的输入参数根据一定的处理方法从而得出输出参数的过程.
1.1函数的执行过程
函数或者方法会有输入参数,方法体,返回值等特征.汇编语言中为这些特征设计了一些寄存器.
- $a0-$a3:用于保存输入参数
- $v0-$v1:用于保存返回值
- $ra:保存返回地址,具体地址是函数调用指令地址的下一个字节的地址,是为了返回函数调用地址而存在.
- 程序计数器PC:用于保存当前运行的指令地址,使用函数调用指令是,$ra其实就是被赋值为PC+4的值.
函数的调用也有特定的指令支持
- 连接跳转指令jal:用于跳转到某个函数所在的地址,他会将此时的PC+4的值赋给$ra,以便函数执行后返回.
- 强制跳转指令jr:跳转至指定的寄存器位置,一般用于jr $ra,标识函数执行后返回.
现在函数的执行过程就比较清晰了,在函数的调用处调用jal指令,然后执行过程,最后通过jr指令返回调用地址.
1.2寄存器原始值的保存
- 栈指针$sp:保存栈顶的栈帧的地址.
- 帧指针$fp:同$sp一起确定一个函数在栈中的位置,可以根据这个值获取母函数的$sp及$fp,确定其界限,还可以存储局部变量.
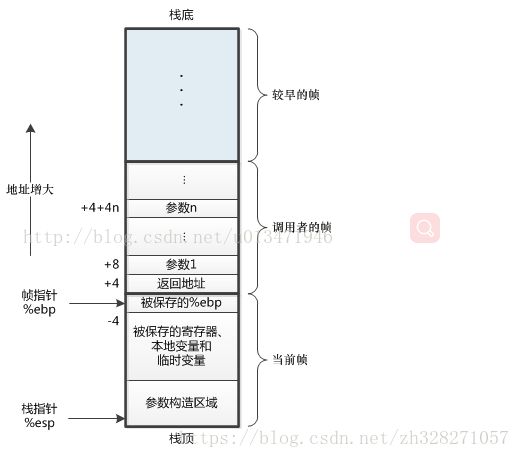
图是盗用的,帧指针就是$fp,栈指针就是$sp
当调用一个函数时,我们需要保存其参数,返回值,返回地址.然而,当这个函数中又调用了其他的函数时,就没有那么多的寄存器以供使用了,所以,会使用一个先进后出的数据结构-----栈,保存母函数的相关数据.
栈是先进后出的有序队列.与专有的寄存器$sp配合.输入数据成为入栈(push),入栈时的顺序是高地址>低地址,输出数据成为出栈(pop)顺序则和入栈时相反.一般的保存约定是不保存临时寄存器$t0-$t9,保存保留寄存器$s0-$s7.
1.3嵌套函数实例
下面使用一个递归函数调用的实例来理解函数是如何被调用的.
//以C函数举例
int fact (int n){
if(n < 1){
return 1;
}else{
return (n * fact(n - 1));
}
}以下是编译后的指令
//开始调用fact方法
fact:
addi $sp,$sp,-8 //保留连个数据4 * 2,所以将栈指针的地址减去8个字节
sw $ra,4($sp) //保存返回地址
sw $a0,0($sp) //保存参数n
//判断n是否小于1
slti $t0,$a0,1 //判断n是否小于1
beq $t0,$zero,L1 //if n>=1 跳转至L1
//如果n < 1
addi $v0,$zero,1 //保存返回值
addi $sp,$sp,8 //出栈两个元素
jr $ra //返回到函数调用地址
//如果n >= 1
L1:addi $a0,$a0,-1 //保存n-1的值
jal fact //递归调用此方法
//递归调用函数后,返回地址,返回值,参数$a0都已经被覆盖,需要通过栈获取
lw $a0,0($sp) //恢复输入参数值
lw $ra,4($sp) //恢复返回地址值
addi $sp,$sp,8 //栈的大小减去8个字节,以恢复此时这个函数所对应的栈的位置
//进行返回
mul $v0,$a0,$v0 //保存返回值
jr $ra //返回到函数调用地址
1.4在堆中为新数据分配空间
C程序需要在内存中对静态变量和动态数据的分配提供空间.一般约定如下:
- 保留区:内存低位即地址从0开始的一部分是保留的.
- 正文:通常称代码段.地址在保留区之上
- 静态数据:存放静态数据,配合$gp寄存器使用,地址在正文之上.
- 动态数据:可以称为堆,存放动态的数据.方向向着栈的地址延伸,地址在静态数据之上
- 栈:存在于位置最高处,方向向着动态数据取延伸,地址在动态数据之上,如果此两者相互接触,表示没内存了,就会发生内存泄漏.

二.字符串的存取
字符可能会使用不同的编码方式(字符集)进行储存,以便被转化为二进制格式.
- ASCII:每个字符占用一个byte即8个bit(8位),所以采用lb,sb,lbu进行存取
- UTF-8:除了ASCII部分的子集是8bit外,其余的占用16个bit,即半个字,所以采用lh,lhu,sh进行存取
- UTF-16:不同于UTF-8,所有的字符都占用16bit
- UTF-32:所有的字符占用一个字即32bit
三.MIPS中32位立即数和寻址
3.1 32位立即数
通过上篇指令的分享我们知道,指令是具有格式的,不会把32位地址都用来表示立即数,比如在addi中.那么当需要32位立即数是应该怎么做呢?会使用到两个特殊的指令.
//如何加载32位的立即数0000 0000 0011 1101 0000 1001 0000 0000
//立即数高位指令,用于指定寄存器中前16位即高位的值
lui $s0,61 //61的二进制表示是0000 0000 0011 1101,指定此寄存器的前16位
ori $s0,2304 //2304的二进制表示是1101 0000 1001 0000 0000,指定此寄存器的后16位3.2寻址模式
在遇到的命令中,一些命令需要跳转到其他地址继续执行.而跳转过程中不同命令跳转地址的确定方式方法是不同的.
- 立即数寻址:操作数是位于指令自身中的常数
- 寄存器寻址:操作数是寄存器,比如jr
- 基址寻址:操作数在内存中,其地址是指令中基址寄存器和常数的和,比如lw
- PC相对寻址:地址是PC和指令中常数的和,比如所有的条件分支跳转指令,beq,bnq等,一般来说,跳转目的地址都接近于跳转地址
- 伪直接寻址:跳转地址由指令中26位字段和PC高4位相连而成,比如j.跳转地址举例太远时使用,会将PC的高四位和操作数的28位作为第28位结合构成跳转地址.

图中箭头指向的是寻址的单位.一般用字即32bit寻址,可以比半字或者字节寻址有更大的范围.
四.并行与指令:同步
现在的电脑都是多核处理器,会存在数据竞争的情况,即存在两个及其以上的线程同时对一个地址进行访问或写入请求,且其中至少有一个写入请求.数据竞争会导致读取数据出错.而解决的办法就是同步,采用加锁和解锁实现.对一个区域加锁,则其他的线程就不可进行写入操作,这个区域就称为互斥区.
实现的原理则是假设存在一个单元表示某个锁的状态,1是被锁状态,0是自由状态.通过一个读取指令让1和这个状态值进行交换,如果交换后的值是1,则表示这个区域已经被加锁.如果是0,则表示加锁成功.然后在使用一个写入指令写入值,并返回一个状态值,如果返回的状态值为1,则表示写入成功,以上操作是原子操作,如果返回的状态值是0,则表示在此期间,有其他的线程对这个区域进行了写入操作,原子操作失败,再次重复以上操作.
原子操作实例:
//模拟进行一次原子操作,先读取,在写入
again:addi $t0,$zero,1 //设置寄存器的值为1
ll $t1,0($s1) //连接取数指令,会读取$s1地址处的值,并标记此地址,如果在条件存数指令sc执
//行前有其他线程对此地址进行了写入操作,sc指令就会失败
sc $t0,0($s1) //条件存数指令,将$t0的值写入$s1,并将$t0的值赋值为1或0,1表示成功,0表示失败
beq $t0,$zero,again //如果存入失败,表示原子操作失败,重新执行.
所以在ll和sc指令之间的操作是一次原子性操作,但是,其中的指令需要慎重考虑.
五.翻译并执行程序
不同语言被编译的过程并不相同,下面是传统的C语言和java语言的编译过程.
5.1C语言的翻译
- C语言的翻译过程大致分为4部,并需要4个工具.
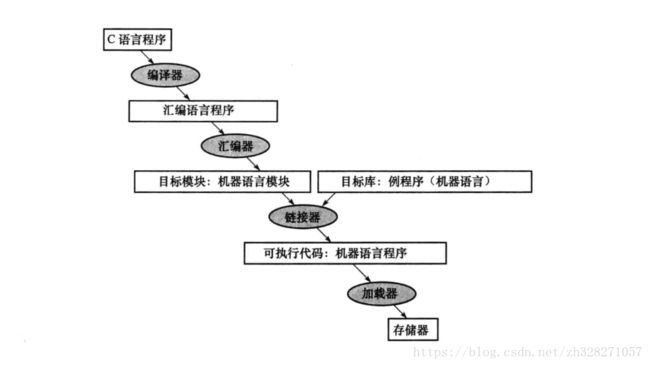
1.编译器:将C语言转化为汇编语言
2.汇编器:将汇编语言转化为目标文件,目标文件含有机器语言指令和将数据和指令正确放入内存所需要的信息.目标文件一般含有:
- 目标文件头:描述大小和位置
- 代码段:机器语言代码
- 静态数据段:生命周期内分配的数据
- 重定位信息:标记了一些在程序加载如内存是依赖于绝对地址的指令和数据
- 符号表:未定义的剩余标记,如外部引用
- 调试信息:包含一份说明目标文件如何编译的简明描述,这样,调试器可以将机器指令关联到C源文件.
3.链接器:首先,每一个函数都是单独编译的,这样如果函数改变则只需要重新编译这一部分的函数即可,而不用重新编译和汇编整个 程序.链接器的功能就是讲独立汇编的机器语言拼接在一起,他会寻找旧的地址,然后用新的地址代替他们.其工作步骤大 致分为3步:
- 将代码和数据模块象征性的放入内存
- 决定数据和指令标签的地址
- 修补内部和外部引用
4.加载器:链接器执行完毕后会生成一个可执行文件.加载器会将其放入内存中以准备执行.
- java语言
编译器会将java代码编译成class文件,java虚拟机会读取此class文件以执行.JIT是及时编译工具,他会将解释的代码段翻译成宿主计算机上的机器语言以提高效率.
最后,用一个冒泡排序程序作为完整的例子理解指令.
//首先,冒泡排序需要一个子函数,用以交换两者的值
C代码:
void swap(int v[],int k){
int temp;
temp = v[k];
v[k] = v[k + 1];
v[k + 1] = temp;
}
//编译后的代码
swap: sll $t1,$a1,2 //k*4获取v[k]的字节地址的偏移量
add $t1,$a0,$t1 //偏移量加上数组地址获取v[k]的地址
lw $t0,0($t1) //获取v[k]的值
lw $t2,4($t1) //获取v[k + 1]的值
sw $t2,0($t1) //存入v[k]的值
sw $t0,4($t1) //存入v[k + 1]的值然后是冒泡排序的C代码
//冒泡排序的C代码
void sort (int v[],int n){
int i,j;
for(i = 0;i < n;i += 1){
for(j = i - 1;j >= 0 && v[j] > v[j + 1]; j += 1){
swap(v,j);
}
}
}
//编译后的代码
//首先,保存寄存器的值
sort:addi $sp,$sp,-20
sw $ra,16($sp)
sw $s3,12($sp)
sw $s2,8($sp)
sw $s1,4($sp)
sw $s0,0($sp)
//排序过程
//移动参数
move $s2,$a0 //获取数组地址v[]
move $s3,$a1 //获取偏移量n
//循环外部
move $s0,$zero //$s0指定值为0,i值
for1tst:slt $t0,$s0,$s3 //第一层循环判定,i < n
beq $t0,$zero,exit1 //如果i >= n,则跳转至exit1
//循环内部
addi $s1,$s0,-1 //j = i -1
for2tst:slti $t0,$s1,0 //第二程循环判定,j < 0
bne $t0,$zero,exit2 //如果j < 0,跳转至exit2
sll $t1,$s1,2 //获取偏移量
add $t2,$s2,$t1 //获取v[j]的地址
lw $t2,0($t2) //获取v[j]值
lw $t4,49$t2) //获取v[j + 1]的值
slt $t0,$t4,$t3 //判断v[j + 1] < v[j]
beq $t0,$zero,exit2 //如果v[j + 1] >= v[j],跳转至exit2
//如果v[j + 1] < v[j],传递参数并调用swap函数
move $a0,$s2 //传入数组地址
move $a1,$s1 //传入偏移量
jal swap //调用swap函数
//循环内部
addi $s1,$s1,-1 //j = j -1
j for2tst //返回第二层循环
//循环外部
addi $s0,$s0,1 //i = i +1
j for1tst //返回第一层循环
//恢复寄存器的值
lw $s0,0($sp)
lw $s1,4($sp)
lw $s2,8($sp)
lw $s3,12($sp)
lw $s4,16($sp)
addi $sp,$sp,20
//过程返回
jr $ra //返回函数调用地址
注:本篇文章由《计算机组成与设计》第二章-指令:计算机的语言 总结而来,由于本人非计算机专业出身,许多知识实在是理解不能,总结有相当多的遗漏,乃是我看不懂所致,更别说其中内容肯定有大量的理解错误,万望大家提出批评,我好改正。