CD用户消费分析行为
数据源来源于某CD网站,本文主要利用python进行分析
本文数据字段包括
- uesr_id 用户ID
- order_dt :购买日期
- order_products : 购买的产品数量
- order_amount : 购买金额
本文按照下面的框架进行数据的处理和分析:
分析框架
- 1.数据清洗和预处理
- 2.进行用户的消费趋势的分析
- 3.用户个体消费分析
- 4.用户消费行为
- 5.复购率和回购率分析
1.数据清洗和预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
column =['uesr_id','order_dt','order_products','order_amount']
#定义列名
df=pd.read_csv('D:/a.txt',names= column ,sep='\s+')
# 读取该文件并对数据进行切割
df.head() #查看下处理完的数据
处理完的数据就是这样的:

df.describe()
接着我们可以通过describe函数看到数据的描述

**从这些数据可以看出,可以得出 中位数为35,平均消费35,即用户的平均消费为35元,但是最大金额为1286,说明有一定极值的干扰。大多数人的消费了少量商品(平均2.4)表明用户的消费水平比较稳定
**
附上函数解析:
| 函数 | 解析 |
|---|---|
| df.describe() | 查看数据值列的汇总统计 |
| df.mean() | 返回所有列的均值 |
| df.count() | 返回每一列中的非空值的个数 |
| df.corr() | 返回列与列之间的相关系数 |
| df.max() | 返回每一列的最大值 |
| df.min() | 返回每一列的最小值 |
| df.std() | 返回每一列的标准差 |
| df.median() | 返回每一列的中位数 |
| – | – |
2.进行用户的消费趋势的分析
首先呢,对数据按照日期格式进行统一,把日期统归为一天的话就比较方便处理
df['order_dt']=pd.to_datetime(df.order_dt,format="%Y%m%d")
## 新增一列月份
df['month']=df.order_dt.values.astype('datetime64[M]')

- 每月的消费总金额
groupby_month=df.groupby('month')
order_month_amount =groupby_month.order_amount.sum()
order_month_amount.head()
plt.style.use('ggplot')
order_month_amount.plot()

从图中可知,消费金额在前三个月达到最高峰,后续消费比较稳定,有轻微下降趋势
- 每月的消费次数
groupby_month.uesr_id.count().plot()

可知:前三个月消费订单数在1w笔左右,后续消费人数均在2500
- 每月的产品购买量
groupby_month.order_amount.sum().plot()
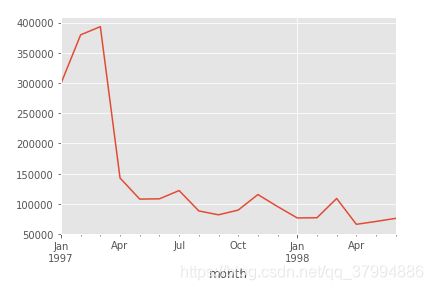
-每月的消费人数
df.groupby('month').uesr_id.apply(lambda x:len(x.drop_duplicates())).plot()
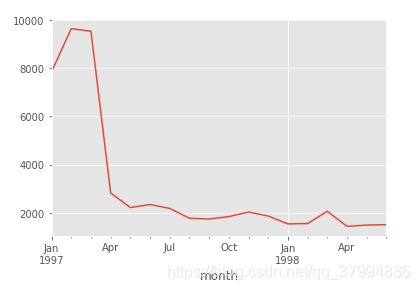
可知,每月消费的人数低于每月的消费次数,但差异不大
前三个月每个月的消费人数在8000-10000之间,后面的月份平均消费人数在2000不到
建立透视表,按月统计 销售金额,购买次数,用户人数
df.pivot_table(index='month',
values=['order_products','order_amount','uesr_id'],
aggfunc={
'order_products':'sum','order_amount':'sum','uesr_id':'count'}).head()

3.用户个体消费分析
- 用户消费金额,消费次数的统计
groupby_user=df.groupby('uesr_id')
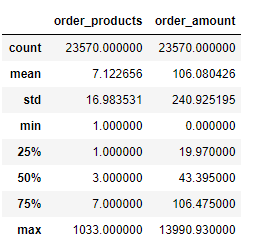
可知:用户平均购买了7张cd,但是中位数只有3,说明小部分用户购买了大量的CD
用户平均消费106元,中位值有43,有极值干扰
- 用户消费的金额和消费的散点图
``groupby_user.sum().query('order_amount<6000').plot.scatter(x='order_amount',y='order_products')`

可以明显看出,用户购买金额聚集在2000以下。而消费金额高的用户只占少数。
- 用户消费金额的分布图
groupby_user.sum().order_amount.plot.hist(bins=20)
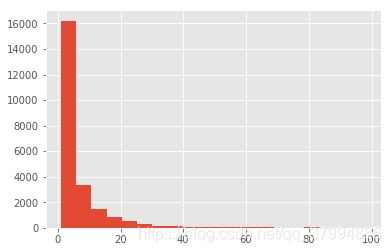
从直方图可以看出,用户消费金额,绝大部分呈现集中趋势,小部分异常值干扰了判断,可以使用过滤操作排除异常
- 用户消费次数的分布图
groupby_user.sum().query('order_products <100').order_products.hist(bins=20)
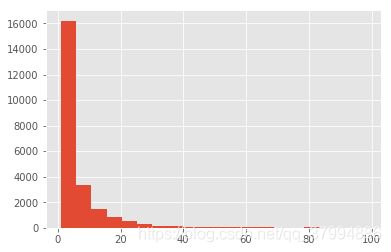
因此可以使用切比雪芙定理过滤异常值,计算95%的数据分布情况
- 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
user_cumsum=groupby_user.sum().sort_values('order_amount').apply(lambda x:x.cumsum()/x.sum())
user_cumsum .reset_index().order_amount.plot()
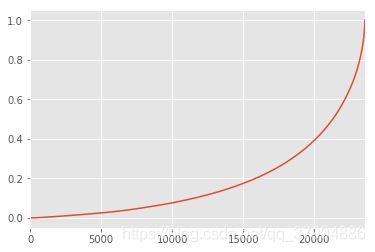
由图可知50%的用户仅仅贡献了15%的消费额度,而排名前5000的用户贡献了40%的消费额度
4.用户消费行为
用户第一次消费
groupby_user.min().order_dt.value_counts().plot()

用户第一次购买分布,集中在前三个月,其中2月11日至2月25日有一次剧烈波动,当然这个波动是什么要根据业务在进行推理
用户最后一次消费
groupby_user.order_dt.max().value_counts().plot()
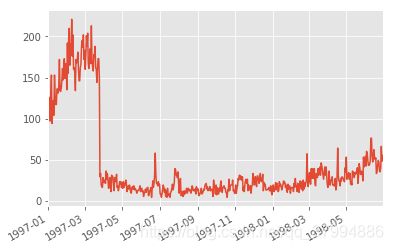
用户最后一次购买的分布比第一次购买分布广
大部分最后一次购买在前三个月,说明很多用户购买一次后就不再购买,最后一次购买数在递增,消费呈线性流失上升的情况
- 新老客消费比
user_life=groupby_user.order_dt.agg(['min','max'])
user_life.head()
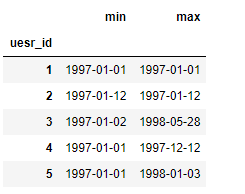
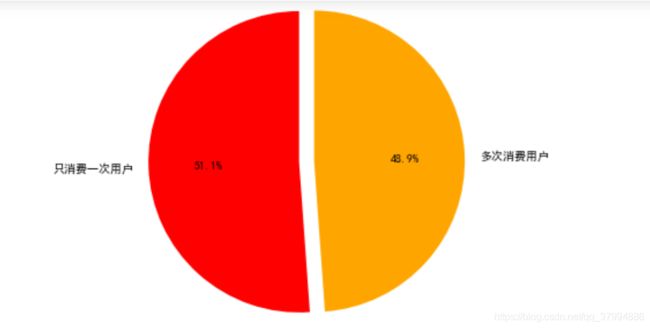
- 多少用户仅消费了一次
(user_life['min']==user_life['max']).value_counts()

由图得知,用户在 第一次购买时间和最后一次购买时间一样,有一半用户只消费了一次
- 每月新客占比
rfm= df.pivot_table(index='uesr_id',
values=['order_products','order_amount','order_dt'],
aggfunc={
'order_dt':'max',
'order_amount':'sum',
'order_products':'sum'})
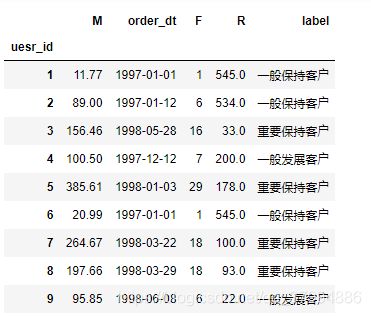
rfm.head()
- 用户分层
rfm[['R','F','M']].apply(lambda x:x-x.mean())
def rfm_func(x):
level =x.apply(lambda x:'1' if x>=0 else '0')
label =level.R+level.F+level.M
d={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般保持客户',
'000':'一般发展客户',
}
result=d[label]
return result
rfm['label']=rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
利用rfm模型进行分层
可以对用户进行分层
统计一下:
rfm.groupby('label').count()

rfm.loc[rfm.label == '重要价值客户','color']='g'
rfm.loc[~(rfm.label =='重要价值客户'),'color']='r'
rfm.plot.scatter('F','R',c=rfm.color)

从RFM 分层可知,大部分用户为重要保持客户,但是这是由于极值的影响,所以RFM的划分标准应该以业务为准
用户购买周期
- 用户消费周期描述
pivoted_counts =df.pivot_table(index='uesr_id',columns='month',values='order_dt',aggfunc='count').fillna(0)
pivoted_counts.head()
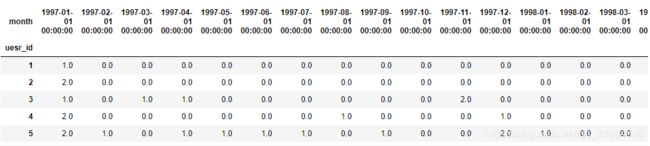
- 用户消费周期分布
df_purchase = pivoted_counts.applymap(lambda x: 1 if x >0 else 0)
df_purchase.tail()
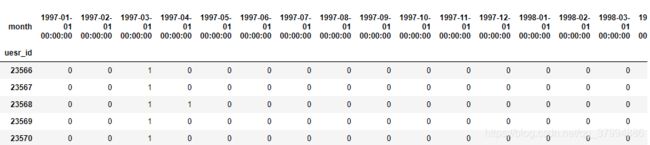
图中购买过了为1,没购买的为0
def active_status(data):
status = []
for i in range(18):
if data[i] ==0:
if len(status)>0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
else:
if len(status)==0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status, index = pivoted_counts.columns)
若本月没有消费
若之前是未注册,则依旧为位注册
若之前有消费,则为流失/补活跃
其他情况,为未注册
若本月有消费
若是第一次消费,则为新用户
如果之前有过消费,则上个月不活跃,则为回流
如果上个月为未注册,则为新用户
除此外,为活跃
purchase_stats = df_purchase.apply(active_status,axis=1,result_type ='expand')
# df.rename(columns={ df.columns[2]: "new name" }, inplace=True)
# purchase_stats.rename(columns={purchase_stats.columns:data_purchase.columns})
purchase_stats.head()
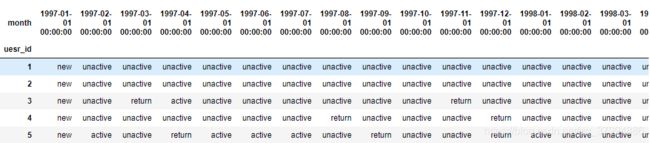
purchase_status_ct = purchase_stats.replace('unreg',np.NaN).apply(lambda x : pd.value_counts(x))
purchase_status_ct
# 未注册则设置为空值

图中可以看出 一月份有7846个用户 然后2月份分叉为不活跃用户 和 活跃用户 有8476个新用户 等等
purchase_status_ct.fillna(0).T.apply(lambda x:x/x.sum(),axis=1)
purchase_status_ct.fillna(0).T.plot.area()
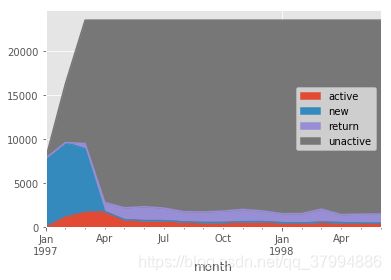
图中直观看出,新用户的产生
purchase_status_ct.fillna(0).T

由上表可知,每月的用户消费状态变化
活跃用户,持续消费的用户,对应的使消费运营的质量
回流用户,之前不消费本月才消费,对应的使唤回运营
不活跃用户,对应的是流失
# 一个用户可能多个订单 每个订单的间隔
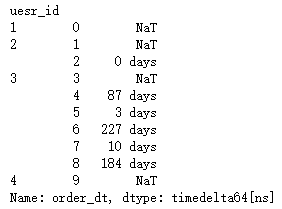
order_diff = groupby_user.apply(lambda x:x.order_dt - x.order_dt.shift())
order_diff.head(10)
# 去除单位 间隔天数分布图
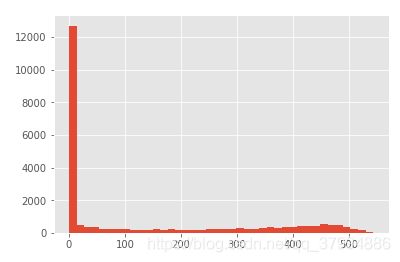
(order_diff / np.timedelta64(1,'D')).hist(bins=20)

订单周期呈指数分布
用户的平均购买周为68天
绝大部分用户的购买周期都低于100天
用户生命周期
- 用户生命周期描述
(user_life ['max']-user_life['min']).describe()

((user_life['max'] - user_life['min']) / np.timedelta64(1,'D')).hist(bins = 40)
用户的生命周期受只购买一次的用户影响比较厉害
用户均消费134天,中位数仅0天
- 用户生命周期分布
u_l = ((user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1,'D'))
u_l[u_l > 0].hist(bins=40)
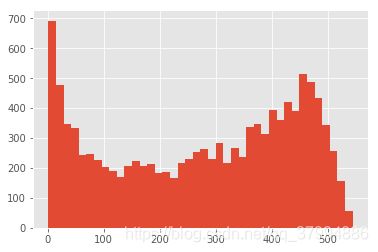
左边比较高,还是有些用户的生命周期是比较短的,例如300-500天等
有不少用户生命周期也是比较稳定
5.复购率和回购率分析
- 复购率
pivoted_counts.head()

# 购买大于1次的 赋值为1 ,然后小于等于1 的 如果是购买次数是0,则赋值为空,否则 就是购买一次,赋值为0
purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0)
purchase_r.head()
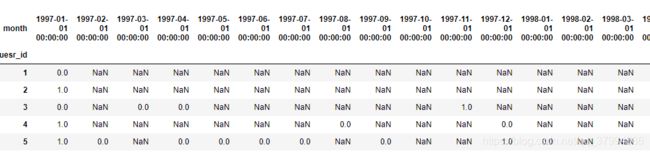
# sum() 0 不计数,count() 0计数
(purchase_r.sum() / purchase_r.count()).plot(figsize = (10,4))
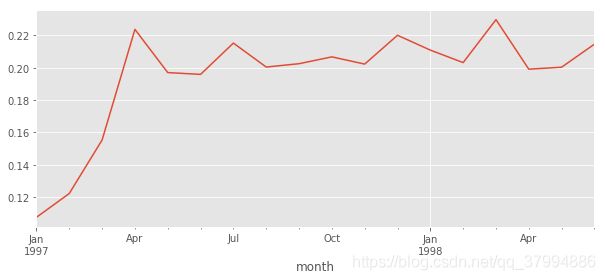
**复购率稳定在20% 左右,前三个月因为有大量新用户涌入,可能是因为有活动或者其他的政策导流用户,但是这些用户基本只购买一次,因此复购率较低。
- 回购率
# 回购率 只需要0 1 代表
data_purchase.head()

def purchase_back(data):
status = []
for i in range(17):
if data[i] == 1: # 本月进行过消费
if data[i+1] == 1: # 下一月是否进行消费
status.append(1) #消费为1 回购了
if data[i+1] == 0:
status.append(0) # 未消费则为0 没有回购
else:
status.append(np.NaN) # 之前没消费则不计
status.append(np.NaN) # 最后一个月没有判断需要补上
return pd.Series(status,data_purchase.columns)
purchase_b = data_purchase.apply(purchase_back, axis =1)
purchase_b.head(5)
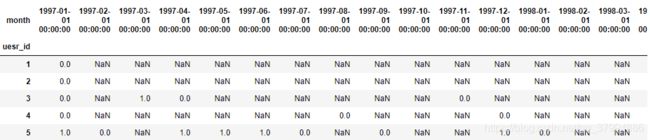
0 表示上个月购买了,下个月没有进行消费,则是没有回购 ,
1代表当月消费过次月依旧消费,表示回购了
NAN表示当月没有消费(不进行计算)
(purchase_b.sum() / purchase_b.count()).plot(figsize = (10, 4))
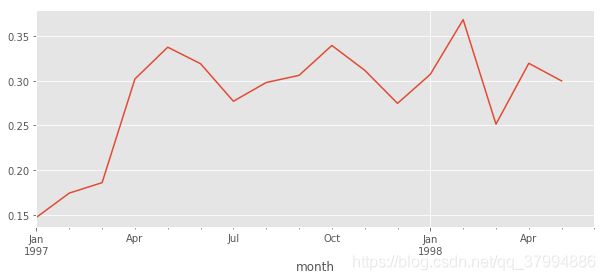
回购率在30%左右波动,比复购率要高,综合分析得出,新客整体质量低于老客,老客忠诚度(回购率)表现较好,消费频次稍次,这个是是CDNow网站的用户消费特征