DB2去重的几种方法
有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
例如下表:table1
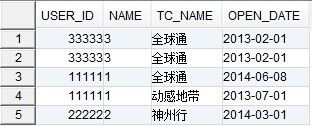
用户办理套餐的记录表,可看出,user_id=33333有两条完全重复的记录,user_id=11111的tc_name和open_date不一样
1、对于完全重复的记录,直接使用distinct 即可
select
distinct user_id,name,tc_name,open_date
from
table1
可得到如下结果:
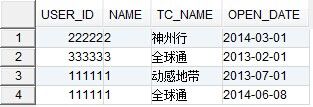
可以看出,完全重复的记录已经只剩下唯一的一条,但是部分重复的记录该方法无效
2、对于完全重复的记录,还可以使用group by
select
user_id,name,tc_name,open_date
from
table1
group by
user_id,name,tc_name,open_date
结果和上图一致,即:
该方法也只对完全重复的记录有效
3、row_number()over() 分等级之后限定 row=1
select
user_id,name,tc_name,open_date
from
(
select
user_id,name,tc_name,open_date
,row_number()over(partition by user_id order by open_date desc) as row
from
table1
)
where row=1
该方法得到的结果如下:
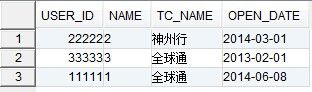
该方法不仅除掉了完全重复的记录,而且还除掉了不完全重复的记录,对open_date进行排等级,按照开通日期的倒序排列,且取出第一条记录,即开通时间最近的记录
4、max等聚合函数
select
user_id,name,max(tc_name),max(open_date)
from
table1
group by
user_id,name
该方法得出的结果如下,对完全重复记录和部分重复记录都有效,注:部分重复的记录要对所有重复字段使用max或min等才有效
那么在公司的sql语句
select ROW_NUMBER() OVER(ORDER BY max(r.inTime) deSC) AS RN,
r.tradeNo,max(r.orderId) as orderId,max(r.orderDate) as orderDate,max(r.merId) as merId,max(r.orderState) as orderState,
max(r.amount) as amount,max(r.origAmt) as origAmt,max(r.inTime) as inTime,max(r.modTime) as modTime,max(r.splitState) as splitState,
max(r.splitType) as splitType,max(r.splitcategory) as splitcategory,max(p.mainTradeNo) as mainTradeNo,
max(p.merId) as merIdSon,max(p.orderId) as orderIdSon
from UMPAY.T_PAYORDER_1707 as r left join UMPAY.T_PORDER_SPLIT_SUB_1707 as p
on r.tradeNo=p.mainTradeNo
where 1 = 1 and r.orderDate BETWEEN '20170720' and '20170721'
group by r.tradeNo
对应的要在查询总体数量的时候也得去重
select count(distinct(r.tradeNo))
from $splitPayorderTableName$ as r left join $splitPorderSUBTableName$ as p on r.tradeNo=p.mainTradeNo
where 1 = 1
参考链接:http://www.cnblogs.com/xuena/p/3912234.html