FastBERT:具有自适应推断时间的自蒸馏BERT
FastBERT: a Self-distilling BERT with Adaptive Inference Time
写在前面:
这是北大+腾讯+北师大的ACL2020。作者提出了一种新的inference速度提升方式,sample-wise adaptive mechanism,相比单纯的student蒸馏有更高的确定性,且可以自行权衡效果与速度,简单实用。这篇论文的方法可以说就是为了解决实际业务应用中的实际需求的,目前来说它仅支持分类任务,实际业务场景有很多分类任务,所选的验证集也是尽量选择来自工业界的(作者原话),推荐工业界的朋友可以去看看这篇论文。
参考文献:
【1】FastBERT: a Self-distilling BERT with Adaptive Inference Time
【2】FastBERT:又快又稳的推理提速方法
摘要
像BERT这样的预训练语言模型已被证明是高性能的。但是,它们在许多实际情况下通常在计算上很昂贵,因为很难用有限的资源轻松实现如此繁重的模型。为了通过有保证的模型性能提高效率,我们提出了一种具有自适应推理时间的新型可调速FastBERT。推理速度可以在变化的需求下灵活调整,同时避免了样本的冗余计算。而且,该模型在微调时采用了独特的自我蒸馏机制,从而进一步提高了计算效率,而性能损失却最小。我们的模型在十二个英语和中文数据集中取得了令人鼓舞的结果。如果给定不同的加速阈值以实现速度-性能的折衷,它的速度可以比BERT快1到12倍。
1 介绍
这一节主要说明了论文解决的问题:尽管像BERT这样的预训练模型准确性相比之前的模型大幅度提高,但这些模型的计算成本较高,推理速度较慢,这严重损害了它们的实用性。在实际应用,尤其是在工业界中时间和资源有限的情况下,几乎无法使此类模型投入运行(根据博主的经验来看也是这样,能部署上线提供实时服务的模型大多都是相对简单的模型)。例如,在诸如句子匹配和文本分类之类的任务中,经常需要每秒处理数十亿个请求。
接着说明论文idea的来源:通过检查许多NLP数据集,我们发现样本具有不同的难度级别。繁重的模型可能会过多地计算简单的输入,而较简单的模型则可能在复杂样本中失败。预训练模型具有冗余性。基于这个发现,我们提出了FastBERT,这是一种具有样本自适应机制(sample-wise adaptive mechanism)的预训练模型。 它可以动态调整执行的层数以减少计算步骤。 该模型还具有独特的自蒸馏(self-distillation)过程,该过程仅需对结构进行最小的更改,即可在单个框架内以更快的速度获得准确的结果。
2 方法
2.1 模型结构
根据第一节介绍,我们可以知道,论文的创新点就是两:样本自适应机制(sample-wise adaptive mechanism)+自蒸馏(self-distillation)。那么这两个东西到底是什么呢?
首先说明样本自适应机制,所谓样本自适应,就是在每层Transformer后都去预测样本标签,如果某样本预测结果的置信度很高,就不用继续计算了,就是自适应调整每个样本的计算量,容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程。 直接上图,一目了然。
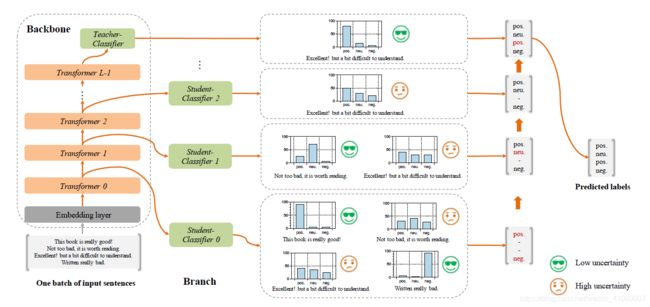
可以看到,在每层Transformer后我们都需要接一个分类器去预测结果,那熟悉蒸馏结构的朋友肯定发现了,诶,这不就是蒸馏学生模型学老师模型logits那一套嘛,是的,这里的分支Classifier都是最后一层的分类器蒸馏来的,作者将这称为自蒸馏(Self-distillation)。就是在预训练和微调阶段都只更新主干参数,微调完后冻结主干参数,保证pretrain和finetune阶段学习的知识不被影响,然后用分支分类器(图中的student)蒸馏主干分类器(图中的teacher)的概率分布。 之所以叫自蒸馏也很简单,因为FastBERT是我(分支)蒸我自己(主干)的知识。下面是作者在消融实验给出的结果:
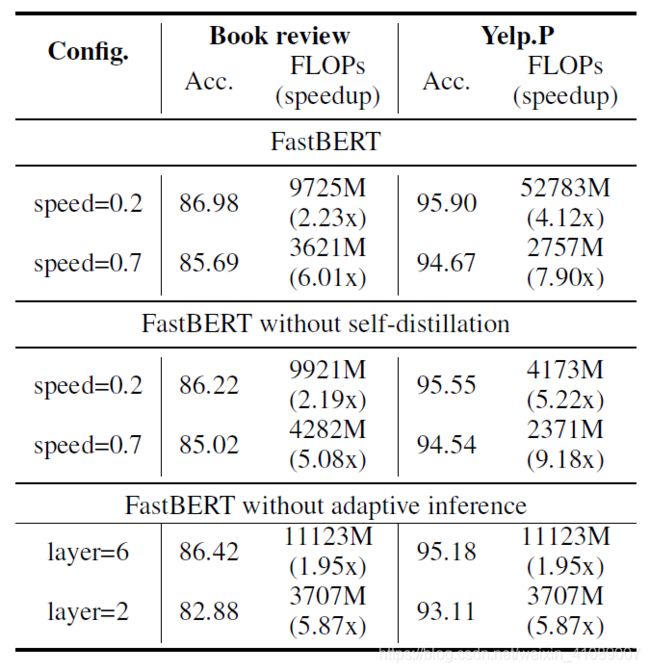
可以看到,非蒸馏的结果没有蒸馏要好。为什么呢,这里引用知乎李如大佬的观点:
个人认为是合理的,因为这两种方式在精调阶段的目标不一样。非自蒸馏是在精调阶段训练所有分类器,目标函数有所改变,迫使前几层编码器抽取更多的任务feature。但BERT强大的能力与网络深度的相关性很大,所以过早地判断不一定准确,致使效果下降。同时,使用自蒸馏还有一点重要的好处,就是不再依赖于标注数据。蒸馏的效果可以通过源源不断的无标签数据来提升。
2.2 模型训练
三步走:主干预训练,主干微调,用于学生分类器的自蒸馏。就比正常的预训练模型多一步自蒸馏。
-
Pre-training:同BERT系模型是一样的,主干模型可以随便换,只要是BERT系的都行( BERT-WWM, RoBERTa, ERNIE等等)。更舒服的是,FastBERT甚至不需要自己执行预训练,因为它可以自由加载高质量的预训练模型。
-
Fine-tuning for Backbone:主干精调,也就是给BERT最后一层加上分类器,用任务数据训练,这里也用不到分支分类器,可以尽情地优化。
-
Self-distillation for branch:分支自蒸馏,用无标签任务数据就行,将主干分类器预测的概率分布蒸馏给分支分类器。这里使用KL散度衡量分布距离,loss是所有分支分类器与主干分类器的KL散度之和。

2.3 自适应推理
自适应推理,在每个Transformer层,我们针对每个样本测量当前推断是否足够可信,简单的直接给结果,困难的继续预测。这里作者定义了新的不确定性指标,用预测结果的熵来衡量,熵越大则不确定性越大:
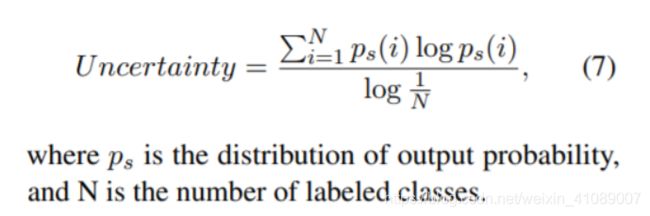
这里有个很重要的假设:
LUHA: the Lower the Uncertainty, the Higher the Accuracy.
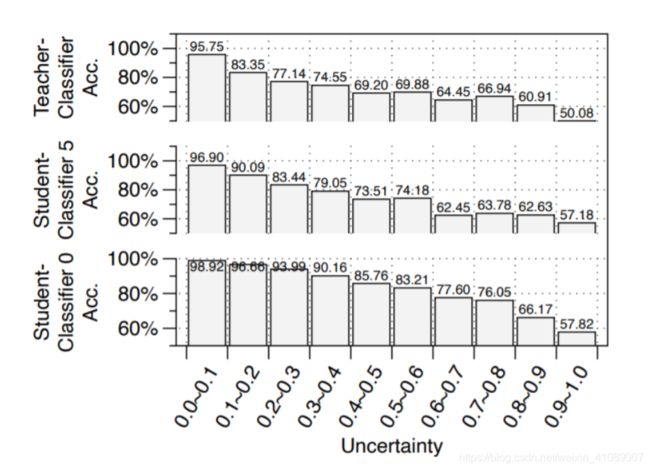
这个假设是指“低不确定度的样本,分类准确性高,高不确定度的样本,分类准确性低”。为什么要有这个假设呢?很简单,这样就避免了这样一个情况,在Adaptive inference时,第一层的分类器很烂,他觉得所有的样本都是很好分的然后很自信地把所有样本都分好了同时不确定度也很低,那这样就完全依赖第一层的分类结果了。作者通过实验对此假设进行了验证,大多数情况下低不确定度下准确性是很高的。所以这个被第一层错误分类的样本会有,但数量较少。
3 模型效果
对于每层分类结果,作者用“Speed”代表不确定性的阈值,和推理速度是正比关系。因为阈值越小 => 不确定性越小 => 过滤的样本越少 => 推理速度越慢。
模型最终在12个数据集(6个中文的和6个英文的)上的表现还是很好的:
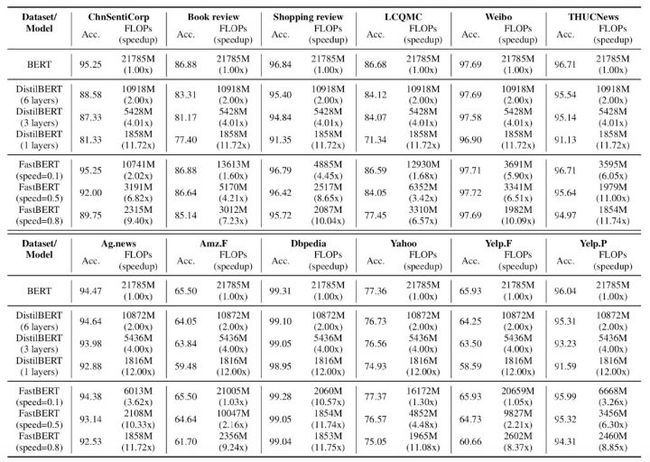
可以看到,在Speed=0.2时速度可以提升1-10倍,且精度下降全部在0.11个点之内,甚至部分任务上还有细微提升。相比之下HuggingFace的DistillBERT的波动就比较剧烈了,6层模型速度只提升2倍,但精度下降最高会达到7个点。
阅读小结
全文看下来,感觉FastBERT是一个在工程上十分实用的模型,通过提前输出简单样本的预测结果,减少模型的计算负担,从而提高推理速度。后续的分支自蒸馏也设计的很巧妙,可以利用无监督数据不断提升分支分类器的效果,而无监督数据相对标注数据来说还是很容易获得的。虽然它每层都多了一个分类器,但是这对于工程来说完全不care,工程上对这些预训练模型care的就是推理速度(哭),要是能大大提高推理速度肯定是有很大用武之地的。
不过遗憾的是,代码只有等到论文发表才会开源,先插个眼坐等开源:https://github.com/autoliuweijie/FastBERT
