Python_data pre-processing
All of the tech are basic solving solution. In order to obtain robust predictive model, missing value imputation should be consider case by case.
如果是个小白,比如我,就可以这样非常generally clean data.
0. Check for shape, missing value and variable types in dataset
data.dtypes
data.isnull.sum()
data.info()1. impute numeric missing value with pandas
data['column name'].fillna(0.0, inplace=True)
data['column name'].fillna('U1', inplace=True)2. encode categorical columns with number (otherwise may cause problem in machine learning algorithms)
cleanup_nums = {
"stage":{"IV":0,"IIB":1,"III":2,"IIA":3,"I":4},
"side":{"both":2,"right":1,"left":0}}data.replace(cleanup_nums, inplace=True)3. Check for correlation between variables
corr = data.iloc[:,1:31].corr()
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask)] = True
sns.set(style="white")
sns.heatmap(corr, mask = mask)
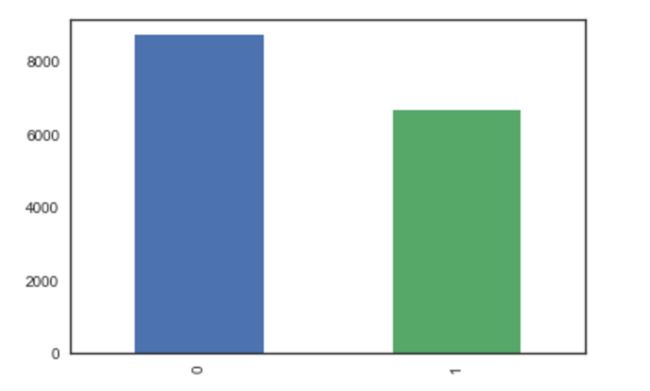
4. Check whether binary output are skewed
data['label name'].value_counts().plot(kind='bar')