用Node.JS分析steam所有的游戏!
背景
最近 Steam 玩得比较多,早晨突然想到一个有趣的问题:买下 Steam 所有游戏要花多少钱?
去 Google 了一下,发现国外有个网站做了计算,但是 2014 年底就停止更新了。研究了一下代码和 Steam API,自己做了一个网站来玩。
虽然没什么技术含量,但是很好的展示了如何把一个点子变成现实,所以记录下来。
技能和工具
这个网站非常简单,涉及到的技术只要初步掌握即可实现。
以下是我用到的技能和工具,你可以根据自己情况调整
技能:
Python
Node.js
基本的 HTML、CSS 和 JS
基本的 Linux 技能
基本的 Nginx 技能
能力
会用 GitHub
工具:
一台 VPS
一个域名
一个编辑器(我用的 Sublime Text 3)
调查
首先去 Google 一下“How much to buy all steam games”,搜到这个网站:Buy All of Steam,截图如下

哇,九万多美元!真不少。
再往下看,最后一次更新时间是 2014 年光棍节。

是不是作者在光棍节脱单了所以放弃了 Steam?
继续往下看,网站还给出了计算方法,非常简单:
from steamapiwrapper.SteamGames import Games |
哇真的好简单!
然后我去看了一下这个steamapiwrapper库,

2 years ago
2 years ago
2 years ago
。
。
。
。
。
。
。

这就是网站作者自己写的库吧!一定是脱团之后弃坑了吧!!!
好吧,关掉网页,回到 Google 继续往下看。
嗯……没了。
其他的网页都是一些统计性质的文章,Steam 更新频率极高,这类文章基本上是一发表就过时。
怎么办?
作为无所不能的程序员,当然是自己写一个啦!既然两年前能实现,两年后一定也能搞定!

看看我们收集到了什么有用的东西:
一段计算代码
一个 Steam API 库
那就从这里开始吧。
修改代码
以下代码不包含任何最佳实践,Just For Fun!
首先来看看这段两年前的代码还能否运行,如果能,那我们只要写个网页展示就可以了。
steamapiwrapper没有上传到 pip,所以我们只能下载代码到本地。
首先登陆 VPS:
ssh [email protected] |
提示:本文的命令和代码是意识流,重在介绍思想和流程,具体的细节请自行 Google(别百度,百度一下你就被坑)。
然后用virtualenv创建 Python 虚拟环境,不影响本机的 Python 配置:
$ mkdir /steamtuhao |
执行完会在根目录下的steamtuhao目录中创建一个 Python 虚拟环境,并且指定 Python 版本为 2.7(steamapiwrapper基于 Python 2.x 开发)。
然后开启虚拟环境,下载第三方库:
$ source venv/bin/activate |
最后三行是不是看懵了?GitHub 克隆下来的库并不能直接导入 Python 中,需要把里面真正的 Python 包复制出来。所以这里的操作其实是:复制出来我们要用的包、删掉整个项目、重命名包。
最后新建一个文件,把网站中提到的那段代码复制进去:
# 需要复制的代码 |
$ vim calTotalPrices.py |
OK,运行一下试试:
$ python calTotalPrices.py |
报错了。
具体的错误信息我忘了保存,大概就是说 JSON 不能解析None。打开出错的SteamGames.py定位过去看下,发现调用了一个_open_url函数,搜索一下这个函数看看…………
没找到。
这哥们绝对是恋爱了,否则不可能犯这么弱智的错误。
经过@Ralph-Wang 提醒,发现
_open_url是继承自SteamBase.py中的SteamAPI类。那应该和下面提到的问题一样,因为 URL 里面编码了参数,导致请求返回 null。
好吧,看上下文,这里应该是请求一个 URL 并解析返回的 JSON 内容。
那我们直接用requests这个库就行。
$ pip install requests |
然后修改SteamGames.py文件:
# 文件头部 import 进来 |
OK,现在再来跑一下看看:
$ python calTotalPrices.py |
又报错了。
具体的错误信息我没保存(为什么这句话这么眼熟),反正大概意思就是 JSON 不能解析None。什么?刚才不就是这个错误吗?!
仔细看了一下,错误位置和上次一样,到底是怎么回事?
回答这个问题之前先来了解下请求 URL 时到底发生了什么:
访问 URL
服务器返回 JSON 数据
拿到返回的数据并解析
我们刚才解决的是第一步,访问 URL。现在又出错了,那就说明返回的 JSON 数据有问题。
可以在代码里加一个print page看下,果然是None,也就是说根本就没拿到数据。
怎么回事呢?我们再print url一下,我看到的是这个:
http://store.steampowered.com/api/appdetails/?cc=US&appids=5%2C262150%2C7%2C8%2C10%2C20%2C393240%2C30%2C40%2C262190%2C50%2C393270%2C60%2C262210%2C70%2C393290%2C80%2C262230%2C90%2C92%2C262240%2C100%2C393320%2C393330%2C262260&l=english&v=1 |
这appids肯定有问题啊!
print all_ids,从里面拿出来一个 id,手动拼接到上面的 URL 中:
http://store.steampowered.com/api/appdetails/?appids=218620&cc=US&l=english&v=1 |
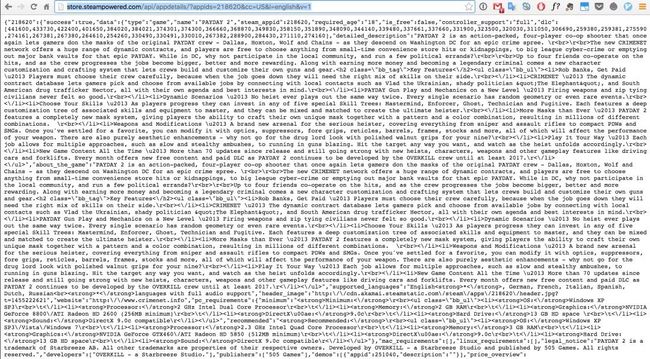
拿到了数据,看来就是 URL 拼接时候出问题了。
看下拼接函数:
def _create_url(self, appids, cc): |
为什么要urlencode呢?删掉,直接手动拼接:
def _create_url(self, appids, cc): |
再执行一下,还是报错。
好吧,就是这样的,现在你知道两年前的项目是什么概念了。
刚才我们在浏览器里不是拿到数据了吗?怎么又出问题了?
仔细看下拼接的 URL,发现有个区别:拼接的 URL 里有多个appid,我们刚才只试了一个。
修改测试 URL:
http://store.steampowered.com/api/appdetails/?appids=218620,441600&cc=US&l=english&v=1 |
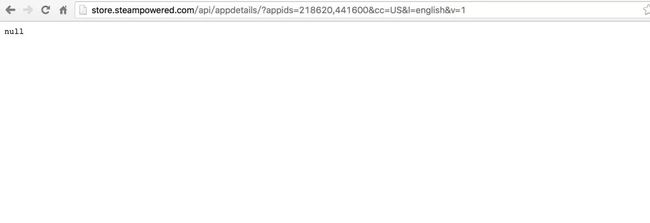
果然,返回 null。
到底是怎么回事?
再次阅读steamapiwrapper的文档,发现作者提到了一篇文章,说他用文章里的方法重构了 API,我们去看看那篇文章。
打开一看,说的就是我们这个 API 啊!往下翻,看到好多两年前的评论,再往下翻,最底部的一条评论是五个月前的,看看说了什么:

热泪盈眶!兄弟你是个好人啊!!不仅发现了这个问题,还给出了解决方法!
把&filters=price_overview加到 URL 结尾看看:
http://store.steampowered.com/api/appdetails/?appids=218620,441600&cc=US&l=english&v=1&filters=price_overview |

热泪盈眶 again!数据出来了,而且正是我们想要的价格数据!
这里做个笔记,返回的数据中currency表示货币种类,initial表示原价,final表示折扣价。哎这游戏怎么这么贵?1999 美元?打开 Steam 搜了一下,是 19.99 美元,明白了,这个数字要除以 100 才是实际价格。
科普:为什么 Steam 要乘以 100?
在很多语言中 0.1 + 0.1 都不等于 0.2,这是因为计算机本身的设计缺陷,无法准确保存浮点数(也就是小数),因此对浮点数做运算会有误差。最简单的解决办法就是把浮点数变成整数进行运算,最终需要展示时再除回小数。
如果你想了解更多浮点数内容,可以阅读逼乎上的答案。
下面继续修改代码:
def _create_url(self, appids, cc): |
再次运行,又报错了,错误提示不一样了!可喜可贺。
具体的错误提示我忘了(……),反正大概是说Game类初始化时候有问题。
看一下出错位置的代码:
for appid in page: |
这里的page是一个解析后的 JSON 内容,也就是说它是一个字典。用for循环去遍历的时候,拿到的appid是字典的键,传入Game类生成实例的时候出错了。跳过去看了一下Game类的实现代码,好麻烦,懒得改了,反正已经拿到价格数据,直接返回得了。
def _get_games_from(self, url): |
再重复一遍,page 是字典,所以要用方括号去获取内容。
测试的时候发现有时候请求成功但是data是空,所以if中加了一个判断条件。
由于返回的内容改变,我们还需要修改calTotalPrices.py里面的代码:
from steamapiwrapper.SteamGames import Games |
再次运行程序,这次没有报错,并且一直在输出价格,大功告成!
这一节写了好长,终于能结束了。
验证
代码跑通了,下面就是要检查数据是否正确。
执行:
$ python calTotalPrices.py |
一开始没问题,过了一会又报错了。
不是没问题了吗?
这时候,经验丰富的同学应该已经想到了一种可能性:API 调用频率限制。
没错,Steam 不是慈善家,API 资源不可能给你无限使用。经过一番研究,发现确实是触发了 API 的限制。一旦访问频率过快,Steam 会直接返回 null。
那么 Steam 的限制到底是多少?
Google 一番之后,发现 Steam 官方没有任何说明。聪明的网友们自己总结出几条规则:
10 秒内最多调用 10 次
5 分钟内最多调用 200 次
x 分钟内……
好了好了我明白了,总之一秒调用一次肯定没问题是吧?简单,加个sleep(1):
import time |
加完之后,经验丰富的同学应该又想到了另一个问题:要抓多久?
print len(all_ids),大概有 23000 个 id,代码中self.num = 25,每次请求查询 25 个,需要查询 23000/25 = 1000 次。每次请求睡眠一秒,那就是 1000 多秒,大概 17 分钟。再加上请求本身需要的时间,可能要几十分钟吧。
看起来也可以接受,不过还能优化吗?
仔细看代码中的注释:
def __init__(self,num=None): |
原来默认值是 150 啊,那我们就改成self.num = 150,一下快了 6 倍,好开心。
下面就来正式运行一下,看看能否拿到数据:
$ nohup python calTotalPrices.py > result & |
咦,怎么出来一个nohup?这是一个新命令,简单来说就是后台执行。这条命令把输出写到result文件中,结尾的&会让进程在后台持续运行,哪怕 ssh 断掉进程也不会中止。
然后等就可以了,什么时候程序执行完了,什么时候拿到结果。
等几分钟就跑完了,看看总价:
15031825 14903412 |
哇,真不少啊!十五万美元!
现在已经解决了我的问题,算出了总价。不过我还想做得更多,能不能让其他人也看到这个数据呢?
当然能,做个网站就可以了。
展示
现在已经拿到数据了,接下来要做的是展示数据。
我们从用户的角度来思考,他们如何查看数据?
访问一个 URL,因此需要注册一个域名
请求会发送到后端服务器,因此需要准备一个 VPS
VPS 需要处理请求,因此需要配置 Nginx
Nginx 拿到请求之后要反向代理给具体的处理者,因此需要编写一个 Node.js 程序
Node.js 程序需要返回一个页面,因此需要编写一个 HTML 页面
OK,就是这些,涉及到很多东西,但是都不难。具体实施的时候顺序稍有不同,我们一步一步说。
注册一个域名
具体教程自己 Google,一般注册域名国内去万网,国外去GoDaddy,Name。
买好域名之后,把域名解析到自己的 VPS IP 地址就可以了。
准备一个 VPS
VPS 是另一个话题,你问我资词哪个?我主要用 Linode 和阿里云。不过要注意,大陆的主机要求域名备案,不备案的域名不能解析到大陆主机。所以如果你域名没备案,去买香港或者新加坡的主机,阿里云有,UCloud 也有,很多家都有。还可以买日本和欧美主机,不过速度比较慢。
编写一个 HTML 页面
由于只需要展示数字,所以直接编写一个带占位符的简单页面就可以:
|
注意到里面有几个奇怪的东西,那些是占位符,Node.js 中会读取 Python 执行出来的结果并替换掉,用户看到的网页显示的是实际数字。
你可以根据自己的喜好调整页面样式。
编写一个 Node.js 程序
首先配置好 Node.js 环境以及 npm,不会的自行 Google。
这里用到了hapi,一个 Node.js 服务端框架,专门用来处理网络请求。还用到了pm2,你可以把它理解成一个监控程序,它会帮你监控进程是否正常运行,并在必要的时候重启进程,这样你的服务就不会轻易狗带。我喜欢 ES6,所以需要安装babel-cli
$ sudo npm install pm2 babel-cli -g |
由于babel-cli和pm2都需要执行命令行命令,所以全局安装。
下面创建 Node.js 程序:
$ touch index.js |
拷贝进去下面的代码:
#!/usr/bin/env babel-node |
再次重复,本文的代码不包含任何最佳实践,Just For Fun!
这段代码很简单,启动一个服务器监听 3003 端口,如果有请求过来,就直接读取上面的 HTML 文件,用最新的数据替换掉 HTML 中的占位符,然后返回。
配置 Nginx
在 VPS 上安装和配置 Nginx。别问我怎么安装,问 Google。
打开配置文件:
$ vim /etc/nginx/nginx.conf |
添加一段内容:
server { listen 80; server_name steamtuhao.com www.steamtuhao; # ←写你的域名 location / { proxy_pass http://127.0.0.1:3003; # ←写你的端口 proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
注意两个地方,一个是域名,一个是端口。
当然,我们还没说到域名,先往下翻,看域名那一节,搞定域名再来这里配置。
写完之后重启 Nginx:
$ service nginx restart |
看到输出[OK]就表示重启成功,配置没问题。如果不写域名这里会出错。
Burst Link!
别问我标题什么意思,反正看 Link 也能猜到,就是把各个部分连接起来。
现在已经有了:
域名
VPS
Nginx
HTML 页面
Node.js 程序
并且域名已经解析到 VPS、Nginx 已经配置好,只差最后一步,用pm2运行你的 Node.js 程序。
$ pm2 start index.js --interpreter babel-node |
由于我使用了 ES6,所以要把解释器设置成babel-node。
执行完这一步就可以了,现在用户可以访问你的 URL,请求会被发送到 VPS,VPS 上的 Nginx 接收到请求之后会转发给 Node.js 程序,这个程序会读取数字、替换占位符并返回最终的 HTML。
好了,展示部分已经搞定。下面还有最后一个任务:自动更新数据。
Final Round!
首先来修改我们的计算脚本,让它把美元总价、人民币总价、游戏和 DLC 总数以及修改日期写入finalResult文件,一个一行。
from steamapiwrapper.SteamGames import Games |
我承认上面的代码很蠢,或许下一个版本我会重构,现在嘛,Just For Fun!
分别计算美元和人民币的价格,然后输出。注意输出顺序要和前面的 Node.js 程序对应。
最后写一个 Linux 的 crontab 命令,每天半夜 12 点自动执行一遍这个程序:
$ crontab -e |
这里有个坑,注意,是写到倒数第二行,这个文件结尾必须有一个空行!如果写到最后一行无法执行。
是不是很奇怪?我个人认为这是 Linux 的一个脑残之处。执行man crontab,手册中有一行:
cron requires that each entry in a crontab end in a newline character. If the last entry in a crontab is missing the newline, cron will consider the crontab (at least partially) broken and refuse to install it. |
这句话的意思是说:最后一行必须是空行,否则最后一个任务无法执行。
没有任何解释,反正就是无法执行。难以想象,一个 21 世纪的 Linux 系统居然连空行问题都处理不了!
无论如何,一定要记住,crontab 文件结尾必须有空行。
好了,现在你已经完成了所有步骤,把域名发给你的朋友吧!
总结
早晨开始写代码,中午开始写博客,这一切都在一天之内搞定。再次重申,文章中的代码并不好,因为代码本来就不是重点,重点是这个过程带给了我很多乐趣!
我一直觉得编程和写作、绘画一样,是一种创造的过程。我喜欢编程,我可以用它实现我的各种奇思妙想,我很享受这个过程。
希望你也能享受编程。