基础网络学习
基础网络学习
- 这些net的结构是怎么样的
- 为什么要这么设计
- 这个net的优点是什么
- 还存在那些问题
AlexNet
Imagenet Classification With Deep Convolutional Neural Networks.
- paper: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- 作者:Alex Krizhevsky
网络结构

- 共有8层,其中有5个卷积层,3个全连接层
- 最后一层全连接层的输出通过一个1000维的softmax层
- 卷积核从11到5再到3不断减小,特征图也通过Pooling 在第1、2、5层折半式减少,到第5层卷积的时候,特征已经提取的比较充足,使用两个全连接层和一个softmax层输出最终的分类概率。

conv1 阶段
输入数据:227×227×3
卷积核:11×11×3;步长:4;数量(也就是输出个数):96 (向下取整)
卷积后数据:55×55×96 (原图N×N,卷积核大小n×n,卷积步长大于1为k,输出维度是(N-n+2p)/k+1)
relu1后的数据:55×55×96
Max pool1的核:3×3,步长:2 ((N-k) / s + 1 )
pool1后的数据:27×27×96
norm1:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:27×27×96
conv2 阶段
输入数据:27×27×96卷积核:5×5;步长:1;数量:256
卷积后数据:27×27×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu2后的数据:27×27×256
Max pool2的核:3×3,步长:2
Max pool2后的数据:13×13×256 ((27-3)/2+1=13 )
norm2:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:13×13×256
conv2中使用了same padding,保持了卷积后图像的宽高不缩小。
conv3 阶段
输入数据:13×13×256卷积核:3×3;步长:1;数量(也就是输出个数):384
卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu3后的数据:13×13×384
最后的输出:13×13×384
conv3层没有Max pool层和norm层
conv4 阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):384
卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu4后的数据:13×13×384
最后的输出:13×13×384
conv4层也没有Max pool层和norm层
conv5 阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):256
卷积后数据:13×13×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu5后的数据:13×13×256
Max pool5的核:3×3,步长:2
Max pool2后的数据:6×6×256 ((13-3)/2+1=6 )
最后的输出:6×6×256
conv5层有Max pool,没有norm层
fc6 阶段
输入数据:6×6×256
全连接输出:4096×1
relu6后的数据:4096×1
drop out6后数据:4096×1
最后的输出:4096×1
fc7 阶段
输入数据:4096×1
全连接输出:4096×1
relu7后的数据:4096×1
drop out7后数据:4096×1
最后的输出:4096×1
fc8阶段
输入数据:4096×1
全连接输出:1000
fc8输出一千种分类的概率。
创新点如下:
- 采用了ReLU作为激活函数:ReLU(x) = max(x, 0)
- LRN: 局部相应归一化。只对数据相邻区域做归一化处理,不改变数据的大小和维度。
- Overlappng(重叠池化):在做池化的时候,池化核的大小为n*n时,步长为k,如果K==n的时候是正常池化,k
- Dropout: 在FC6,FC7引入Dropout,以一定的概率(50%)丢弃某个神经元,不进行前向和反向的传播(保留权值)。
- 数据增强
VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition.
- pdf: https://arxiv.org/abs/1409.1556
- 作者:Karen Simonyan
网络结构

- 核心思想:在保证相同的感受野下,利用多个小卷积核替代大卷积核,不但减小了参数量,而且加深了网络结构。
- 为什么减少了参数量:例如3个步长为1的3 * 3卷积可以看成一个7*7的卷积。前者的参数量为 3 ∗ ( 3 ∗ 3 ∗ C i n ∗ C o u t ) 3*(3*3*C_{in}*C_{out}) 3∗(3∗3∗Cin∗Cout),后者的参数量为 1 ∗ ( 7 ∗ 7 ∗ C i n ∗ C o u t ) 1*(7*7*C_{in}*C_{out}) 1∗(7∗7∗Cin∗Cout).
- 为什么感受野相同:感受野指得是,与输出有关的输入图片的局部大小。5 * 5的卷积表示在输入图5 * 5的区域内滑动。先用1个3 * 3的卷积在输入图上滑动,然后再用1个3 * 3的卷积在上一张特征图上滑动,此时映射到输入图中的区域大小是5*5的,如下图:
 - 使用1 * 1的卷积来使维度保证
- 使用1 * 1的卷积来使维度保证
优缺点
- 结构简洁,整个网络中都使用了同样大小的卷积核尺寸(3 * 3),s=1和最大池化尺寸(2 * 2), s=2
- 小的卷积叠加起来要比一个大卷积核要好
- 验证了通过不断加深网络结构可以提升性能
- 消耗资源大,主要原因是来自最后的3个全连接层,而且全连接层容易过拟合。
实现细节
训练过程
- 前两个FC层有Dropout
- we initialised the first four convolutional layers and the last three fully-connected layers with the layers of net A (the intermediate layers were initialised randomly).
- 随机初始化:从均值为0,方差为0.01的正态分布中采样,bias置为0
- 数据增强:裁剪+水平翻转+RGB增强
训练集图片的尺寸
- 固定训练集输入图片尺寸的大小:S=256。S=384,此时为了加速训练,初始化权重利用256时候的。
- 多尺度训练,随机采样到[256, 512]. 加快训练速度在S=384上进行fine-tuning
测试过程
- 注意卷积的参数个数中其实是包括 C o u t C_{out} Cout个偏置项的
GoogleNet(Inception v1)
Going Deeper with Convolutions
- pdf: https://arxiv.org/abs/1409.4842
网络结构
- 用多个Inception模块串联起来。主要的作用有两个:一个是使用1 * 1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。

1*1卷积
- 在尺寸相同的感受野中叠加更多的卷积,能够提取出更丰富的特征。对于某个像素点来说1x1卷积等效于该像素点在所有特征上进行一次全连接的计算,能够提取出更强的非线性。
- 1 * 1卷积可以进行降维,降低计算的复杂度。例如下图,对于输入一组有192个特征,32 * 32大小的输入图,输出是256个32 * 32个特征图的。如果用3 * 3的卷积进行计算,需要 ( 192 ∗ 256 ∗ 3 ∗ 3 ) ∗ 32 ∗ 32 (192 * 256 * 3 * 3) * 32 * 32 (192∗256∗3∗3)∗32∗32次运算。第二种方法先利用1 * 1卷积降维到96组特征,然后再通过3 * 3卷积恢复出256组特征,共进行 ( 192 ∗ 96 ∗ 1 ∗ 1 ) ∗ 32 ∗ 32 + ( 96 ∗ 256 ∗ 3 ∗ 3 ) ∗ 32 ∗ 32 (192 * 96 * 1 * 1) * 32 * 32 + (96 * 256 * 3 * 3) * 32 * 32 (192∗96∗1∗1)∗32∗32+(96∗256∗3∗3)∗32∗32次计算,减少了一般的计算量。同时降维不会影响最终的结果,类似压缩的效果。

多个尺寸上进行卷积再聚合
对于同一个输入图,有四个分支,分别用不用尺寸的卷积进行卷积和池化,最后在特征维度上拼接到一起。
- 在多个尺度上同时进行卷积,能够提取到不同尺度的特征。
- 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
- 用多个尺寸进行特征特区,然后将相关性强的特征聚集到一起,这样效果会更好。
Inception
Rethinking the Inception Architecture for Computer Vision
- pdf: https://arxiv.org/abs/1512.00567
ResNet
Deep Residual Learning for Image Recognition
- pdf: https://arxiv.org/abs/1512.03385
网络加深后会有什么问题:
- 梯度消失和梯度爆炸(利用BN可以解决)
- 准确率下降问题(degradation problem):层级大到一定的程度,准确率就会饱和,然后迅速下降,这是由于网络过于复杂,并且训练方式难以达到收敛导致的。更深的网络一定比浅的网络效果好,因为多余的层可以看成是恒等变换。
网络结构

- 利用残差结构实现上述恒等映射:除了正常的卷积输出之外,另外有一个分支把输入直连到输出上。
- 残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。
- 注意是直接对生成的特征图进行相加
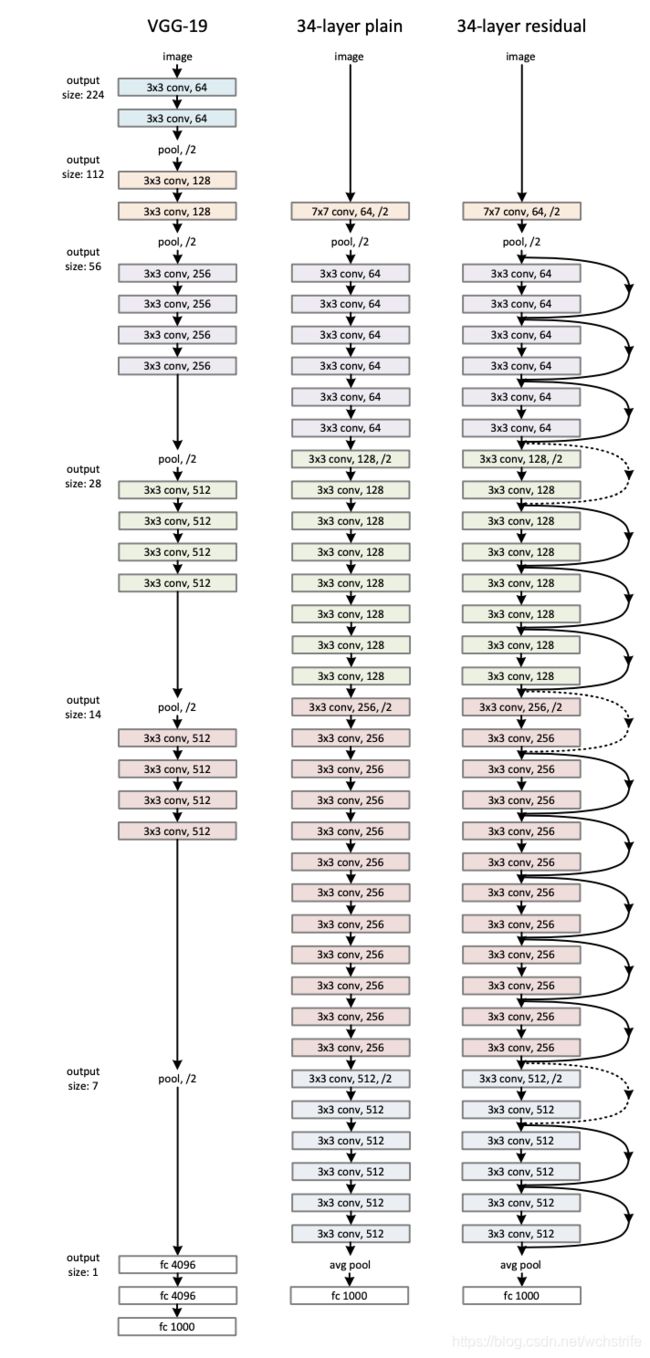
网络的基础在VGG-19上进行加深,并保持几个原则:
- 特征图大小相同的层, 卷积核的个数应该相同
- 特征图的大小如果减半,卷积核的个数应该双倍,保证复杂性
- 使用s=2的卷积进行下采样

残差模块: 当输入输出的有相同的维度的时候,可以直接进行相加。
上图虚线中,输入和输出的不一样时,采用两种方法升维:
- 少的通道用0补齐(不添加新的参数)
- 用1 * 1的卷积升维
Deeper Bottleneck Architectures
- 先使用一个1 * 1 卷积进行卷积,
- 然后使用一个3 * 3的卷积在一个小的通道数进行卷积,
- 然后再经过1 * 1 卷积进行升维。
DenseNet
Densely Connected Convolutional Networks
- pdf: https://arxiv.org/abs/1608.06993
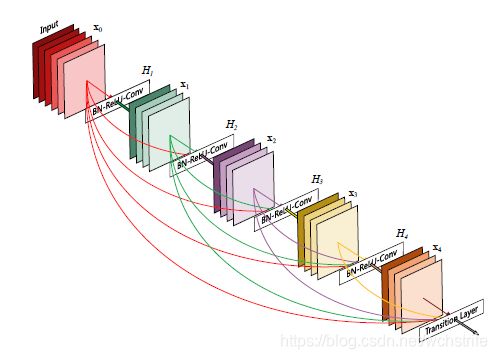
- ResNet当中卷积的输出和输入相加组合在一起,会阻碍信息流在网络中的传播
- 每一层输入的特征图都连接到后面的输入中,对于一个L层的网络共有 L ∗ ( L + 1 ) / 2 L*(L+1)/2 L∗(L+1)/2条连线
- DenseNet中某层的多个输入源不是直接算术相加,而是在特征维度上进行拼接(concatenate)
- 层与层间的直连只限于有相同尺寸的特征映射的层间,特征图尺度不同的部分不进行连接,通过卷积和Pooling改变尺寸。

- 如果在DenseNet模块中每一层的输入前都用1X1卷积降维,来减少计算量,这种结构作者取名叫DenseNet-B
- DenseNet模块中每一个卷积层前(包括1X1卷积)都会有BN,形成BN-Relu-1X1卷积-BN-Relu-3X3卷积的结构
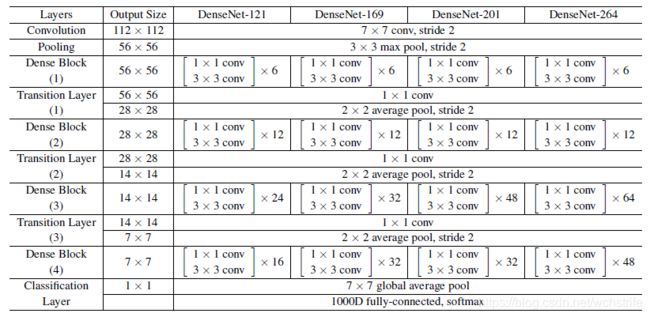
- 不同的DenseNet模块间如果也用1X1 卷积来降维,这种结构作者取名叫DenseNet-C;
优缺点
- 需要的参数少:DenseNet中某层的输出直连到之后的每一层,这些特征需要的时候不需要重新做卷积。
- 梯度能通过直连直接传到靠前的层级,减少了梯度消失的可能。
SENet
Squeeze-and-Excitation Networks
- pdf: https://arxiv.org/abs/1709.01507
核心想法:关注通道之间的关系,通过额外一个小网络,学习到不同通道特征之间的重要程度。
网络结构

- 先对卷积后的特征图进行Squeeze操作,得到通道级的全局特征。
- 对通道的全局特征进行Excitation操作,学习通道间的关系,得到不同的权重
- 权重向量乘以特征图得到最终的特征
- 这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。
- 另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
普通卷积
F t r F_{tr} Ftr, 普通卷积,输入一个通道上的特征(大小为卷积核的大小),学习特征的空间关系,但是由于对各个通道的卷积结果做了sum,所以channel特征关系与卷积核学习到的空间关系混合在一起。
SE模块就是为了抽离这种混杂在一起的关系,使模型直接学习到Channel间的关系。
Squeeze操作
- 直接通过卷积得到的U很难获得足够的信息来提取Channel之间的关系,尤其是对于前面的卷积层,感受野很小,信息更少。
- Squeeze操作,将一个Channel上整个空间特征编码为一个全局特征,例如global average pooling,即在Channel上求一个均值。

Excitation操作
- Sequeeze操作得到了全局描述特征,我们接下来需要另外一种运算来抓取channel之间的关系。
- 这个操作需要满足两个准则:首先要灵活,它要可以学习到各个channel之间的非线性关系;第二点是学习的关系不是互斥的,因为这里允许多channel特征,而不是one-hot形式。
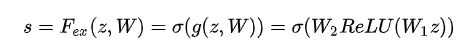

- 为了降低模型复杂度,提升泛化能力,采用两个全连接层的bottleneck结构。
- 第一个FC层是降维的作用,降维系数r是一个超参数,采用ReLU激活
- 第二个FC层恢复原始的维度,由一个sigmoid激活(0-1)
- 最后将各个channel的激活值,乘以U上的原始特征图:即学习了各个channel的权重系数,对不同的channel的重要程度进行了预测,类似attention机制

ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- pdf: https://arxiv.org/abs/1707.01083
设计理念
Convolution VS Group Convolution
分组卷积对于输入的feature map进行分组,每组分别卷积。
对于常规卷积(Convolution):
- 假如输入的feature map 尺寸为 C ∗ H ∗ W C * H * W C∗H∗W, feature map的个数为 N N N
- 卷积核的尺寸为 C ∗ K ∗ K C*K*K C∗K∗K,假设卷积输出的维度也是 N N N的话,此时参数量为 N ∗ ( C ∗ K ∗ K ) N * (C*K*K) N∗(C∗K∗K)
对于分组卷积(Group Convolution):
- 假如输入的feature map 尺寸为 C ∗ H ∗ W C * H * W C∗H∗W,输出feature map的个数为 N N N
- 设定要分成 G G G个group,则每组输入的feature map的数量为 C G \frac{C}{G} GC,每组输出feature map数量为 N G \frac{N}{G} GN
- 每个卷积核的尺寸为 C G ∗ K ∗ K \frac{C}{G} * K * K GC∗K∗K,卷积核的总数仍为 N N N个,每组的卷积核的数量为 N G \frac{N}{G} GN,卷积核只与同组的输入map进行卷积,卷积核的总参数量为 N ∗ C G ∗ K ∗ K N * \frac{C}{G} * K * K N∗GC∗K∗K。总参数量减少为原来的 1 G \frac{1}{G} G1
分组卷积(Group Convolution)的作用:
- 减少参数量:分成G组,该层的参数量比普通卷积减少为原来的 1 G \frac{1}{G} G1
- Group Convolution可以看成是Structured Sparse:每个卷积核的尺寸由 C ∗ K ∗ K C*K*K C∗K∗K变为了 C G ∗ K ∗ K \frac{C}{G} * K * K GC∗K∗K,省去的部分可以视为参数为0,在减少参数量的同时可以获得更好的效果(相当于正则化)
- 当分组数G等于输入feature map的数量的时候,输出map数量也等于出入map数量时,即 G = N = C G=N=C G=N=C时,N个卷积核每个尺寸变为 1 ∗ K ∗ K 1*K*K 1∗K∗K,相当于变成了Depthwise Convolution,参数量进一步减少。
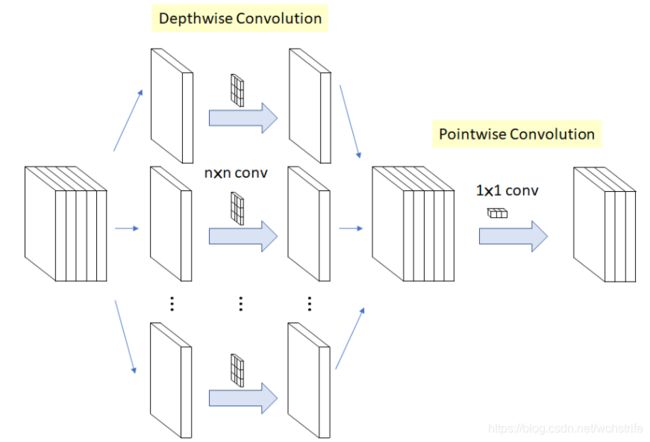 4. 更进一步,如果 G = N = C G=N=C G=N=C时,同时卷积核的尺寸与输入map的尺寸相同,即 K = H = W K=H=W K=H=W,则输出的map为 C ∗ 1 ∗ 1 C*1*1 C∗1∗1的向量,此时称之为 Global Depthwise Convolution(GDC)。可以看成是全局加权池化,与 Global Average Pooling(GAP) 的不同之处在于,GDC 给每个位置赋予了可学习的权重(对于已对齐的图像这很有效,比如人脸,中心位置和边界位置的权重自然应该不同),而GAP每个位置的权重相同,全局取个平均,如下图所示:
4. 更进一步,如果 G = N = C G=N=C G=N=C时,同时卷积核的尺寸与输入map的尺寸相同,即 K = H = W K=H=W K=H=W,则输出的map为 C ∗ 1 ∗ 1 C*1*1 C∗1∗1的向量,此时称之为 Global Depthwise Convolution(GDC)。可以看成是全局加权池化,与 Global Average Pooling(GAP) 的不同之处在于,GDC 给每个位置赋予了可学习的权重(对于已对齐的图像这很有效,比如人脸,中心位置和边界位置的权重自然应该不同),而GAP每个位置的权重相同,全局取个平均,如下图所示:

ShuffleNet 对于Group Convolution的改进
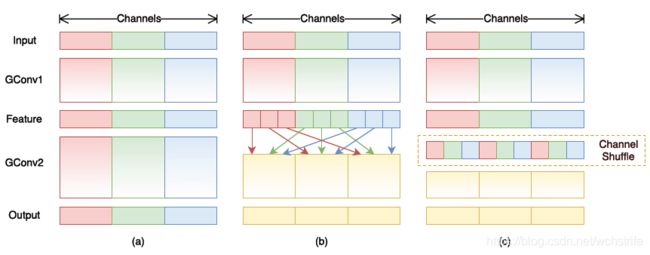
- 核心思想:对于不同的channels进行shuffle,解决group convolution带来的channel间特征图不通信的弊端。
- 一个解决的办法就是对于group convolution之后的特征图进行“重组”,保证接下来GConv2的输入来自不用的组,实现信息的交换,例如下图b
- ShuffleNet采用均匀的打乱的方式:假定输入层分为g组,总通道数为 g ∗ n g*n g∗n,首先将通道的维度拆分为 ( g , n ) (g,n) (g,n)两个维度,然后将这两个维度转置变为(n,g),最后重新reshape成一个维度。这样就实现了均匀的shuffle.
网络结构

- 基本单元在残差单元上改进:例如图a中3层的残差单元,首先是1 * 1卷积,然后是3 * 3的Depthwise Convolution(DWConv,每组只有一个特征图,降低计算量),再进行一个1 * 1卷积(Bottleneck结构),最后是一个短路链接,将输入直接接入输出中。
- 改进:将1 * 1的卷积改为Group Convolution,只在第一个GConv后跟一个channel shuffle。
- 当s=2的时候,生成的特征图形状不匹配,此时用一个avg pool,使得和输出大小一样的特征图,然后再concat到一起(降低计算量与参数大小)
整体的结构如下:

EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- pdf: https://arxiv.org/pdf/1905.11946.pdfarxiv.org