ISCA 2018 论文 部分(一)
ISCA 2018 论文 部分(一)
- ISCA 2018 论文 部分(一)
-
- 1、Division of Labor: A More Effective Approach to Prefetching
- 2、Computation Reuse in DNNs by Exploiting Input Similarity
- 3、A Hardware Accelerator for Tracing Garbage Collection
- 4、Mitigating Wordline Crosstalk using Adaptive Trees of Counters
- 5、SnaPEA: Predictive Early Activation for Reducing Computation in Deep Convolutional Neural Networks
- 6、Non-Speculative Store Coalescing in Total Store Order
- 7、Energy-efficient Neural Network Accelerator Based on Outlier-aware Low-precision Computation
- 8、SEESAW: Using Superpages to Improve VIPT Caches
- 9、Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
-
1、Division of Labor: A More Effective Approach to Prefetching
将scope和accuracy解耦合,单纯地提高scope会降低准确率,且污染Cache。
设计一种混合预取器,每一个部件只负责自己的scope(prefetch targets)
这样,将多个部件组合成为一种预取器,将提高了scope,又不会对accuracy造成太大影响。
2、Computation Reuse in DNNs by Exploiting Input Similarity
与计算有关的输入产生一些微小的变化并不会对精度造成太大影响,因此改变后这部分的计算和内存访问可以被节省。
3、A Hardware Accelerator for Tracing Garbage Collection
GC的3个trade-off:(1)高应用吞吐率;(2)高内存应用率;(3)短暂的GC延迟
一般的GC只能同时保证其中的2个
论文中试图将GC加入到硬件中(放到靠近内存控制器的硬件加速器中)
以前有这种思想但未被广泛采用,有3个原因:
(1)摩尔定律:摩尔定律意味着下一代通用处理器一定会胜过专用芯片,这为非专业处理器带来优势,但随着摩尔定律的终结,人们逐渐对加速器产生兴趣。
(2)服务器设置:从GC中收获最多的是服务器一类的,这些工作常在数据中心,而数据中心对成本非常敏感且长期由商品组件构建。而今,数据中心定制硬件数量不断增加。
(3)过于激进:许多硬件协助的GC要求重构存储器系统,而现在合并到面向存储的设备不需要激进的改变。
4、Mitigating Wordline Crosstalk using Adaptive Trees of Counters
深度缩放DRAM会导致相邻单元间的耦合增加——串扰。
DRAM中某些行的高频访问可能由于串扰而导致物理相邻行单元数据丢失。
恶意利用这种行为的攻击称为row hammering
除了蓄意攻击,某些应用不平衡的访问模式也会产生“hot”行,从而导致串扰
一种简单的解决办法是增大刷新率,但会提高能耗和性能开销。
另一种方法是检测访问频率高的row(aggressor row),刷新相邻的row。
DDR4 DRAM架构采用了TRR(Target Row Refresh)
一种简单的方法来确认aggressor row称为SCA(Static Counter Assignment)
为每一行都分配一个counter来跟踪访问情况,这会造成大量的面积和能耗浪费
且由于DRAM本身的访问存在局部性,会导致SCA中的大量counter浪费
所以提出了CAT(Counter-based Adaptive Tree)动态分配counter
5、SnaPEA: Predictive Early Activation for Reducing Computation in Deep Convolutional Neural Networks
在当前许多CNN中,计算大量卷积运算的输出被输入到激活单元,而如果输入为负,则输出为零。
利用该性质,SnaPEA可以在确定输出为负时,简化卷积运算。
SnaPEA以2中模式运行:exact、predictive
exact:无分类精度缺失,根据符号静态重排序权重,并定期对部分和进行符号位检查。
predictive:推测式地简化卷积运算,并利用多变量的优化算法控制推断程度来保证准确率。利用了一种软硬件协同方案:(1)静态预排序权重;(2)确定触发预测性早期激活的阈值;(3)使用低开销运行时的监视机制来应用早期激活。
6、Non-Speculative Store Coalescing in Total Store Order
Non-Speculative coalescing store buffer有两个问题:
(1)如何将一组合并写作为原子操作展现给内存系统
(2)如何避免死锁
为此引入一种字典序( lexicographical order)
对于TSO,由于松散了store-store序,一种重要的好处在于可以在一个Cache块合并非连续的store操作,但合并会不可更改地改变store序和影响TSO
在TSO中,即使产生了合并,store的序也必须得维护,out-of-core的推测可以维护,但对于高效的设计模式而言往往会避免out-of-core形式的推测或者不允许对存储器层次有所改变,因此需要一种非推测式的方案。
如果能保证外部的store和load的原子性,那么组内的store的序就不重要了,TSO可以得到维护。
文章的主要思路是如果无法影响程序顺序去避免死锁,那么就改变为一种无死锁的序——字典序。
对着该方案,对于每个Cacheline而言,只要有写权限或者能够获得写权限,那么该cacheline可以立刻被写,这意味着冲突的院子组能够“偷取”到权限如果该cacheline未被写,那么先得到权限的就可以先写,直到它完成后让出权限。
7、Energy-efficient Neural Network Accelerator Based on Outlier-aware Low-precision Computation
能效对于确定神经网络在服务器和移动设备中的适用性至关重要,而降低精度使提高能效的好方法。
对一些很深的神经网络来说,传统方法难以达到很低的精度(例如,4位表示)
OLAccel是基于4位的MAC单元,以不同的方式处理离群的权值和激活。
OLAccel将数据划分为2部分,低精度和高精度。
它将精度降低(例如4位表示)应用于包含大部分数据的低精度区域。
高精度区域仅包含总数据的一小部分(例如,3%),并保持原始的高精度,例如16位表示。高精度区域中的数称为“离群”值。
OLAccel为SIMD通道配备与其并行运行的异常MAC单元来减少由于离群值权重而导致的额外执行cycle数,从而减少大多数情况下离群值权重发生的延迟。
OLAccel会跳过0输入激活的计算,从而更加提高能效。
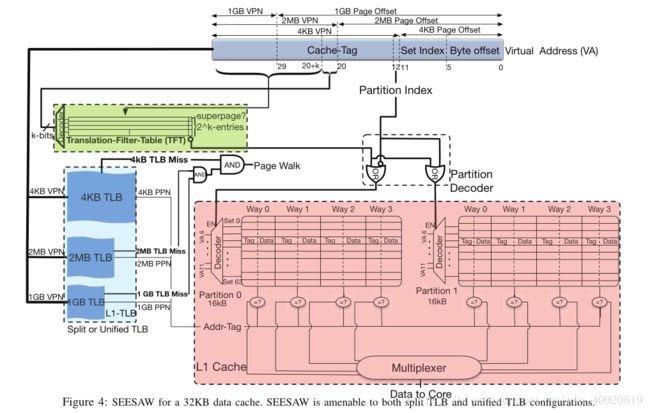
8、SEESAW: Using Superpages to Improve VIPT Caches
Cache需要平衡快速查找、高命中率、能效以及实施的简单性。
对于L1 Cache而言,经常是VIPT( virtual-indexing and physical-tagging),由于虚拟存储的约束,其难以达到该平衡。
L1 Cache需要平衡:
(1)良好性能:高命中率、低访问时间,需要平衡组数和路数,高相联度可以提高命中率,但会加大访问时间。
(2)能效性:Cache的命中、缺失、管理的能耗必须最小化。更高的相联度可以减少Cache的miss和L2和LLC的能耗,但高相联度会增大L1的查找能耗。
(3)易实施性:L1 Cache和cycle时间对于核心时序来说至关重要。必须要简单而且快速以及低的load-to-use时延。
但虚拟存储让L1 Cache难以平衡以上全部,关键问题在于虚拟存储需要虚实地址转换。
TLB可用于加速转换,但由于TLB的查找优先于Cache,这延迟了L1 Cache的访问。
于是利用VIPT来解决该问题,但VIPT的问题在于它需要cache index完全包含在page offset中。一般的页大小为4KB,也即是说页偏移只有12位,而block offset是一定的,这会限制cache中的组数。
该文章提出了一种方法SEESAW(Set-Enhanced Superpage Aware)caching,这种方法利用了超页。
SEESAW支持三种方式的cache查询:
(1)CPU在超页中查找数据,SEESAW只需查找比VIPT caches更少的路数,可以减少命中时间以及节省能耗;
(2)CPU在普通页中查找数据:SEESAW与VIPT cache相同;
(3)Coherence lookups:L1 的Coherence lookups使用物理地址,因此无需查询TLB,但由于L1的高相联度依然需要查找很多路。SEESAW支持所有的Coherence lookups,无论定位到超页还是普通页,需要查找的路更少,能很大程度减少能耗。
TLB利用3种方式和cache交互:
(1)PIPT(Physically-indexed, physically-tagged),太慢,不常用;
(2)VIVT(Virtually-indexed, virtually-tagged),可绕过TLB,但太复杂,用的不多;
(3)VIPT(Virtually-indexed, physically-tagged),常用。
9、Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
一种动态位宽的加速器,Bit Fusion,有一组位级别的处理单元阵列,该阵列可以动态组合为不同网络层所需要的位宽,能够以最合适的粒度来最小化计算量并不造成任何精度损失。
DNN有3个算法特征:
(1)DNN主要是大规模乘加计算的结合;
(2)可以减少位宽而不降低精度;
(3)为了保持精度,整个DNN的位宽变化很大,且可能每层独自调整